三个爬虫的小栗子
第一个例子 —— 京东商品的爬取案例
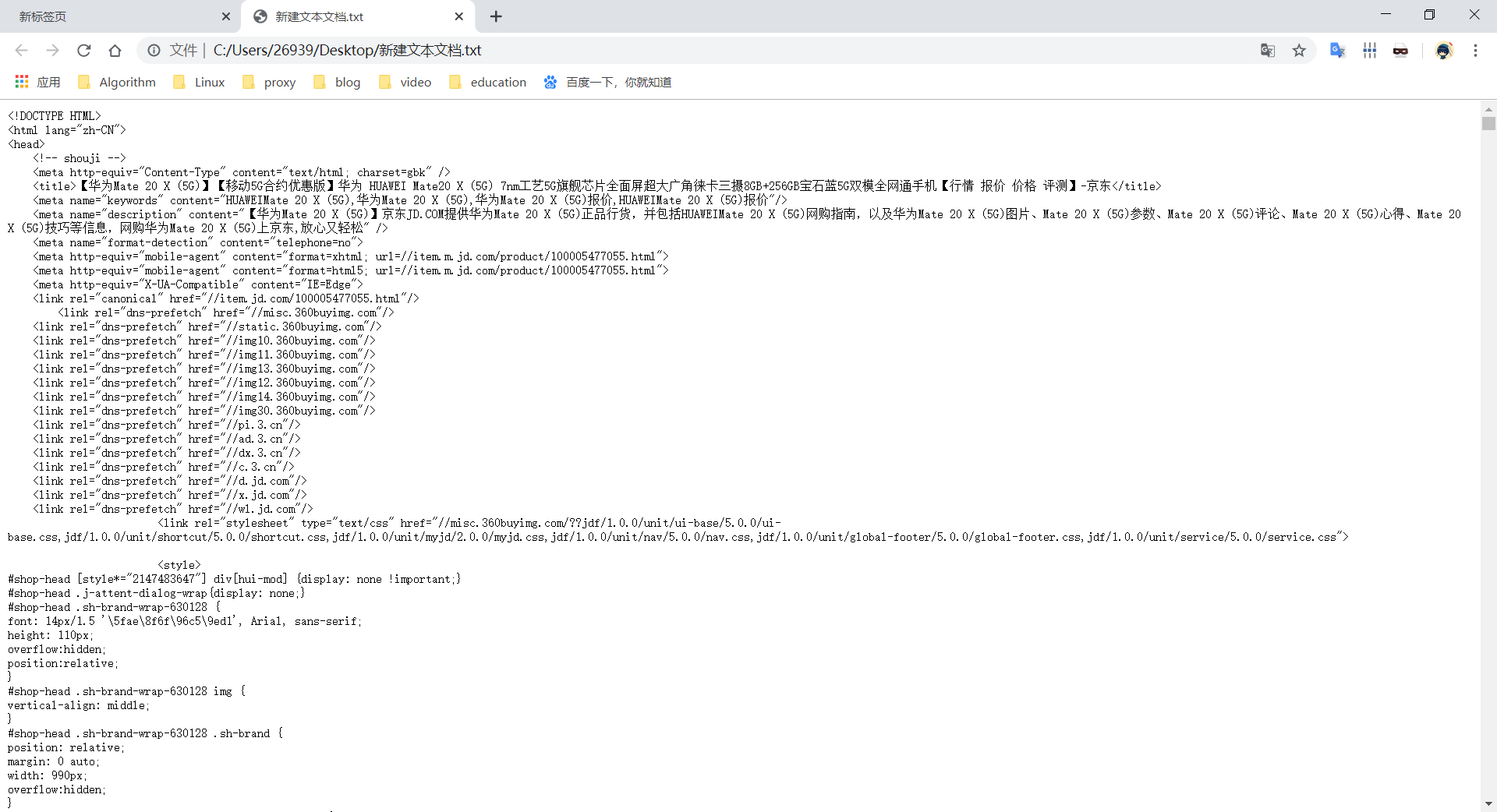
import requests def getHTMLtext(url): try: r = requests.request('get' ,url ) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return "出现异常" url = "https://item.jd.com/100005477055.html" print(getHTMLtext(url))
结果如下:
第二个例子 —— 亚马逊爬虫案例
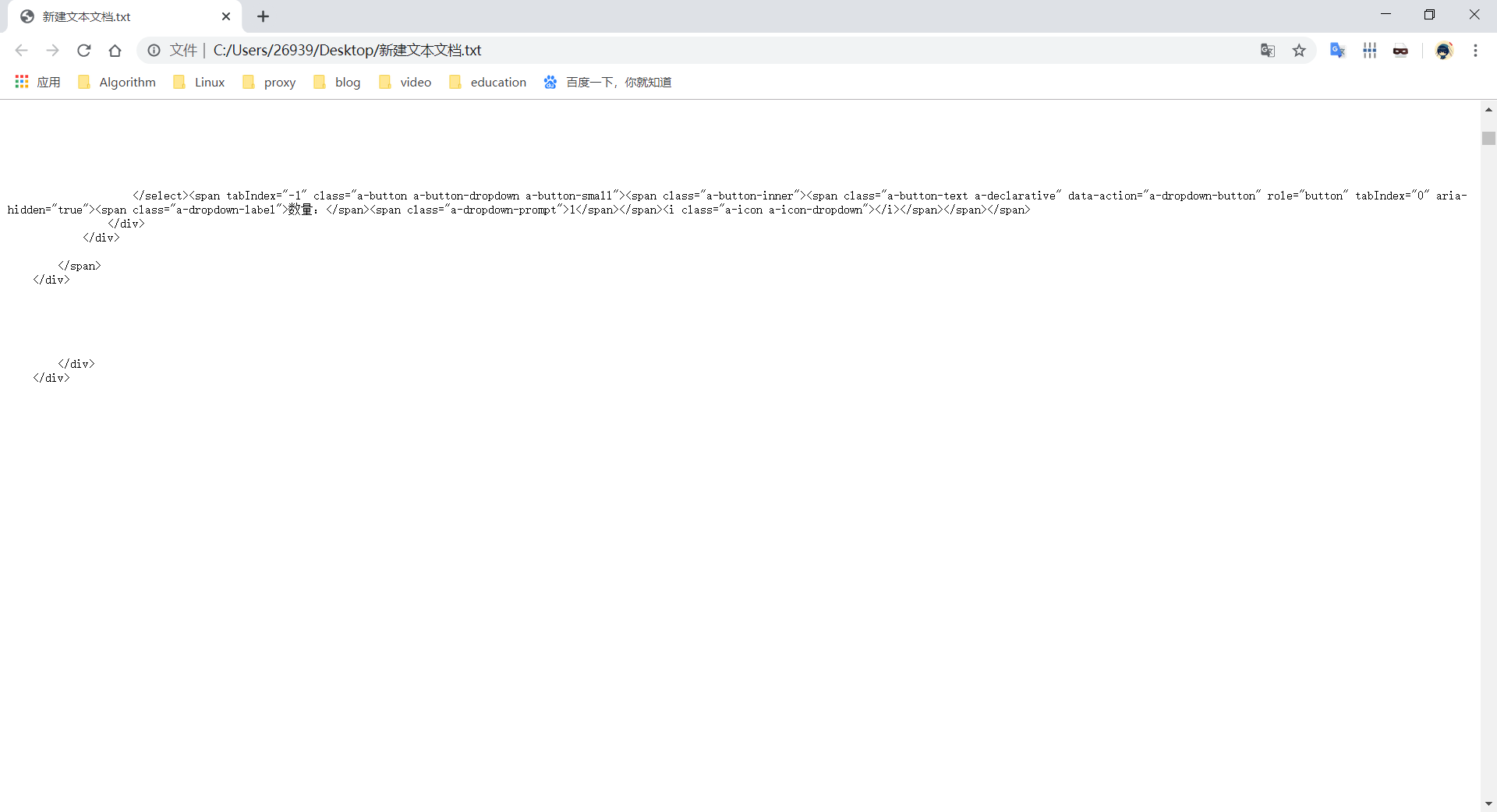
import requests url = 'https://www.amazon.cn/dp/B00RY59GJ0?ref_=Oct_DLandingSV2_PC_e9324a46_0&smid=A2EDK7H33M5FFG' r = requests.request('get',url) print(r.status_code) header = {'user-agent': 'Mozilla/5.0'} r = requests.request('get',url,headers = header) print(r.headers) print(r.status_code) print(r.text)
亚马逊的官网是反爬虫的,因此我们要将user-agent更换
第三个例子 —— 百度的post案例
首先我们要处理百度的url每次搜索百度后百度的链接就会发生变化
假如我们搜索wd https://www.baidu.com/s?wd=wd 百度的链接就会变成这样,因此我们知道百度的链接的关键词是?wd=
那么我们就可以做以下的操作
import requests def getHTMLtext(url): kd = {'wd': 'wd'} r = requests.request('get', url, params = kd ) try: r.raise_for_status() return r.text except: return "处理异常" url = "http://www.baidu.com/s?" print(getHTMLtext(url))
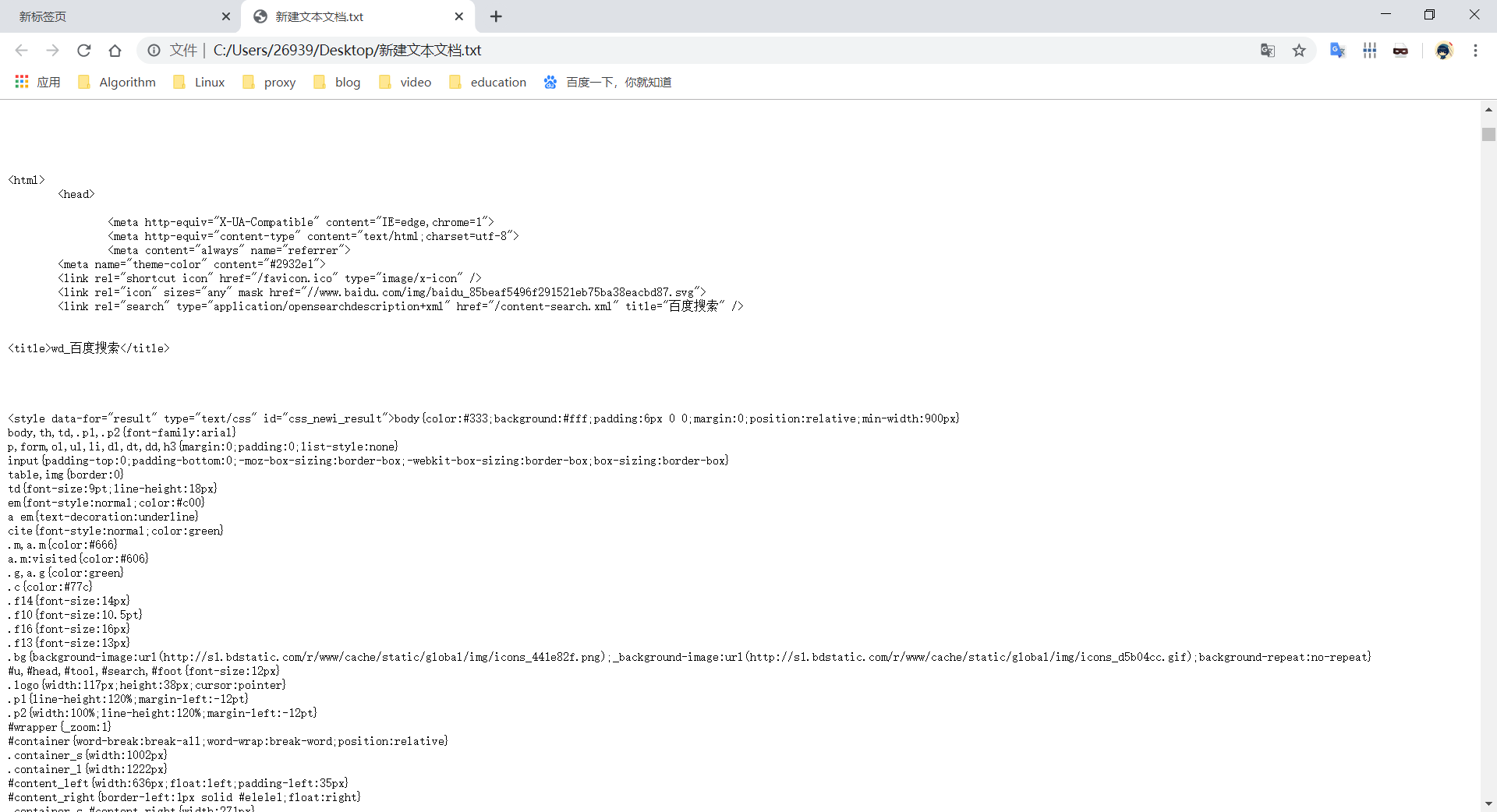
观察结果,显然我们已经实现了百度的爬取,如果想要查找其他的关键词的话,只需要改变wd=之后的关键词就行了。