IP
-
I P是T C P / I P协议族中最为核心的协议。所有的 T C P、U D P、I C M P及I G M P数据都以I P数据报格式传输。
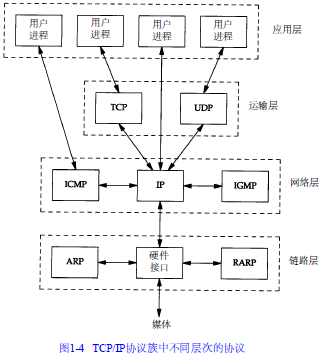
不可靠( u n r e l i a b l e)的意思是它不能保证 I P数据报能成功地到达目的地。 I P仅提供最好的传输服务。如果发生某种错误时,如某个路由器暂时用完了缓冲区, I P有一个简单的错误处理算法:丢弃该数据报,然后发送 I C M P消息报给信源端。任何要求的可靠性必须由上层来提供(如T C P)。
无连接( c o n n e c t i o n l e s s)这个术语的意思是 I P并不维护任何关于后续数据报的状态信息。每个数据报的处理是相互独立的。这也说明, I P数据报可以不按发送顺序接收。如果一信源向相同的信宿发送两个连续的数据报(先是 A,然后是B),每个数据报都是独立地进行路由选择,可能选择不同的路线,因此 B可能在A到达之前先到达。
在这里,简要介绍 I P首部中的各个字段,讨论 I P路由选择和子网的有关内容。还要介绍两个有用的命令: i f c o n f i g和n e t s t a t。
2.IP首部

4个字节的32 bit值以下面的次序传输:首先是 0〜7 bit,其次8〜15 bit,然后1 6〜23 bit,最后是24~31 bit。这种传输次序称作 big endian字节序。由于 T C P / I P首部中所有的二进制整数在网络中传输时都要求以这种次序,因此它又称作网络字节序。以其他形式存储二进制整数的机器,如 little endian格式,则必须在传输数据之前把首部转换成网络字节序。
目前的协议版本号是4,因此I P有时也称作 I P v 4。
服务类型(TOS)字段,4bit的TOS分别代表:最小时延、最大吞吐量、最高可靠性和最小费用。4 bit中只能置其中1 bit。如果所有4 bit均为0,那么就意味着是一般服务。
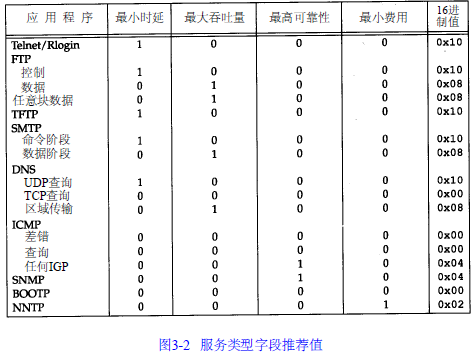
路由协议如 O S P F和I S - I S都能根据这些字段的值进行路由决策。
T T L(t i m e - t o - l i v e)生存时间字段设置了数据报可以经过的最多路由器数。它指定了数据报的生存时间。T T L的初始值由源主机设置(通常为3 2或6 4),一旦经过一个处理它的路由器,它的值就减去1。当该字段的值为 0时,数据报就被丢弃,并发送 I C M P报文通知源主机。
每一份 I P数据报都包含源 I P地址和目的 I P地址。它们都是 32 bit的值。
3.IP路由选择
从概念上说, I P路由选择是简单的,特别对于主机来说。如果目的主机与源主机直接相连(如点对点链路)或都在一个共享网络上(以太网或令牌环网),那么I P数据报就直接送到目的主机上。否则,主机把数据报发往一默认的路由器上,由路由器来转发该数据报。大多数的主机都是采用这种简单机制。
路由表中的每一项都包含下面这些信息:
目的I P地址。它既可以是一个完整的主机地址,也可以是一个网络地址,由该表目中的标志字段来指定(如下所述)。主机地址有一个非0的主机号,以指定某一特定的主机,而网络地址中的主机号为0,以指定网络中的所有主机(如以太网,令牌环网)。
下一站(或下一跳)路由器( next-hop router)的I P地址,或者有直接连接的网络 I P地址。下一站路由器是指一个在直接相连网络上的路由器,通过它可以转发数据报。下一站路由器不是最终的目的,但是它可以把传送给它的数据报转发到最终目的。
标志。其中一个标志指明目的 I P地址是网络地址还是主机地址,另一个标志指明下一站路由器是否为真正的下一站路由器,还是一个直接相连的接口。
为数据报的传输指定一个网络接口。
I P路由选择是逐跳地( h o p - b y - h o p)进行的。I P并不知道到达任何目的的完整路径(当然,除了那些与主机直接相连的目的)。所有的I P路由选择只为数据报传输提供下一站路由器的 I P地址。它假定下一站路由器比发送数据报的主机更接近目的,而且下一站路由器与该主机是直接相连的。
I P路由选择主要完成以下这些功能:
1) 搜索路由表,寻找能与目的 I P地址完全匹配的表目(网络号和主机号都要匹配)。如果找到,则把报文发送给该表目指定的下一站路由器或直接连接的网络接口(取决于标志字段的值)。
2)搜索路由表,寻找能与目的网络号相匹配的表目。如果找到,则把报文发送给该表目指定的下一站路由器或直接连接的网络接口(取决于标志字段的值)。目的网络上的所有主机都可以通过这个表目来处置。例如,一个以太网上的所有主机都是通过这种表目进行寻径的。
这种搜索网络的匹配方法必须考虑可能的子网掩码。
3)搜索路由表,寻找标为“默认( d e f a u l t)”的表目。如果找到,则把报文发送给该表目指定的下一站路由器。
如果上面这些步骤都没有成功,那么该数据报就不能被传送。如果不能传送的数据报来自本机,那么一般会向生成数据报的应用程序返回一个“主机不可达”或“网络不可达”的错误。
完整主机地址匹配在网络号匹配之前执行。只有当它们都失败后才选择默认路由。默认路由,以及下一站路由器发送的 I C M P间接报文(如果我们为数据报选择了错误的默认路由),是I P路由选择机制中功能强大的特性。
为一个网络指定一个路由器,而不必为每个主机指定一个路由器,这是 I P路由选择机制的另一个基本特性。这样做可以极大地缩小路由表的规模.
一个简单的例子:我们的主机 b s d i有一个I P数据报要发送给主机 s u n。双方都在同一个以太网上.数据报的传输过程如图.
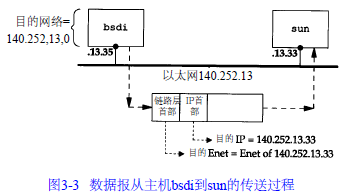
I P从某个上层收到这份数据报后,它搜索路由表,发现目的 I P地址(1 4 0 . 2 5 2 . 1 3 . 3 3)在一个直接相连的网络上(以太网 1 4 0 . 2 5 2 . 1 3 . 0)。于是,在表中找到匹配网络地址(在下一节中,我们将看到,由于以太网的子网掩码的存在,实际的网络地址是 1 4 0 . 2 5 2 . 1 3 . 3 2,但是这并不影响这里所讨论的路由选择)。
数据报被送到以太网驱动程序,然后作为一个以太网数据帧被送到 s u n主机上.I P数据报中的目的地址是s u n的I P地址( 1 4 0 . 2 5 2 . 1 3 . 3 3),而在链路层首部中的目的地址是 48 bit的s u n主机的以太网接口地址。这个 48 bit的以太目的
网地址是用 A R P协议获得的.
另一个例子:主机 b s d i有一份I P数据报要传到 f t p . u u . n e t主机上,它的I P地址是1 9 2 . 4 8 . 9 6 . 9。经过的前三个路由器如图 3 - 4所示。首先,主机b s d i搜索路由表,但是没有找到与主机地址或网络地址相匹配的表目,因此只能用默认的表目,把数据报传给下一站路由器,即主机 s u n。当数据报从 b s d i被传到 s u n主机上以后,目的 I P地址是最终的信宿机地址(1 9 2 . 4 8 . 9 6 . 9),但是链路层地址却是 s u n主机的以太网接口地址。这与图 3 - 3不同,在那里数据报中的目的I P地址和目的链路层地址都指的是相同的主机( s u n)。
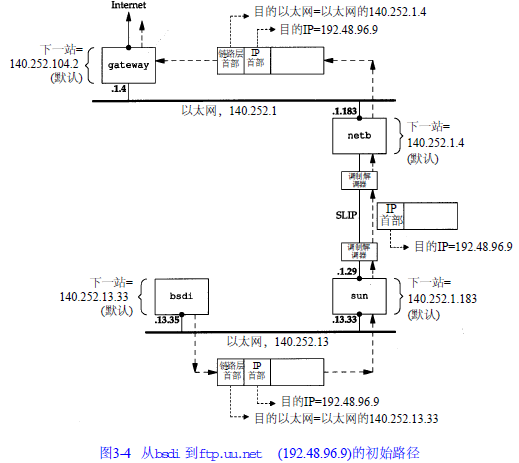
当s u n收到数据报后,它发现数据报的目的 I P地址并不是本机的任一地址,而 s u n已被设置成具有路由器的功能,因此它把数据报进行转发。经过搜索路由表,选用了默认表目。根据s u n的默认表目,它把数据报转发到下一站路由器 n e t b,该路由器的地址是 1 4 0 . 2 5 2 . 1 . 1 8 3。数据报是经过点对点 S L I P链路被传送的,采用了最小封装格式。这里,我们没有给出像以太网链路层数据帧那样的首部,因为在 S L I P链路中没有那样的首部。
当n e t b收到数据报后,它执行与s u n主机相同的步骤:数据报的目的地址不是本机地址,而n e t b也被设置成具有路由器的功能,于是它也对该数据报进行转发。采用的也是默认路由表目,把数据报送到下一站路由器 g a t e w a y(1 4 0 . 2 5 2 . 1 . 4)。位于以太网 1 4 0 . 2 5 2 . 1上的主机n e t b用A R P获得对应于 1 4 0 . 2 5 2 . 1 . 4的48 bit以太网地址。这个以太网地址就是链路层数据帧头
上的目的地址。
路由器g a t e w a y也执行与前面两个路由器相同的步骤。它的默认路由表目所指定的下一站路由器 I P地址是 1 4 0 . 2 5 2 . 1 0 4 . 2。
一些关键点:
1) 该例子中的所有主机和路由器都使用了默认路由。事实上,大多数主机和一些路由器可以用默认路由来处理任何目的,除非它在本地局域网上。
2) 数据报中的目的I P地址始终不发生任何变化。所有的路由选择决策都是基于这个目的I P地址。
3) 每个链路层可能具有不同的数据帧首部,而且链路层的目的地址(如果有的话)始终指的是下一站的链路层地址。在例子中,两个以太网封装了含有下一站以太网地址的链路层首部,但是 S L I P链路没有这样做。以太网地址一般通过 A R P获得。
4.子网寻址
现在所有的主机都要求支持子网编址。不是把I P地址看成由单纯的一个网络号和一个主机号组成,而是把主机号再分成一个子网号和一个主机号。
这样做的原因是因为 A类和B类地址为主机号分配了太多的空间,可分别容纳的主机数为22 4-2和21 6-2。事实上,在一个网络中人们并不安排这么多的主机。由于全0或全1的主机号都是无效的,因此我们把总数减去 2。
在I n t e r N I C获得某类I P网络号后,就由当地的系统管理员来进行分配,由他(或她)来决
定是否建立子网,以及分配多少比特给子网号和主机号。例如,这里有一个 B类网络地址(1 4 0 . 2 5 2),在剩下的16 bit中,8 bit用于子网号,8 bit用于主机号,格式如图 3 - 5所示。这样就允许有2 5 4个子网,每个子网可以有 2 5 4台主机。

许多管理员采用自然的划分方法,即把 B类地址中留给主机的 16 bit中的前8 bit作为子网地址,后 8 b i t作为主机号。这样用点分十进制方法表示的 I P地址就可以比较容易确定子网号。但是,并不要求A类或B类地址的子网划分都要以字节为划分界限。
子网对外部路由器来说隐藏了内部网络组织(一个校园或公司内部)的细节。在我们的网络例子中,所有的I P地址都有一个B类网络号 1 4 0 . 2 5 2。但是其中有超过3 0个子网,多于4 0 0台主机分布在这些子网中。由一台路由器提供了 I n t e r n e t的接入
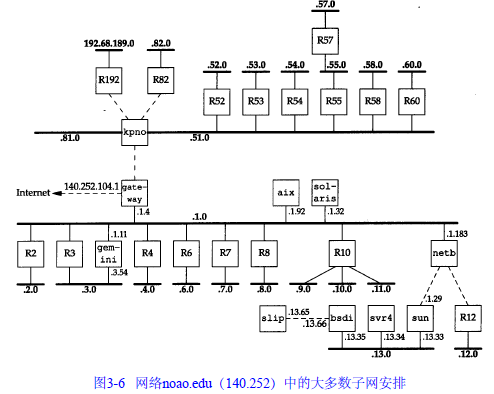
5.子网掩码
任何主机在引导时进行的部分配置是指定主机 I P地址。大多数系统把 I P地址存在一个磁盘文件里供引导时读用。
除了I P地址以外,主机还需要知道有多少比特用于子网号及多少比特用于主机号。这是在引导过程中通过子网掩码来确定的。这个掩码是一个 32 bit的值,其中值为1的比特留给网络号和子网号,为0的比特留给主机号。图 3 - 7是一个B类地址的两种不同的子网掩码格式。第一个例子是 n o a o . e d u网络采用的子网划分方法,如图 3 - 5所示,子网号和主机号都是 8 bit宽。第二个例子是一个B类地址划分成10 bit的子网号和6 bit的主机号。
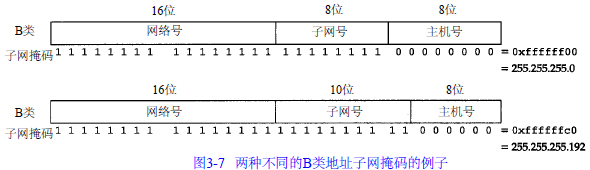
尽管I P地址一般以点分十进制方法表示,但是子网掩码却经常用十六进制来表示,特别是当界限不是一个字节时,因为子网掩码是一个比特掩码。
给定I P地址和子网掩码以后,主机就可以确定 I P数据报的目的是:
( 1)本子网上的主机;
(2)本网络中其他子网中的主机;
( 3)其他网络上的主机。
如果知道本机的 I P地址,那么就知道它是否为A类、B类或C类地址(从I P地址的高位可以得知),也就知道网络号和子网号之间的分界线。而根据子网掩码就可知道子网号与主机号之间的分界线。
举例
假设我们的主机地址是 1 4 0 . 2 5 2 . 1 . 1(一个B类地址),而子网掩码为 2 5 5 . 2 5 5 . 2 5 5 . 0(其中8 b i t为子网号,8 bit为主机号)。
• 如果目的I P地址是 1 4 0 . 2 5 2 . 4 . 5,那么我们就知道B类网络号是相同的( 1 4 0 . 2 5 2),但是子网号是不同的(1和4)。用子网掩码在两个I P地址之间的比较如图3 - 8所示。
• 如果目的 I P地址是1 4 0 . 2 5 2 . 1 . 2 2,那么B类网络号还是一样的( 1 4 0 . 2 5 2),而且子网号也是一样的(1),但是主机号是不同的。
• 如果目的I P地址是 1 9 2 . 4 3 . 2 3 5 . 6(一个C类地址),那么网络号是不同的,因而进一步的比较就不用再进行了。
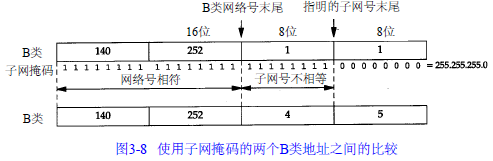
给定两个I P地址和子网掩码后,I P路由选择功能一直进行这样的比较。
6.特殊情况的IP地址
经过子网划分的描述,现在介绍 7个特殊的I P地址,如图3 - 9所示。在这个图中, 0表示所有的比特位全为0;- 1表示所有的比特位全为1;n e t i d、s u b n e t i d和h o s t i d分别表示不为全0或全1的对应字段。子网号栏为空表示该地址没有进行子网划分。

把这个表分成三个部分。表的头两项是特殊的源地址,中间项是特殊的环回地址,最后四项是广播地址。
表中的头两项,网络号为0,如主机使用B O O T P协议确定本机I P地址时只能作为初始化过程中的源地址出现。
7.一个子网的例子
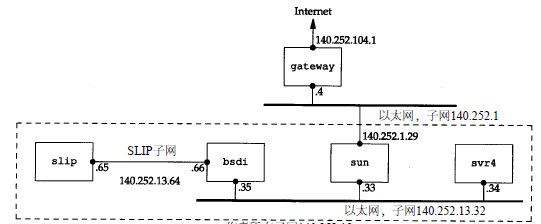
问题是我们在子网 1 3中有两个分离的网络:一个以太网和一个点对点链路(硬件连接的S L I P链路)(点对点链接始终会带来问题,因为它一般在两端都需要 I P地址)。将来或许会有更多的主机和网络,但是为了不让主机跨越不同的网络就得使用不同的子网号。我们的解决方法是把子网号从 8 bit 扩充到11 b i t,把主机号从 8 bit 减为 5 bit。这就叫作变长子网,因为1 4 0 . 2 5 2网络中的大多数子网都采用 8 bit子网掩码,而我们的子网却采用 11 bit的子网掩码。
如下图,11位子网号中的前8 bit始终是1 3。在剩下的3 bit中,我们用二进制 0 0 1表示以太网,0 1 0表示点对点 S L I P链路。这个变长子网掩码在 1 4 0 . 2 5 2网络中不会给其他主机和路由器带来问题—只要目的是子网 1 4 0 . 2 5 2 . 1 3的所有数据报都传给路由器s u n(I P地址是 1 4 0 . 2 5 2 . 1 . 2 9),如图 3 - 11所示。如果 s u n知道子网 1 3中的主机有 11 bit子网号,那么一切都好办了。
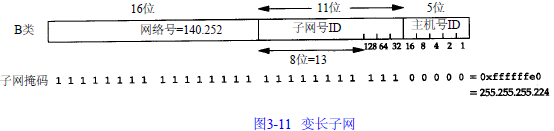
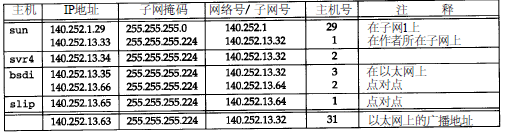
1 4 0 . 2 5 2 . 1 3子网中的所有接口的子网掩码是 2 5 5 . 2 5 5 . 2 5 5 . 2 2 4,或0 x ffffff e 0。这表明最右边的5 bit留给主机号,左边的27 bit留给网络号和子网号。
第1栏标为是“主机”,但是s u n和b s d i也具有路由器的功能,因为它们是多接口的,可以把分组数据从一个接口转发到另一个接口。
这个表中的最后一行是图 3 - 1 0中的广播地址 1 4 0 . 2 5 2 . 1 3 . 6 3:它是根据以太网子网号(1 4 0 . 2 5 2 . 1 3 . 3 2)和图3 - 11中的低5位置1(1 6+8+4+2+1=3 1)得来的。
IP的未来:
I P主要存在三个方面的问题。
1)B类地址枯竭
2) 32 bit的I P地址从长期的I n t e r n e t增长角度来看,是不够用的。
3)当前的路由结构没有层次结构,属于平面型 ( f l a t )结构,每个网络都需要一个路由表目。
来源: TCP/IP 卷一