1.需求描述
爬取豆瓣即将上映的电影信息,如下图,地址:
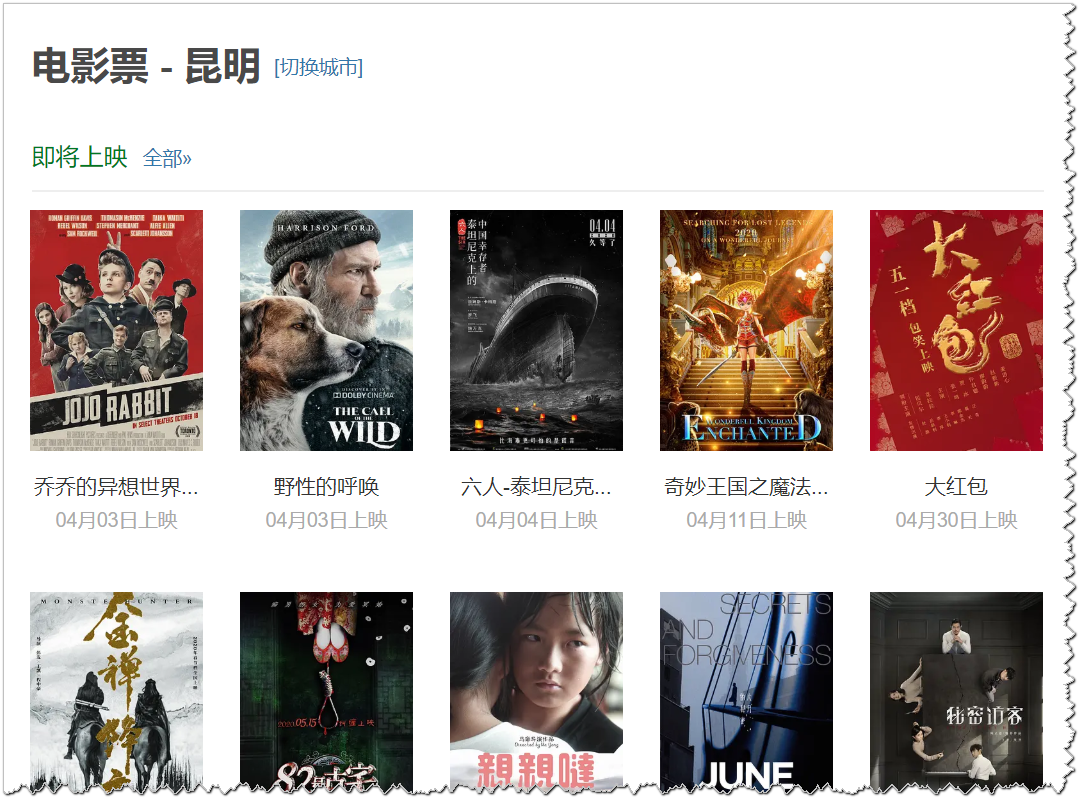
需要将每部电影的【名称、地区、时长、导演、主演】等信息爬取下来,以下是具体实现代码。
2.实现代码
# Author:Logan
# Date:2020/3/27 9:14
# IDE:PyCharm
import requests
from lxml import etree
def parse_url(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36'
}
# 发送请求
ret = requests.get(url, headers=headers)
return ret.content
def get_data(html_str):
ul = html_str.xpath("//ul[@class='lists']")[0] #第1个元素才是即将上映的ul元素
data_list = list()
for li in ul:
item = dict()
item["电影名"] = li.xpath("./@data-title")[0]
item["地区"] = li.xpath("./@data-region")[0] if len(li.xpath("./@data-region")) > 0 else None # 三目运算符
item["时长"] = li.xpath("./@data-duration")[0] if len(li.xpath("./@data-duration")) > 0 else None
item["导演"] = li.xpath("./@data-director")[0] if len(li.xpath("./@data-director")) > 0 else None
item["主演"] = li.xpath("./@data-actors")[0] if len(li.xpath("./@data-actors")) > 0 else None
data_list.append(item)
return data_list
def main():
# 解析网址
url = 'https://movie.douban.com/cinema/nowplaying/kunming/'
html = parse_url(url)
# 提取数据
html_str = etree.HTML(html)
data_list = get_data(html_str)
# 打印结果
for movie_info in data_list:
print(movie_info)
if __name__ == '__main__':
main()
代码运行结果截图:
