
子查询遵循的原则
1.子查询放在园括号中(),优先父查询被执行
2.一般无需对子查询的结果进行排序
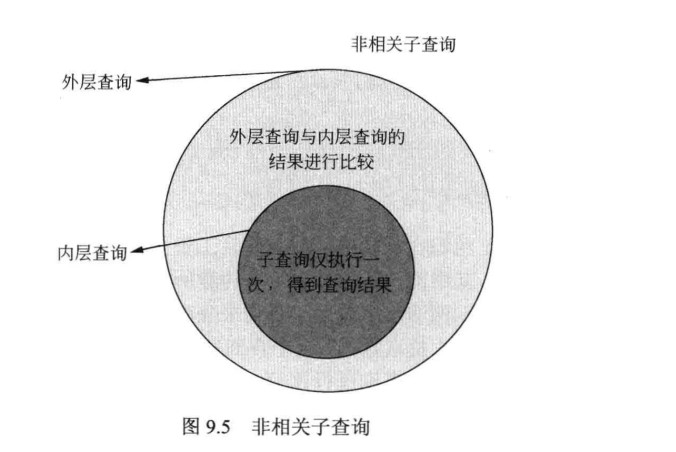
非相关子查询
子查询仅执行一次,子查询返回的结果集可以与父查询中每一行进行比较。
按返回结果划分
1. 单行单列子查询,通常与比较预算符=,>,<,!=,<=,>=联合使用来比较运算
2.多行单列子查询返回单列多行数据时,必须使用特定的关键字any,all
1 --子查询: sql语句内的另外一条select语句,也曾为内查询或内select 查询 2 --任何在 select、insert、update或delete命令中允许表达式的地方都 3 --在emp表中查询部门名称(dname)为“RESEARCH”的员工信息; 4 select empno,ename,job from emp where deptno=(select deptno from dept where dname ='RESEARCH' ); 5 --多表连接的方式 6 select empno,ename,job from emp join dept on emp.deptno=dept.deptno 7 where dept.dname='RESEARCH'; 8 --相对于多表关联查询,子查询的使用更加灵活、功能更强,而且更容易理解 9 --但是多表连接的效率要高于子查询; 10 --子查询语句 11 select deptno from dept 12 where dname ='RESEARCH' 13 --外查询语句 14 select empno,ename,job from emp; 15 --一般情况下,外查询语句检索一行,子查询语句需要检索一遍数据,然后判断外查询语句的条件是否满足。 16 --如果条件满足,将检索的数据添加的结果集中,不满足则检索下一行的数据,所以说子查询相对于关联查询要更慢一些; 17 --(1)子查询必须用括号“()”括起来。(2)子查询不能包括ORDER BY子句。(3)子查询允许嵌套多层,但不能超过255层。 18 --(1)单行子查询 (2)多行子查询(3)关联子查询 19 --单行子查询 :查询emp表中既不是最高工资,也不是最低工资的员工信息; 20 --子查询返回的行数据 21 select empno,ename,sal from emp where sal >(select min(sal) from emp) 22 and sal <(select max(sal) from emp); 23 --多行子查询:查询不是销售部 的员工信息 (in,any,all) 24 --子查询返回的是多行的数据 25 select empno,ename,job from emp where deptno in(select deptno from dept where dname <>'SALES'); 26 --查询工资大于部门编号为10 的任意一个员工即可的其他部门的员工信息 27 select deptno,ename,sal from emp where sal >any (select sal from emp where deptno =10) and deptno<>10; 28 --查询工资大于部门编号为30的所有员工的工资信息 29 select deptno,ename,sal from emp where sal>all (select sal from emp where deptno =30);

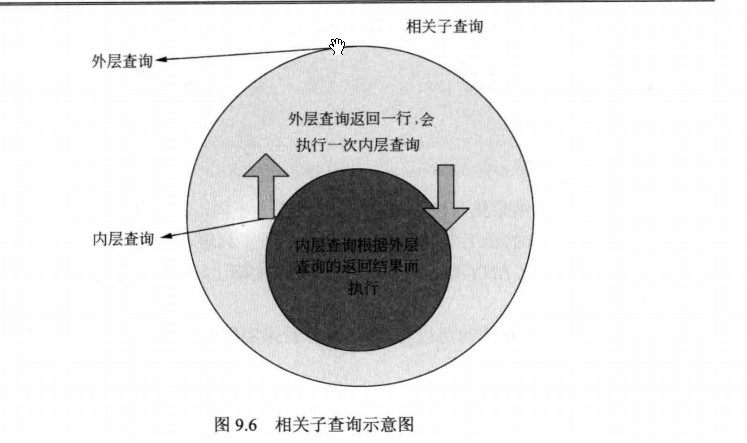
--相关子查询 当一个子查询引用了父查询中的一个或多个列时,这种查询称为相关子查询 --检索工资大于(同职位的平均工资)的员工信息 select empno,ename,sal from emp f where sal>(select avg(sal) from emp where job = f.job)order by job; oracle group by中rollup和cube的区别: Oracle的GROUP BY语句除了最基本的语法外,还支持ROLLUP和CUBE语句。如果是ROLLUP(A, B, C)的话, 首先会对(A、B、C)进行GROUP BY,然后对(A、B)进行GROUP BY,然后是(A)进行GROUP BY,最后对全表进行GROUP BY操作。 如果是GROUP BY CUBE(A, B, C),则首先会对(A、B、C)进行GROUP BY,然后依次是(A、B),(A、C),(A),(B、C),(B),(C), 最后对全表进行GROUP BY操作。