最近开始重拾golang语言的原因
golang语言c语言的运行速度,Python的开发效率。
tensorflow支持golang了,预估国内会有一些人开发深度学习软件了,会火一把,估计Google亲爹应该不会抛弃它了。
gota快要支持日期时间型了,可以实现数据清洗了。
还有一些数据挖掘的包,我还没用过,但是慢慢的会稳定。
幽灵蛛(pholcus)一套稳定的爬虫架构,支持分布式。
还差可视化包了,有谁知道好的包求推荐????????????????????????
下面步入正题,幽灵蛛入门:
怎么运行,我给大家截图一下我自己的文件结构吧,让我详细说 我也说不清楚:
golang项目中最主要的就是src文件夹了,这个文件夹是自动创建的,src上gopath里的。其中pholcus文件夹我是直接从github上下载的。

github.com文件夹截图如下:
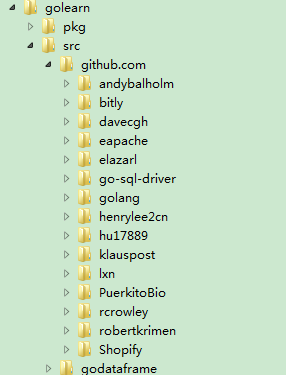
页面解析文件都放在pholcus_lib下,如果你想自己写爬虫,也是维护到这个文件夹下。

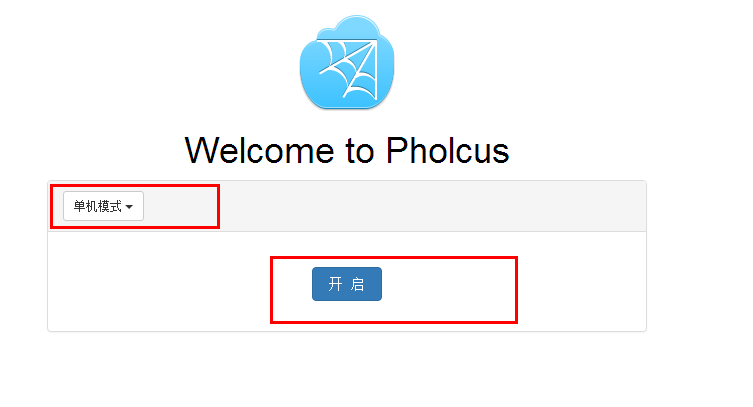
main.go文件是从example_main.go改的。编译并运行mai.go文件。浏览器自动弹出一下界面,按照截图进行设置,点击开启:
进入爬虫任务页面,按红框设置,分批输出限制100是为了可以很快的看到输出是啥样子的。

运行log:
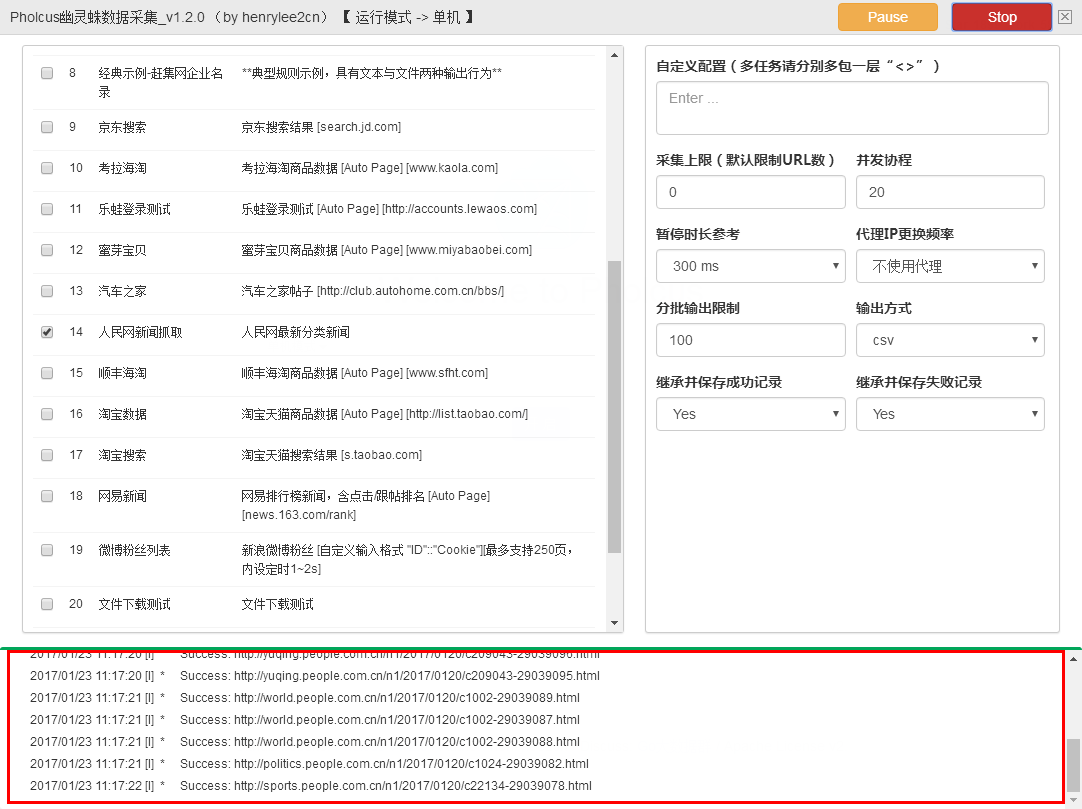
可以暂定和停止。
文本输出文件在文件夹E:projectgoprojectgolearnsrcpholcuspholcus_pkg ext_out中,如果停止后想再次进行启动进行爬取 需要先删除history:E:projectgoprojectgolearnsrcpholcuspholcus_pkghistory (也可以通过设置“集成并保存成功记录为False”)
在页面解析文件的go文件中,可以直接进行print测试,如下图:当然这种测试太麻烦了,还要启动浏览器啥的,但是目前还没找到其他的测试方式 先这么着 ,我再去探索一下,如果哪位朋友知道,请赐教????????????????????
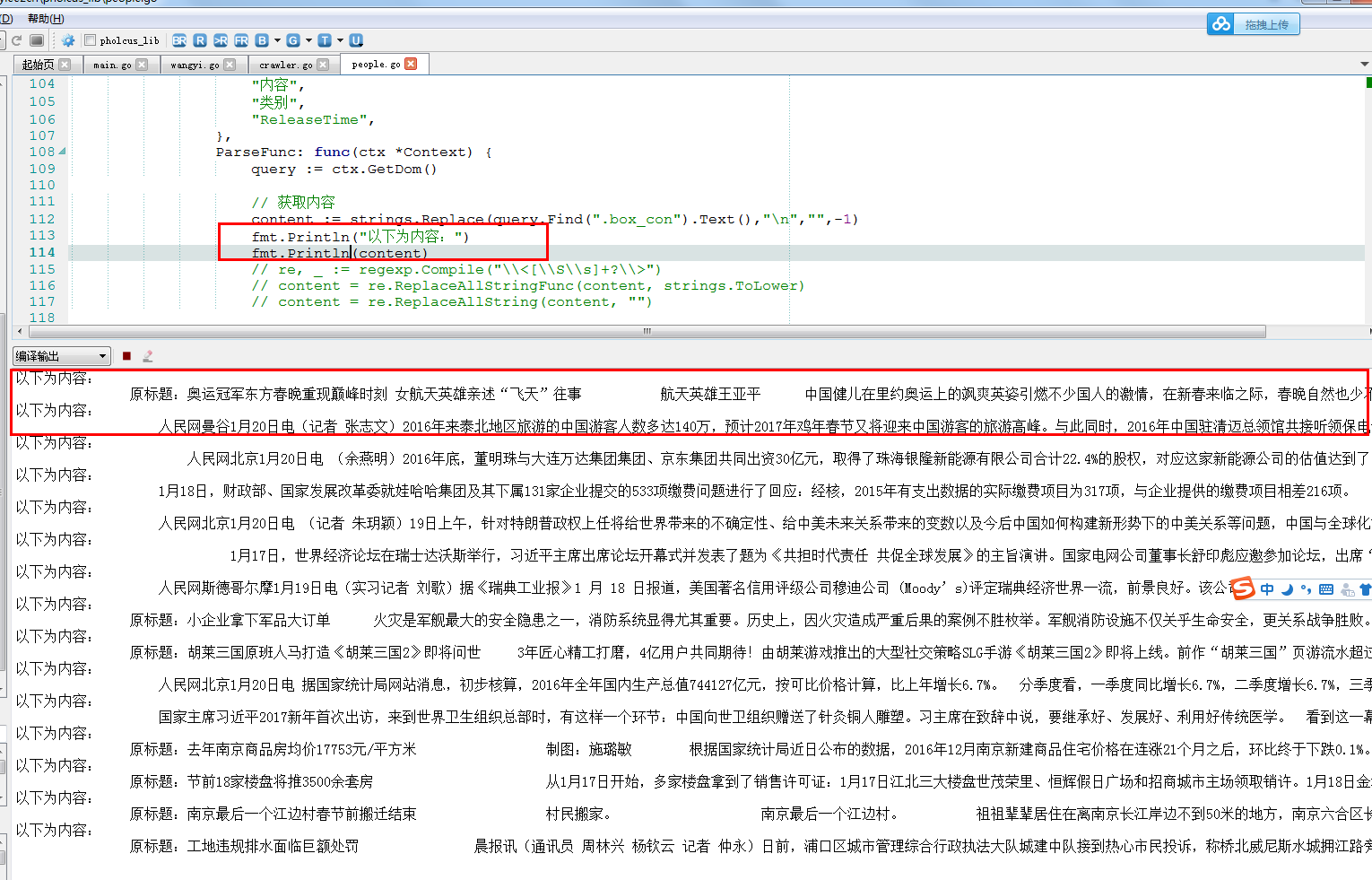
下面我们来看看输出的结果形式:
第5行的内容是空,这证明页面解析没有解析出“内容”值,可能是页面改版了,以前的元素不存在了,

csv文件,第一行是列名,对应people.go文件中的以下代码

当前链接,上级链接,下载时间 应该是系统自动添加的。
这是目前学习到的只是,杂乱无章。