1. CSV操作
1.1 pd.read_csv()
df = pd.read_csv('olympics.csv') df.head()

# index_col =0 ,从0列开始读取, 并跳过第一行 df = pd.read_csv('olympics.csv', index_col = 0, skiprows=1) df.head()

1.2 rename() 方法。
for col in df.columns: if col[:2]=='01': df.rename(columns={col:'Gold' + col[4:]}, inplace=True) if col[:2]=='02': df.rename(columns={col:'Silver' + col[4:]}, inplace=True) if col[:2]=='03': df.rename(columns={col:'Bronze' + col[4:]}, inplace=True) if col[:1]=='№': df.rename(columns={col:'#' + col[1:]}, inplace=True) df.head()
2. 查询 DataFrame
only_gold = df.where(df['Gold'] > 0) only_gold.head()

2.1 删除NAN这行
only_gold = only_gold.dropna()
only_gold.head()
drop()方法
print(df.drop(df[df['Quantity'] == 0].index).rename(columns={'Weight': 'Weight (oz.)'}))
2.3 或者直接用两次[]
only_gold = df[df['Gold'] > 0] only_gold.head() #df[(df['Gold.1'] > 0) & (df['Gold'] == 0)]
3. 索引设置
df.head()
#索引设置 df['country'] = df.index df = df.set_index('Gold') df.head()
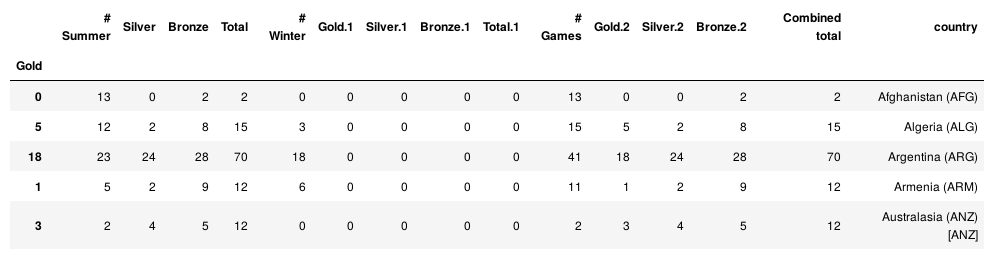
df = df.reset_index()
df.head()

3.1 unique()方法,找独一无二的元素。
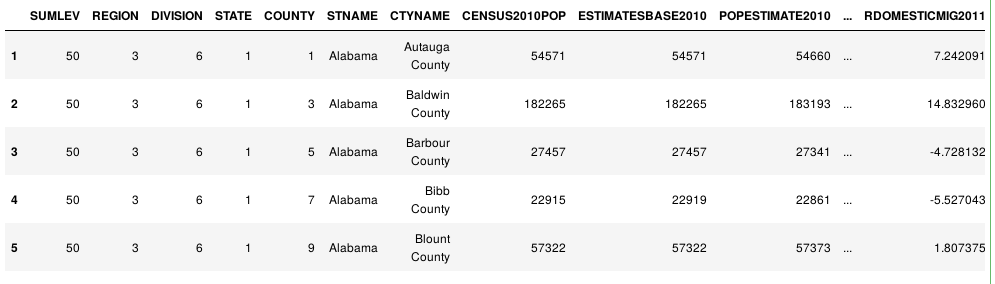
df['SUMLEV'].unique() # array([40, 50])
df=df[df['SUMLEV'] == 50] df.head()
3.2 保留指定列
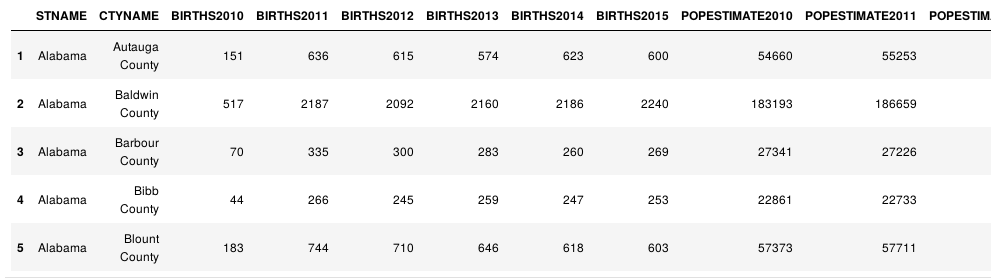
columns_to_keep = ['STNAME', 'CTYNAME', 'BIRTHS2010', 'BIRTHS2011', 'BIRTHS2012', 'BIRTHS2013', 'BIRTHS2014', 'BIRTHS2015', 'POPESTIMATE2010', 'POPESTIMATE2011', 'POPESTIMATE2012', 'POPESTIMATE2013', 'POPESTIMATE2014', 'POPESTIMATE2015'] df = df[columns_to_keep] df.head()
3.3 设置两个索引值
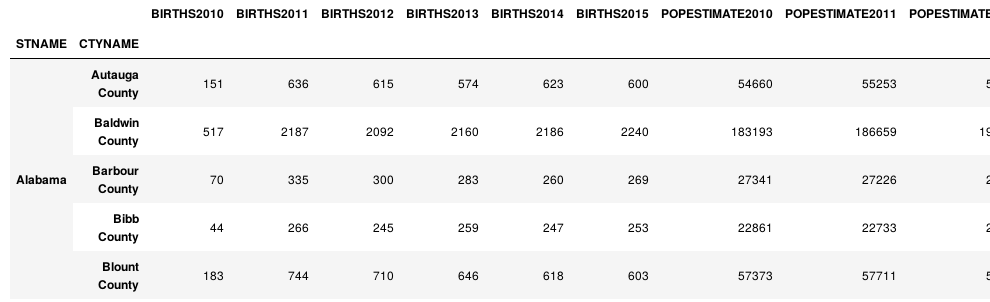
df = df.set_index(['STNAME', 'CTYNAME']) df.head()
3.4 loc()方法
df.loc['Michigan', 'Washtenaw County'] """ BIRTHS2010 977 BIRTHS2011 3826 BIRTHS2012 3780 BIRTHS2013 3662 BIRTHS2014 3683 BIRTHS2015 3709 POPESTIMATE2010 345563 POPESTIMATE2011 349048 POPESTIMATE2012 351213 POPESTIMATE2013 354289 POPESTIMATE2014 357029 POPESTIMATE2015 358880 Name: (Michigan, Washtenaw County), dtype: int64 """
df.loc[ [('Michigan', 'Washtenaw County'), ('Michigan', 'Wayne County')] ]

4. 丢失值的处理
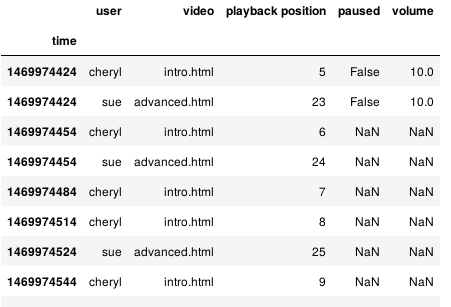
df = pd.read_csv('log.csv') df

4.1 重新设置索引
df = df.set_index('time') df = df.sort_index() df
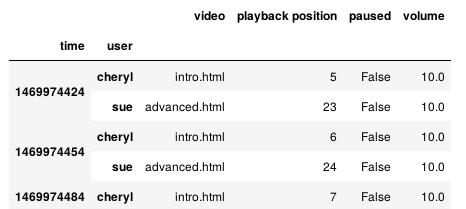
df = df.reset_index() df = df.set_index(['time', 'user']) df

4.2 向上填充fillna方法
df = df.fillna(method='ffill') df.head()
5. 返回最大值的索引
参考:http://pandas.pydata.org/pandas-docs/stable/generated/pandas.Series.argmax.html
#example >>> s = pd.Series(data=[1, None, 4, 3, 4], ... index=['A', 'B', 'C', 'D', 'E']) >>> s A 1.0 B NaN C 4.0 D 3.0 E 4.0 dtype: float64 >>> s.idxmax() 'C'