一.Redis概念
NoSQL
Not Only SQL,泛指非关系型数据库
Memcache:这是一个和Redis非常相似的数据库,但是它的数据类型没有Redis丰富。Memcache由LiveJournal的Brad Fitzpatrick开发,作为一套分布式的高速缓存系统,被许多网站使用以提升网站的访问速度,对于一些大型的、需要频繁访问数据库的网站访问速度的提升效果十分显著。
Apache Cassandra:(社区内一般简称为C*)这是一套开源分布式NoSQL数据库系统。它最初由Facebook开发,用于储存收件箱等简单格式数据,集Google BigTable的数据模型与Amazon Dynamo的完全分布式架构于一身。Facebook于2008将 Cassandra 开源,由于其良好的可扩展性和性能,被 Apple、Comcast、Instagram、Spotify、eBay、Rackspace、Netflix等知名网站所采用,成为了一种流行的分布式结构化数据存储方案。
MongoDB:是一个基于分布式文件存储、面向文档的NoSQL数据库,由C++编写,旨在为WEB应用提供可扩展的高性能数据存储解决方案。MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系型数据库的,它支持的数据结构非常松散,是一种类似json的BSON格式。
redis
Remote Dictionary Server,远程字典服务器
redis是一个开源的、使用C语言编写的、支持网络交互的、可基于内存也可持久化的Key-Value数据库(非关系性数据库)
二.Redis优点
- 速度快,因为数据存在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1)
- 支持丰富数据类型,支持string,list,set,sorted set,hash
- 支持事务,操作都是原子性,所谓的原子性就是对数据的更改要么全部执行,要么全部不执行
- 丰富的特性:可用于缓存,消息,按key设置过期时间,过期后将会自动删除
三.Redis数据类型
1.字符串(string)
常用命令
set key value
get key
exists key //key是否存在
redis会将字符串类型转换成数值;
由于INCR等指令本身就具有原子操作的特性,所以我们完全可以利用redis的INCR、INCRBY、DECR、DECRBY等指令来实现原子计数的效果
SDS结构
//简单动态字符串(Simple Dynamic String)
struct sdshdr{
int len; //buf已使用的长度
int free; //buf未使用的长度
char buf[]; //存储字符串
};
//buf数组长度 = free + len + 1 (其中1表示字符串结尾空字符'�')
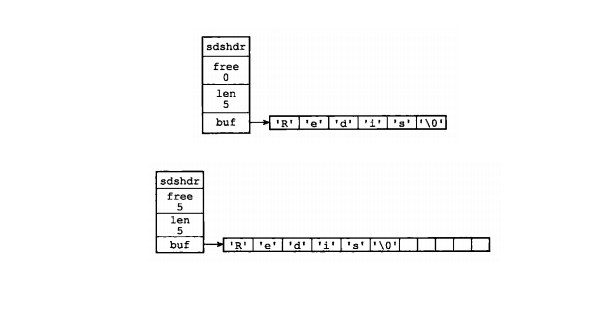
C字符串对比
| C字符串 | 简单动态字符串SDS |
|---|---|
| 获取字符串长度复杂度O(N) | 获取字符串长度复杂度O(1) |
| API不安全,存在缓冲区溢出 | API安全,不会造成缓冲区溢出 |
| 修改字符串存在多次内存分配 | 修改字符串做多需要执行N次内存重分配 |
| 只能保存文本数据 | 可以保存文本或者二进制数据(二进制安全) |
| 可以使用所有<string.h>库函数 | 只能使用一部分<string.h>库函数 |
2.哈希(hash)
常用命令
常用命令
hset hashKey key1 value1 key2 value2
hget hashkey key1
hgetall hashKey
3.集合(set)
常用命令
常用命令
sadd mySet value //向集合添加元素
smembers mySet //列出集合mySet中的所有元素
scard mySet //返回集合中元素数量
sismember mySet value //查看value是否在集合mySet中
srem mySet value //从集合mySet中删除value
sunion mySet1 mySet2 //合并多个set,返回合并后的元素列表
del mySet
4.列表(list)
常用命令
lpush list value //在list左侧(开头)插入元素
rpush list value //在list右侧(末尾)插入元素
lpop list //删除并返回列表第一个元素
rpop list //删除并返回列表最后一个元素
llen list
lrange myList 0 3 //列出mylist中从编号0到编号3的元素
lrange myList 0 -1 //列出mylist中从编号0到最后一个元素
del myList
其他
Redis列表是简单的字符串列表,按照插入顺序排序,头部是左边,尾部是右边
底层实现上就是链表,不是数组
5.有序集合(sort set)
常用命令
zadd zset1 key1 value1 //key作为value的编号来用于排序
zcard zset1 //统计zset1下key的个数
zrank zset1 value2 //查看value2在zset1中排名位置
zrange zset1 0 2 withscores //查看0到2的所有值和分数按照排名
zrange zset1 0 -1 //只查看zset中元素
其他
-
key不要太长,尽量不要超过1024字节,这不仅消耗内存,而且会降低查找的效率;
-
有序集合底层使用了 压缩链表和跳跃表:
其中跳跃表基于有序单链表,在链表的基础上,每个结点不只包含一个指针,还可能包含多个指向后继结点的指针,这样就可以跳过一些不必要的结点,从而加快查找、删除等操作。如下图就是一个跳跃表:

四.redis过期策略
1.定期删除
redis是每隔100ms随机抽取一些key来检查和删除的
2.惰性删除
在你获取某个key的时候,redis会检查是否过期,过期则删除并不返回结果
3.内存淘汰
当redis内存占用过多时,进行内存淘汰
allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key(这个是最常用的)(Least Recently Used,最近最久未使用)
五.Redis常见问题
1.击穿
概念
在Redis获取某一key时,由于key不存在,而必须向DB发起一次请求的行为
原因
第一次访问; 恶意访问不存在的key; key过期
3.规避
规避
服务器启动时,提前写入;
规范key的命名,通过中间件拦截;
对某些高频访问的key,设置合理的TTL或永不过期
2.雪崩:
1.概念
概念
Redis缓存层由于某种原因宕机后,所有的请求会涌向存储层,短时间内高并发请求可能导致存储层挂机
规避
使用Redis集群;
限流;
六.Redis协议
Redis客户端通讯协议:RESP(Redis Serialization Protocol),其特点是:
- 简单
- 解析速度快
- 可读性好
Redis集群内部通讯协议:RECP(Redis Cluster Protocol ) ,其特点是:
- 每一个node两个tcp 连接
- 一个负责client-server通讯(P: 6379)
- 一个负责node之间通讯(P: 10000 + 6379)
七.Redis面试题
1.什么是缓存雪崩?解决方法?
- redis挂了,请求全部从内存转为走数据库
- 缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至down机
解决:
- 缓存数据的过期时间错开,防止同一时间大量数据过期现象发生
- 如果缓存数据库是分布式部署,将热点数据均匀分布在不同搞得缓存数据库中
- 设置热点数据永不过期或更长合理过期时间
2.什么是缓存穿透?如何解决?
缓存穿透:
大量缓存中不存在的请求key访问直接落到数据库,一般是恶意攻击
缓存击穿:
热点key在请求高峰失效,瞬间大量请求落到数据库
解决:
①可以使用布隆过滤器(BloomFilter)或者压缩filter拦截过滤不合法的请求
②查询为空的结果也写到缓存中去(但过期时间短一点)
3.缓存与数据库双写一致
读操作先去找缓存,有则直接返回;固若没有就查询数据库,将该结果写到缓存中并返回给请求
-
先删除缓存,再更新数据库
在高并发下表现不如意,在原子性被破坏时表现优异
-
先更新数据库,再删除缓存
在高并发下表现优异,在原子性被破坏时表现不如意
4.布隆过滤器
判断一个元素是否存在一个集合中
布隆过滤器的原理是,当一个元素被加入集合时,通过K个Hash函数将这个元素映射成一个一维的bool型的数组中的K个点,把它们置为1。检索时,我们只要看看这些点是不是都是1就(大约)知道集合中有没有它了:如果这些点有任何一个0,则被检元素一定不在;如果都是1,则被检元素很可能在。这就是布隆过滤器的基本思想。
优点:新增,查询速度足够快,内存小,代码简单
缺点: 有一定误判率且随数据增加而增加; 不支持删除
大白话布隆过滤器
https://www.cnblogs.com/CodeBear/p/10911177.html
5.Redis持久化
持久化就是把内存的数据写到磁盘中去,防止服务宕机了内存数据丢失
八.参考链接
硬核!15张图解Redis为什么这么快
https://www.cnblogs.com/caoyier/p/13896319.html
linux安装redis一,超详细说明与图解!!
https://blog.csdn.net/qq_30764991/article/details/81564652
Redis中的跳跃表
https://blog.csdn.net/universe_ant/article/details/51134020
Redis源码解析:05跳跃表