Date: 2018.10.24
0、前言
本文档是MPEG-2标准的学习总结文档,主要讲述了MPEG-2标准基本知识、码流分层结构、码流的句法和语义以及视频流的解码过程,相对比较详细,可供学习标准层面的知识。
1、MPEG-2简介
MPEG组织于1994年正式推出MPEG-2压缩标准,以实现视/音频服务与应用互操作的可能性。最典型和成功的应用就是DVD产品。MPEG-2标准包括了系统层、视频层、音频层等9个部分,本文档主要讲述ISO/IEC 13818 Part2 视频部分。MPEG-2标准就是定义了一个标准的MPEG-2码流中每一位的具体含义,MPEG-2码流的结构以及视频解码的过程。
MPEG-2标准是针对标准数字电视和高清晰度电视在各种应用下的压缩方案和系统层的详细规定,编码码率从每秒3M比特~100M比特,标准的正式规范在ISO/IEC13818中。MPEG-2不是MPEG-1的简单升级,MPEG-2在系统和传送方面作了更加详细的规定和进一步的完善。MPEG-2特别适用于广播级的数字电视的编码和传送,被认定为SDTV和HDTV的编码标准。
MPEG-2图像压缩的原理是利用了图像中的两种特性:空间相关性和时间相关性。这两种相关性使得图像中存在大量的冗余信息。如果我们能将这些冗余信息去除,只保留少量非相关信息进行传输,就可以大大节省传输频带。而接收机利用这些非相关信息,按照一定的解码算法,可以在保证一定的图像质量的前提下恢复原始图像。一个好的压缩编码方案就是能够最大限度地去除图像中的冗余信息。
MPEG-2的编码图像被分为三类,分别称为I帧,P帧和B帧。 I帧图像采用帧内编码方式,即只利用了单帧图像内的空间相关性,而没有利用时间相关性。P帧和B帧图像采用帧间编码方式,即同时利用了空间和时间上的相关性。P帧图像只采用前向时间预测,可以提高压缩效率和图像质量。P帧图像中可以包含帧内编码的部分,即P帧中的每一个宏块可以是前向预测,也可以是帧内编码。B帧图像采用双向时间预测,可以大大提高压缩倍数。
2、档次和级别 (Profile && Level)
为了实现标准的语法体系的实用性(满足不同的应用),定义了Profile和Level的方式来限定有限数目的语法子集。Profile是标准中定义个完整比特流语法一个子集(偏向于功能性约束);Level是对比特流语法中各个参数进行限定的集合(偏向于参数限定)。
MPEG-2标准定义了7种Profile和4种Level,如下表所示:
(参考自:https://www.cs.rutgers.edu/~elgammal/classes/cs334/slide11_short.pdf)
其中在Main Profile中分为High,High 1440,Main和Low四种Level,具体规定如下图:


说明:
MPEG-2是向下兼容MPEG-1的,因此MPEG-2解码器可以解码满足一定条件的MPEG-1码流。
MPEG-2中的Simple,Main,SNR可分级、空域可分级和High Profile的所有level对于MPEG-1中的约束参数的比特流都是可解码的。
3、码流的分层结构
编码的视频数据由称作layer的比特流序列组成。如果仅有一层,那么这个视频流就是不可分级的视频比特流。如果有两层或多层,则称为分级的视频比特流。
MPEG-2的编码码流共分为六个层次。为更好地表示编码数据,MPEG-2用句法Syntax规定了一个层次性结构。它共分为六层,自上到下分别是:图像序列层(Video Sequence)、图像组层(GOP)、图像层(Picture)、宏块条层(Slice)、宏块层(MacroBlock)和块层(Block)。
3.1、Video Sequence 视频序列
编码的比特流中的最高语法结构就是视频序列。一个视频序列以一个序列头开始,后面可选地跟着一组图像头和一个或多个编码帧。视频序列以一个sequence_end_code终止。序列头、图像组头和图像头在视频序列中可能是重复出现的,通过重复第一个序列头的数据单元,从而使得对视频序列的随机访问成为可能。

3.2、Group of Pictures(GOP) 图像组
图像组是由一系列的编码图像组成。在编码比特流中,图像组头后面的第一个编码帧是I帧。
3.3、逐行序列和隔行序列
MPEG-2标准支持逐行编码和隔行编码。
3.4、Picture 图像
一个重构图可以通过对一个编码图的解码获得。一个编码图是由一个图像头、紧跟后面的可选扩展以及图像数据组成。一个编码图可以是一个帧图或一个场图。一个重构图可以是一个重构帧,或是一个重构帧的一个场。
MPEG-2支持三种图像类型:
- I 图 : 只使用当前帧的编码信息。
- P 图 :利用前面的I图或P图使用运动补偿预测进行编码的图。
- B 图: 利用前面的或后面的I图或P图使用运动补偿预测进行编码的图。
3.5、Slice 条带(块组)
Slice是由一系列任意数目的连续宏块组成。Slice的第一个和最后一个宏块不能是Skip块。一个Slice中至少要包含一个宏块。Slice之间不能重叠。Slice的第一个和最后一个宏块要在同一宏块水平行上。 Slice可以独立编解码,Slice的设计是为了错误恢复。
注意:Slice的句法元素最早是在MPEG-1标准中引入的,MPEG-1标准中Slice的第一个宏块和最后 一个宏块可以不在同一个宏块水平行上。但是这种设计不利于错误恢复。
3.6、Macroblock 宏块
宏块包含亮度分离和对应的色度分量。MPEG-2支持3种色度格式:4:2:0,4:2:2和4:4:4。对于4:2:0格式的图像,亮度宏块的大小为16x16,色度块的大小为8x8。一个宏块是由6个块组成的,分别是4个亮度块和2个色度块。
对于隔行扫描的图像,亮度块有2种组织方式:
(1)帧DCT编码中,每个块由两场的行交替组成;
(2)场DCT编码中,每个块仅由两场中之一个场的行组成。
所以对场DCT编码的图像中,一个亮度块解码之后,要按照隔行的方式去存放,才能恢复出原来的图像。
3.7、Block 块
块是视频编码中处理的最小单元。一般来说,DCT变换和量化的基本单元就是8x8的块。
这里块既可以指源图像数据和重构图像数据,也可以指DCT系数或相应的编码数据单元。
4、视频比特流的语法
4.1、 起始码
起始码是不会在视频中另外出现的特定位模式。
每个起始码由一个起始码前缀和跟在后面的一个起始码值组成。起始码前缀是由一串23个零值和跟在后面的一位1值组成,即“0000 0000 0000 0000 0000 00001”。
起始码值是个8bit整数,表明了起始码的类型。大部分起始码类型只有一个起始码值,而slice_start_code由许多起始码值表示,在这种情况下slice的起始码值是slice_vertical_position。
表1. MPEG-2标准定义的起始码值

4.2、 Sytax of Video Sequence
详见标准P22。包括了Sequence header、Extension and user data、Sequence extension、Sequence display extension、Sequence scalable extension和Group of pictures header的句法。
4.3、Sytax of Picture header
详见标准P27。包括了Picture coding extension、Quant matrix extension、Picture display extension和Picture temporal scalable extension、Copyright extension等句法。
4.4、Sytax of Picture data
详见标准P30。
4.5、Sytax of Slice
详见标准P32。
4.6、Sytax of Macroblock
详见标准P33。
4.7、Sytax of Block
详见标准P35。
5、视频比特流的语义
5.1 视频比特流的语法结构
图1 高层比特流组织方式

下面的语义规则适用于:
- 如果视频序列的第一个sequence_header()后面没有紧跟着sequence_extension(),那么视频流将与ISO/IEC 11172-2一致。
- 如果视频序列的第一个sequence_header()后面紧跟着一个sequence_extension(),那么后面所有出现sequence_header的后面都要紧跟一个sequence_extension()。
- sequence_extension仅紧跟在sequence_header后面。
- 如果sequence_extension在比特流中出现,那么每个picture_header后面都将紧跟一个picture_coding_extension。
- picture_coding_extension仅紧跟在picture_header后面。
- 跟在group_of_picure_header后面的第一个编码图像应该是I图像。
5.2、语义分析
详细语义参见标准P38~60。
6、视频流解码过程
视频流解码过程就是从编码码流中恢复出重建图像的过程,主要包括可变长解码VLD、反扫描、反量化、反变换IDCT和运动补偿5个过程。
简化的视频流解码流程如下图所示:

视频解码流程
6.1、高层语法结构
码流中针对宏块和所有其他语法结构中的各种参数和标志都应该按照第6小节(参考文献)的语法和语义进行解释。很多参数和标志将会影响下面的解码过程。一旦给定图像中所有宏块都解码完,整幅图像就可以重建出来了。
重构场图将成对形成重构帧。
重构帧序列需要按照6.1.1.11进行帧重排序。
如果progressive_sequence ==1,则重构帧将以帧周期为时间间隔从解码过程输出。如果progressive_sequence ==0,则重构帧将被分成一个重构场的序列,在解码过程中,以由规律的场周期为时间间隔出现。
6.2、可变长解码VLD(Variable length decoding)
可变长解码的过程实质上是将编码码流中的VLC码按照一定的语法规则转化成一维残差系数QFS[n]。
(1)帧内块DC系数(DC coefficient(n=0))
dct_dc = dct_dc_pred[cc] + dct_dc_diff ; 其中dct_dc_pred[cc]为DC系数预测值, dct_dc_diff为DC系数差分值。
- 1)差分值dct_dc_diff的确定
帧内宏块中块的DC系数按照标准中附录II-B的表II-B-12和II-B-13所定义的变长码进行编码,并指明dct_dc_size。如果dct_dc_size等于0,则当前帧内块的DC系数就等于DC系数的预测值;否则,后面要跟着一个固定长度码(以dct_dc_size为位数的dc_dct_differential)。这个DC系数差分值首先从编码的数据中恢复出来,然后加上预测值就可以恢复出最终的解码系数。 - 2)预测值dct_dc_pred[cc]的确定
有三个DC系数的预测器,每个颜色分量一个。每次对帧内宏块中的块的DC系数进行解码时,将预测值与差分值相加来恢复实际的DC系数值。然后预测器的值被设置为刚刚解码的系数值。在下面描述的不同时刻,预测器的值需要被重置。- 在一个Slice的开始;
- 当解码的宏块是非帧内宏块时;
- 当解码的宏块时Skip块,即当macroblock_address_increment > 1时。
复位值的确定通过参数intra_dc_precision按下表确定:

-
3)Intra块DC系数值QFS[0]的计算:
- 4)范围限定
比特流中有一个规定,QFS[0]必须在以下范围内取值:
0~((2^(8 + intra_dc_precision)) - 1)
- 4)范围限定

(2)其他系数(AC系数(n>0)和非帧内块的DC系数)
除了帧内DC系数外的其他系数都采用标准中表B.14,B.15和B.16进行编码。
-
1)所有变长码首先都要使用表B.14或表B.15来解码,解码值指明了采用下面三种行动中的哪一种。
-
块结束。此时块中再没有别的系数,块中剩余的系数应被置为0。采用句法"End of block"表示 。
-
正常系数。解码得到的run和level值的后面紧跟一个bit的s值,s给出了这个系数的符号。run个系数应该设置为0,剩余系数应该设置为signed_level。
if (s ==0)
signed_level = level;
else
signed_level = (-level); -
Escape编码系数。其中run和signed_level采用定长编码,具体见 4)Escape编码。
-
-
2)码表选择
下表指明了DCT系数的解码将用到哪个表。
-
3)非帧内块DC系数的解码
对于非帧内块的第一个系数的解码,需要将表B.14按照表下面的Note2和Note3所指示的那样进行修改。这个修改仅影响了表示run=0,level=+/-1的表项。
(此处有疑问? Note 3 & Note 4)

理解:对于非帧内块DC系数的解码,如果第一个系数为run=0,level=+/-1的情况,则VLC码位1s;如果其他系数为run=0,level=+/-1的情况,则VLC编码为11s。
部分DCT系数表如下图表所示:

- 4)Escape编码
很多可能的run和level值的组合并没有变长码来表示它们。为了编码这些统计上很少出现的组合, 采用了Escape编码方法。
Escape编码方法:
Escape VLC采用6位的固定长度码来表示run,紧跟12位的固定长度码表示signed_level,表B.16中定义了紧跟ESCAPE码后的run和level的固定长度编码方法。
- 5) 其余系数解码的小结
在其余系数解码开始,对于帧内块n=1,对于非帧内块,n=0。


6.3、反扫描 Inverse scan
以QFS[n]表示变长码解码器输出端的数据,n在0~63的区间内。
反扫描的过程就是将一维数据QFS[n]转换成二维系数矩阵QF[v][u],其中u和v均在区间0~7中。反扫描的块大小为8x8。
MPEG-2标准定义了2个扫描模板。将要采用的扫描模板通过编码在picture_coding_extension中的句法alternate_scan来确定。
下面图7-2和图7-3分别是2种扫描模板:
图7-2为alternate_scan为0的情况,是常用的zig_zag扫描顺序。
图7-3为alternae_scan位1的情况,是垂直交替扫描方式,与MPEG-4标准中的垂直交替扫描方式一样。


反扫描过程等效于下面过程:

6.3.1 加载矩阵的反扫描
当量化矩阵被加载时,它们以一种扫描顺序在比特流中编码,被转化成反量化器中使用的二维矩阵,就像系数使用的方法一样。
对于矩阵加载,通常采用zigzag扫描方式,即图7-2中的扫描方式。
以W[w][u]][v]表示反量化器中的加权矩阵,W[w][n]表示码流中编码的矩阵。则加载矩阵等效于下面过程:

6.4 反量化 Inverse quantisation
二维系数矩阵QF[v][u]通过反量化生成重构DCT系数 F[v][u]。这个过程本质上是乘以量化步长。量化步长可以通过2种方式进行修改:
- 通过权重矩阵改变一个块的量化步长;
- 使用尺度因子在很少几个比特的花费下(和编码整个全新矩阵相比)改变量化步长。
下图7-4描述了反量化的整个过程。通过适当的反量化算法得到系数F’’[v][u]后,经饱和运算得到了F’[v][u],最后进行了错误匹配控制操作,得到最终的重建DCT系数F[v][u]。

1)帧内DC系数的反量化
F’’[0][0] = intra_dc_mult * QF[0][0]
在帧内块中,F’’[0][0]通过一个常数因子与QF[0][0]相乘而得到,这个常数因子intra_dc_mult既不会被加权矩阵修改,也不会被比例因子修改。常数因子的值与编码在码中的picure_coding_extension的参数intra_dc_precision有关,具体关系如下表所示:

2)其他系数
除了帧内块DC系数以外的其他系数的反量化在这一节中进行讲述。
- 权重矩阵
当使用4:2:0格式时,要用到两个加权矩阵。一个用于帧内宏块,另一个用于非帧内宏块。当使用4:2:2或4:4:4格式数据时,用到4个矩阵,允许亮度和色度数据分别使用不同矩阵。每个矩阵都有一套缺省值,但可以通过加载用户定义的矩阵而被重写。
以W[w][v][u]表示加权矩阵,其中w取值为0~3,表明正在使用哪一个矩阵。表7-5总结了选择w的规则。

- 量化比例因子
量化比例因子被编码成5bit的固定长度码,即quantiser_scale_code。这个值表示用于反量化算法中适当的quantiser_scale值。
q_scale_type(编码在picture_coding_extension中)表明了应该使用哪一种quantiser_scale_code与quantiser_scale之间的对应映射关系。具体关系如下表7-6所示:

- 重构公式
下面的公式表示从QF[v][u]重建得到F’’[v][u]的算法(针对除了帧内DC系数外的其他系数):

这就是MPEG反量化方法。在MPEG-4标准中采用了2种反量化方法,分别是MPEG反量化方法和H263反量化方法。 - 饱和 Saturation
反量化得到的系数要饱和到[-2048, +2047]之间,因此,饱和满足如下公式:

- 错误匹配控制 Mismatch control
错误匹配控制可以使用和下面等效的过程。首先对块中所有重建的饱和系数F’[v][u]求和,然后判断这个值是奇数还是偶数。如果它是偶数,那么系数F[7][7]将要被修正。


3) 反量化小结
反量化过程为任何与下面在数字结果相等价的过程:

6.5 反变换 IDCT
一旦DCT系数F[v][u]被重构,那么就可以用反DCT变换获得反变换值f[y][x],这些值要被饱和到 [-256, 255]。
6.5.1 兼容IDCT的说明
NxN的二维DCT计算公式如下所示:

数学上实数IDCT定义如下:
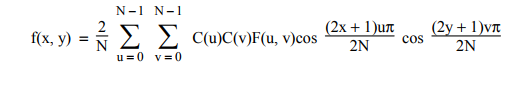
整数IDCT定义如下:
f '(x, y) = round(f(x, y)) ,其中round是取整函数,取整到最相近的整数,中间值取整到远离0的值。
饱和的整数IDCT定义如下:
f "(x, y) = saturate(f '(x, y))
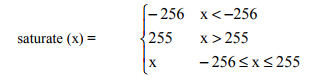
只要满足标准附录A中的4个要求,解码过程中使用的IDCT函数f[y][x]可以等于饱和的整数IDCT f "(x, y)的多个近似值。
6.5.2 非编码块和跳过宏块
在一个非跳过宏块中,针对宏块中的特定块,如果pattern_code[i]等于1,那么码流中含有这个块的残差数据,这将使用前面章节所述的方法进行解码。否则,如果pattern_code[i]等于0或者当前宏块是Skip块,那么这个块不包含残差数据。因此这种块像素域系数f[y][x]都将取零值(即非编码块和跳过宏块的残差为0)。
6.6 运动补偿 Motion compensation
运动补偿过程是利用前面解码的图像形成预测,然后与残差系数数据(IDCT过程的输出)结合恢复出最终解码图像。前面6.2~6.5过程都是在讲述残差数据的解码过程,本小节重点讲述预测图像的建立过程,即基于插值的运动补偿过程。
图7-5表示这个过程的简化流程图。

通常,对于每个块最多可以形成4种独立的预测,组合起来形成最终的预测块p[y][x]。
- 对于帧内编码宏块,没有预测,因而p[y][x]为0。
- 对于不编码的宏块,则可能是由于整个宏块都是Skip块,或者是由于这个不编码的块没有残差系数。在这种情况下,f[y][x]为0,解码样本仅为预测值p[y][x]。
6.6.1 预测方式 Prediction modes
预测方式主要有2种:场预测和帧预测。
在场预测中,通过使用一个或多个以前解码场中的数据,每个场都可以独立的进行预测。帧预测由一个或多个以前的解码帧形成帧的预测。
注意:
(1)用来产生预测的这些场和帧本身是可以按照场图或帧图进行解码的。
(2)在一个场图中,所有预测都是场预测。而在帧图中,既可能用到场预测,也可能用到帧预测(在宏块基础上选择)。
除了场预测和帧预测这两种模式,还使用到两种特殊的预测模式:
-
16x8运动补偿
这种模式仅用于场图。其中,每个宏块使用两个运动矢量,第一个运动矢量用于上面的16x8区域,第二个运动矢量用于下面的16x8区域。对于双向预测宏块,总共要用到四个运动矢量,两个用于前向预测,两个用于后向预测。 -
双基 dual-prime
这种模式仅用于在参考场(帧)与被预测场(帧)之间没有B图的P图。其中,在比特流中,仅有一个运动向量和一个小的差分运动向量被编码。
对于场图,从这个信息中可以得到两个运动向量,它们用于分别从两个参考场(一个顶场,一个底场)中形成预测,之后被平均来形成最终的预测?
对于帧图,两个场都重复这一过程,因此总共进行4个场预测。 -
换个角度小结一下
从前向预测和后向预测的角度来看预测方式:- 前向预测
对于帧图像,预测方式有帧预测、场预测和双基预测;
对于场图像,预测方式有场预测、16x8运动补偿和双基预测。 - 后向预测
对于帧图像,预测方式有帧预测和场预测;
对于场图像,预测方式有场预测和16x8运动补偿。
因此,只有双基预测方式,既可以用于帧图像,也可以用于场图像。
- 前向预测
6.6.2 参考帧(场)的选择
- 场预测
P图的场预测:
在P图中,采用最近解码的两个解码场进行预测。
有如下几种情况:
1)对帧图进行场预测或者对编码帧的一个场图(顶场)进行预测:
如下图7-6所示:

注意:
1.参考场本身可能由两个场图或者单个帧图重构而成;
2.在对一个场图进行预测是,被预测的场既可以是顶场,也可以是底场。
2)对编码帧的第二个场图进行预测:
要用到两个最近被解码的参考场,其中最近一个参考场要通过对这个编码帧的第一个场图解码得到。
如下图7-7表示第二个场图为底场的情形。(此处有疑问?)

图7-8表示当第二个场图为顶场的情形。

B图的场预测:
在B图中,场预测应该由最近重构的两个参考帧的两场进行预测。如下图所示:

注意: 参考帧本身可能是由两个场图或者一个单一的帧图像重构而成。
- 帧预测
对于P图,利用最近重构的参考帧进行预测,如下图7-10所示。

注意:
- MPEG-2只支持单参考帧预测,一般是最近重构的前一帧(对于P帧)。MPEG-4中的P帧也支持单参考帧预测,到H264才支持多参考帧。
- 参考帧本身可能是由两个场图或者一个单一的帧图像重构而成。
对于B图,帧预测通过两个最近的重构参考帧进行,如图7-11所示:

6.6.3 运动向量
为了减少表示运动向量所需要的bit数,运动向量根据前一个运动向量进行差分编码。为了解码运动矢量,解码器必须保持4个运动矢量预测器PMV[r][s][t]。对于每个预测,先得到一个运动向量 vector’[r][s][t],然后根据采样格式(4:2:0或4:2:2或4:4:4)对其进行改变,为每个颜色分量给出一个运动向量vector[r][s][t]。这个数组中维数的含义如图表7-7所示:

-
运动向量解码
每个运动向量分量vector’[r][s][t]都应该按照与下面等价的过程进行计算。并且运动矢量预测器也应按照这个过程进行修改。

-
运动向量限制
在帧图中,场运动向量的垂直分量应该受到限制,以使它们仅覆盖与那些运动向量相关的f_code所支持范围的一半。这个限制保证了运动向量预测器对于解码后续帧运动矢量能够具有合适的值。限制如表7-8所示:

-
更新和复位运动矢量预测器
复位运动矢量预测器:
当宏块中所有运动向量解码完之后,有时需要修改一些运动向量预测器。这是因为在一些预测模式中,可能会使用少于最大可能数目的运动向量。
运动向量预测器应按表7-9和表7-10所示进行修改。
复位运动矢量预测器:
在下列情况下,所有的运动矢量预测器都将被复位为零。- 在每个slice的开始;
- 当没有隐藏运动矢量的帧内宏块被解码时;
- 在P图中,当macroblock_motion_forward为零的非帧内宏块被解码时;
- 在P图中,当一个宏块被跳过时。
-
P帧的预测
在P帧中,如果macroblock_motion_forward为0并且macroblock_intra为零,则这个宏块没有运动矢量编码,然后必然形成预测。运动矢量为(0, 0)。此时运动矢量预测器应该被复位为0。 -
色度分量的运动矢量确定
前面章节所计算的运动矢量都是针对亮度分量: vector[r][s][t] = vector’[r][s][t] (for all r, s and t)
对于每个色度分量,运动矢量按照如下方式进行改变:
4:2:0 运动矢量的水平和垂直分量都除以2
vector[r][s][0] = vector’[r][s][0] / 2;
vector[r][s][1] = vector’[r][s][1] / 2;
4:2:2 运动矢量的水平分量除以2,垂直分量不变
vector[r][s][0] = vector’[r][s][0] / 2;
vector[r][s][1] = vector’[r][s][1];
4:4:4 不修改运动矢量
vector[r][s][0] = vector’[r][s][0];
vector[r][s][1] = vector’[r][s][1]; -
隐藏的运动矢量
隐藏的运动矢量是帧内宏块中所带的运动矢量,是为了数据错误阻碍了系数解码时来掩盖错误引入的。当且仅当concealment_motion_vectors(在picuture_coding_extension中)的值为1时,在所有帧内宏块中均会出现隐藏的运动矢量。
隐藏运动矢量是用于由于数据错误而导致信息丢失的情况。 -
双基附加算法
双基附加算法详见标准P77(7.6.3.6 Dual prime additional algorithm)。
6.6.4 形成预测
预测通过从参考帧或场中读取预测像素而形成。一个给定样本通过读取参考帧或参考场由运动矢量指明的相应样本而被预测。
所有运动矢量被规定为半像素精度。半像素的情况通过简单的线性插值获得。
预测过程如下:


6.6.5 跳过宏块
跳过宏块(Skip宏块)表示没有数据被编码,跳过宏块是编码的slice的一部分。
对于Skip宏块,预测值等于重构值。
除了在一个slice的开始,如果number(macroblock_address - previous_macroblock_address -1)大于1,则表示需要跳过number个宏块的编码。
其中在P图和B图中对跳过宏块的处理不同,并且对于帧和场的处理也不同。
- P场图
- 按照field_motion_type为基于场的方式进行预测;
- 参考场应该为与当前场具有相同奇偶性的场;
- 运动矢量预测器应该被复位为0;
- 运动矢量应为0。
- P帧图
- 按照frame_motion_type为基于帧的方式进行预测;
- 运动矢量预测器应复位为0;
- 运动矢量应为0。
- B场图
- 按照field_motion_type为基于场的方式进行预测;
- 参考场应该为与当前场具有相同奇偶性的场;
- 预测方向(前向、后向或双向)应该与前一个宏块相同 。
- 运动矢量预测器不受影响。
- 运动矢量通过合适的运动矢量预测器得到。色度分量的运动矢量的改变按照标准7.6.3.7所述。
- B帧图
- 按照frame_motion_type为基于帧的方式进行预测;
- 预测方向(前向、后向或双向)应该与前一个宏块相同;
- 运动矢量预测器不受影响
- 运动矢量通过合适的运动矢量预测器得到。色度分量的运动矢量的改变按照标准7.6.3.7所述。
6.6.6 组合预测
最后的步骤是将各种预测组合到一块,以形成最终的预测块。
将这些数据按场或帧的方式组织到块中,并且使其可以直接加到解码系数上。
变换系数是以场组织方式还是以帧组织方式是由dct_type决定的。
-
简单帧预测
对于简单的帧预测来说,所需要做的进一步处理就是将B图中的前向预测和后向预测求平均。
如果pel_pred_forward[y][x]是前向预测样本,且pel_pred_backward[y][x]是对应的后向预测样本,则最终的预测样本应如下形成:

对于4:2:0格式、4:2:2格式和4:4:4格式的色度分量预测,对应块尺寸应分别为8x8,16x8和16x8。 -
简单场预测
对于简单的场预测来说,所需要做的进一步处理仅是将B图中前向和后向预测求平均。这将按照上一节中帧预测那样实现。- 对于帧图像中的简单场预测,每个场中的4:2:0格式、4:2:2格式和4:4:4格式的色度分量的块尺寸应分别4x8,8x8和16x8。
- 对于场图像中的简单场预测,每个场中4:2:0格式、4:2:2格式和4:4:4格式的色度分量的块尺寸应分别8x8,16x8和16x16。
-
16x8运动补偿
在这种预测模式中,宏块的上边16x8区域和下边16x8区域会分别形成预测。
对于每个16x8区域的色度分量的预测,4:2:0格式、4:2:2格式和4:4:4格式对应的块尺寸分别为4x8,8x8和8x16。 -
双基预测
在双基模式中,对于每个场都形成预测,采用与B图中的后向和前向预测的方式。如果pel_pred_same_parity[y][x]是由相同奇偶性场中得到的预测样本,pel_opposite_parity[y][x]是由相反奇偶性场中得到的样本,则最终的预测样本按照如下公式形成:

- 对于帧图中的双基预测,对于每个场中4:2:0格式、4:2:2格式和4:4:4格式的色度分量预测,对应的块尺寸应分别为8x4,8x8和16x8。
- 对于场图中的双基预测,对于每个场中:2:0格式、4:2:2格式和4:4:4格式的色度分量预测,对应的块尺寸应分别8x8,16x8和16x16。
6.6.7 预测和残差数据求和
预测块得到之后 ,并按照与变换数据块所用的帧/场结构相匹配的方式重组为预测像素块p[y][x]。
变换数据块f[y][x]加上预测数据块并饱和后形成最终的解码样本d[y][x],如下所示:

6.7 可分级编码
MPEG-2标准支持空域分级、时域分级、SNR分级和数据分割四种基本可分级方式。
下面进行简单介绍,详细解码过程可以参见标准7.7~7.11节。
- 空域分级扩展
主要用于电信、视频标准交替、视频数据库浏览、HDTV和TV交替等应用中,即我们需要一个至少有两个空间分辨率层次的视频系统。空域分级包括从一个视频源中产生两个空间分辨率的视频层。这样,低层自己编码来提供基本的空间分辨率;增强层利用这个空域插值的低层来生成输入视频源的全分辨率。 - 时域分级扩展
时域分级扩展主要用于与从电信到HDTV的不同视频应用中,对它们来说,从低时域分辨率到高时域分辨率的转变是必要的。时域可分级将视频帧分割成层,这样,低层自身编码提供基本的时域分辨率,而增强层通过对低层进行时域预测编码,最后通过对这些层解码和时域多路复合来产生视频源的全时域分辨率。 - SNR可分级扩展
SNR可分级主要用于电信、多质量视频服务、TV和HDTV的应用中,即我们需要一个至少有两个视频质量层的视频系统。 SNR分级包括从一个视频源中产生两个具有相同的空间分辨率和不同的视频质量的视频层,其中,低层自己编码来提供基本的视频质量,而增强层被编码来增强低层。当把增强层加回到低层时,将会重新产生输入视频的一个高质量的重构。 - 数据分割扩展
在ATM网络、陆上广播等应用中,我们可以有两个通道供视频流进行存储和传送,这种情况下可以用到数据分割。在这两个通道间比特流被分割,这样,比特流中的重要部分(比如头信息、运动矢量、DC系数)可以在错误率低的通道中传送,而不重要的部分(比如DCT系数)可以在较差的信道中传送。这样,可以将信道错误造成的损失降到最小。
7、参考文献
https://www.itu.int/rec/dologin_pub.asp?lang=e&id=T-REC-H.262-200002-S!!PDF-E&type=itemshttp://ecee.colorado.edu/~ecen5653/ecen5653/papers/iso13818-2.pdf