在 Flink 1.10 中SQL正式生产,在尝试使用的时候,遇到了这样的问题: KafkaTableSink 的 'update-mode' 只支持 ‘append’,如下面这样:
CREATE TABLE user_log_sink ( user_id VARCHAR, item_id VARCHAR, category_id VARCHAR, behavior VARCHAR, ts TIMESTAMP(3) ) WITH ( 'connector.type' = 'kafka', 'connector.version' = 'universal', 'connector.topic' = 'user_behavior_sink', 'connector.properties.zookeeper.connect' = 'venn:2181', 'connector.properties.bootstrap.servers' = 'venn:9092', 'update-mode' = 'append', # 仅支持 append 'format.type' = 'json' );
看起来好像没问题,因为kafka 也只能往里面写数据,不能删数据
官网链接:https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/table/connect.html#kafka-connector
但是,如果在SQL中使用到了group 就不行了,如下:
SELECT item_id, category_id, behavior, max(ts), min(proctime), max(proctime), count(user_id) FROM user_log group by item_id, category_id, behavior;
报错如下:
Exception in thread "main" org.apache.flink.table.api.TableException: AppendStreamTableSink requires that Table has only insert changes.
之前一个同学在社区问这个问题,得到的建议是用 DataStream 转一下。
大概看了下 KafkaTableSink 的源码,有这样的继承关系,从 AppendStreamTableSink 继承下来的
public class KafkaTableSink extends KafkaTableSinkBase public abstract class KafkaTableSinkBase implements AppendStreamTableSink<Row>
group by (非窗口的)语句是 以 key 撤回的,需要用 RetractStreamTableSink 或 UpsertStreamTableSink 。
public interface RetractStreamTableSink<T> extends StreamTableSink<Tuple2<Boolean, T>> public interface UpsertStreamTableSink<T> extends StreamTableSink<Tuple2<Boolean, T>>
注:RetractStreamTableSink 一般在Flink 内部使用,UpsertStreamTableSink 适合于连接外部存储系统。
到这里,不能将 group by 的结果直接用 KafkaTableSink 的原因已经找到了,接下来就自己实现一个 KafkaUpsertTableSink,就可以解决我们的问题了。
参考如下类,实现了自定义的 KafkaUpsertTableSink:
KafkaTableSink
KafkaTableSinkBase
KafkaTableSourceSinkFactory
KafkaTableSourceSinkFactoryBase
KafkaValidator
和
HBaseUpsertTableSink
Elasticsearch7UpsertTableSink
Elasticsearch7UpsertTableSinkFactory
参考上一篇翻译:【翻译】Flink Table API & SQL 自定义 Source & Sink
直接把Kafka的一套copy出来修改:
MyKafkaValidator 直接copy KafkaValidator ,修改 connector_type 和 update-mode 检验的代码:
public static final String CONNECTOR_TYPE_VALUE_KAFKA = "myKafka"; @Override public void validate(DescriptorProperties properties) { super.validate(properties); properties.validateEnumValues(UPDATE_MODE, true, Collections.singletonList(UPDATE_MODE_VALUE_UPSERT)); properties.validateValue(CONNECTOR_TYPE, CONNECTOR_TYPE_VALUE_KAFKA, false); properties.validateString(CONNECTOR_TOPIC, false, 1, Integer.MAX_VALUE); validateStartupMode(properties); validateKafkaProperties(properties); validateSinkPartitioner(properties); }
KafkaUpsertTableSinkBase 改为继承 UpsertStreamTableSink:
public abstract class KafkaUpsertTableSinkBase implements UpsertStreamTableSink<Row>
修改对应 consumeDataStream 方法的实现: 将 DataStream<Tuple2<Boolean, Row>> 转成 DataStream< Row>,让 kafka 接收
public DataStreamSink<?> consumeDataStream(DataStream<Tuple2<Boolean, Row>> dataStream) { final SinkFunction<Row> kafkaProducer = createKafkaProducer( topic, properties, serializationSchema, partitioner); // update by venn return dataStream .flatMap(new FlatMapFunction<Tuple2<Boolean, Row>, Row>() { @Override public void flatMap(Tuple2<Boolean, Row> element, Collector<Row> out) throws Exception { // true is upsert, false is delete,这里false 的直接丢弃了 if (element.f0) { out.collect(element.f1); } else { //System.out.println("KafkaUpsertTableSinkBase : retract stream f0 will be false"); } } }) .addSink(kafkaProducer) .setParallelism(dataStream.getParallelism()) .name(TableConnectorUtils.generateRuntimeName(this.getClass(), getFieldNames())); }
KafakUpsertTableSink 继承 KafkaUpsertTableSinkBase:
public class KafkaUpsertTableSink extends KafkaUpsertTableSinkBase
修改对应实现:
@Override public TypeInformation<Row> getRecordType() { return TypeInformation.of(Row.class); }
KafkaUpsertTableSourceSinkFactoryBase 和 KafkaTableSourceSinkFactoryBase 一样实现 : StreamTableSourceFactory<Row>, StreamTableSinkFactory<Row>
public abstract class KafkaUpsertTableSourceSinkFactoryBase implements StreamTableSourceFactory<Row>, StreamTableSinkFactory<Row>
KafkaUpsertTableSourceSinkFactory 继承 KafkaUpsertTableSourceSinkFactoryBase:
public class KafkaUpsertTableSourceSinkFactory extends KafkaUpsertTableSourceSinkFactoryBase
注意:将代码中用到 KafkaValidator 改为 MyKafkaValidator
最后一个很重要的步骤是在 resource 目录下添加文件夹 META_INF/services,并创建文件 org.apache.flink.table.factories.TableFactory,在文件中写上新建的 Factory 类:
TableFactory允许从基于字符串的属性创建与表相关的不同实例。 调用所有可用的工厂以匹配给定的属性集和相应的工厂类。
工厂利用 Java’s Service Provider Interfaces(SPI)进行发现。 这意味着每个依赖项和JAR文件都应在 META_INF/services 资源目录中包含一个文件org.apache.flink.table.factories.TableFactory,该文件列出了它提供的所有可用表工厂。
注:不加不会加载新的工厂方法
好了,代码改完了试下效果:
---sourceTable CREATE TABLE user_log( user_id VARCHAR, item_id VARCHAR, category_id VARCHAR, behavior VARCHAR, ts TIMESTAMP(3), proctime as PROCTIME() ) WITH ( 'connector.type' = 'kafka', 'connector.version' = 'universal', 'connector.topic' = 'user_behavior', 'connector.properties.zookeeper.connect' = 'venn:2181', 'connector.properties.bootstrap.servers' = 'venn:9092', 'connector.startup-mode' = 'earliest-offset', 'format.type' = 'json' ); ---sinkTable CREATE TABLE user_log_sink ( item_id VARCHAR , category_id VARCHAR , behavior VARCHAR , max_tx TIMESTAMP(3), min_prc TIMESTAMP(3), max_prc TIMESTAMP(3), coun BIGINT ) WITH ( 'connector.type' = 'myKafka', 'connector.version' = 'universal', 'connector.topic' = 'user_behavior_sink', 'connector.properties.zookeeper.connect' = 'venn:2181', 'connector.properties.bootstrap.servers' = 'venn:9092', 'update-mode' = 'upsert', 'format.type' = 'json' ); ---insert INSERT INTO user_log_sink SELECT item_id, category_id, behavior, max(ts), min(proctime), max(proctime), count(user_id) FROM user_log group by item_id, category_id, behavior;
执行图如下:
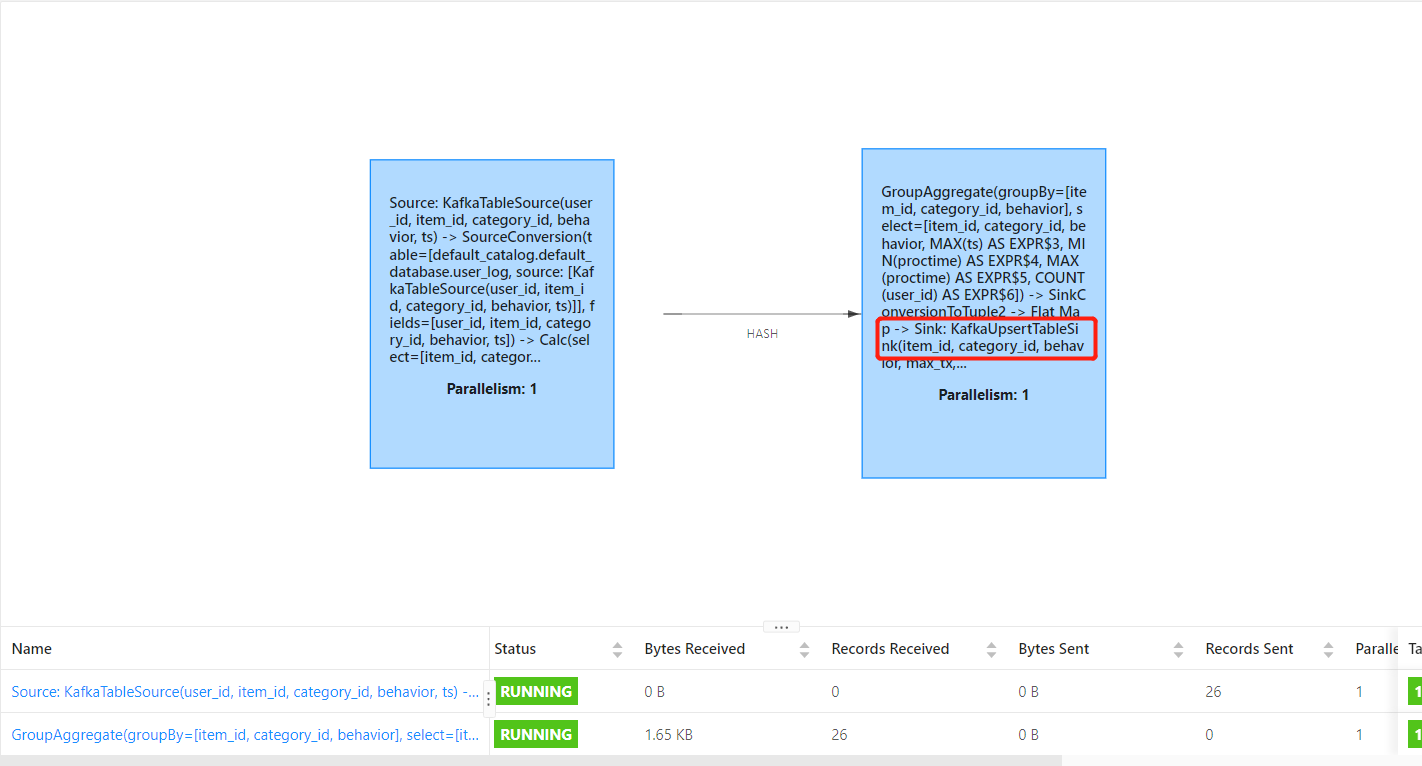
在 KafkaUpsertTableSinkBase 中 查看消息的 布尔值:
upsert 的消息:

比较尴尬的问题是,没看到 false 的消息,哪怕是同一条消息一直发,count 值是在 增加,但是没有 false 的去删除上一条消息
输出结果:
{"item_id":"3611281","category_id":"965809","behavior":"pv","max_tx":"2017-11-26T01:00:00Z","min_prc":"2020-04-08T05:20:26.694Z","max_prc":"2020-04-08T05:26:16.525Z","coun":10}
{"item_id":"3611281","category_id":"965809","behavior":"pv","max_tx":"2017-11-26T01:00:00Z","min_prc":"2020-04-08T05:20:26.694Z","max_prc":"2020-04-08T05:26:27.317Z","coun":11}
完整代码可以在这里找到:https://github.com/springMoon/flink-rookie/tree/master/src/main/scala/com/venn/source
水平有限,样例仅供参考
欢迎关注Flink菜鸟公众号,会不定期更新Flink(开发技术)相关的推文
