前言
博客好像又荒废许久了。。。(懒狗终究还是一条懒狗
现在打算学习CSAPP神书,补一补基础。先在这里记录自己的找到的学习资源与自己的学习计划:
- B站学习视频与书(深入理解计算机系统,卡梅隆大学,机械工业出版社版本)相结合,计划是先看一遍视频然后过一遍书,然后记录成为一篇博客整合发出来。
- 做书本的家庭作业以及所有的lab吧,这部分的代码应该会放在GitHub。
- 找到两个大佬的学习记录:https://zhuanlan.zhihu.com/p/103476182 https://wdxtub.com/csapp/thin-csapp-0/2016/04/16/ (其实至于为什么我还去找别人的参考,我觉得主要有两点,一别人的学习博客一般已经整理了思路,如果遇到不懂的,去看看别人的学习记录可能会得到解决;二是,我自己本身也是打算写学习记录,然后觉得自己水平有限,从零到一来说太难,所以有可能是套别人轮子,虽然我觉得这样子确实不对。。。)
- 最后,希望自己坚持下来吧,虽然自己感觉对自己来说很难,毕竟一天学习一章,自己也还想学习内核的知识。不过,与其观望,不如动起手来去做,干就vans了!
计算机系统漫游
其实这部分就是对应于整本书的总括吧,对应视频上的第一集,以及书上的第一章。
对于视频上的,主要是作者本人对他们的课程介绍,要求以及课程总览。
这里,主要记录一下书上的第一章(感觉像是中文翻译版时添加的)
从简单的程序说起
//vim hello.c
#include <stdio.h>
int main(){
printf("hello world
");
return 0;
}
这段代码需要保存在一个文件中,称为源文件,这是这段程序生命周期的开始。但是计算机只知道0和1的二进制数,并不知道你写的这些文本到底是什么。所以大部分的现代计算机系统都会使用ASCII标准来表示这些文本,简单来说就是给每个字符都指定一个唯一的单字节大小的编号,然后将文本中的字符都根据ASCII标准替换成对应的编号后,就转换成了字节序列,所以该源文件是以字节序列的形式保存在文件中的。
hello.c的表示方法说明了一个基本思想:系统中所有的信息,都是由一串比特表示的。区分不同数据对象的唯一方法就是我们读到这些数据对象时的上下文。
程序被其他程序翻译为不同的格式
在Linux系统下,我们用以下命令编译:
gcc -o hello hello.c
在这里,GCC编译器读取源文件hello.c,并把他翻译为一个可执行目标文件hello。主要会经历以下步骤:

所以,其实GCC编译器也就是cpp,cc1,as,ld的封装而已。
运行hello程序
这里,先简单介绍一下计算机的硬件结构。
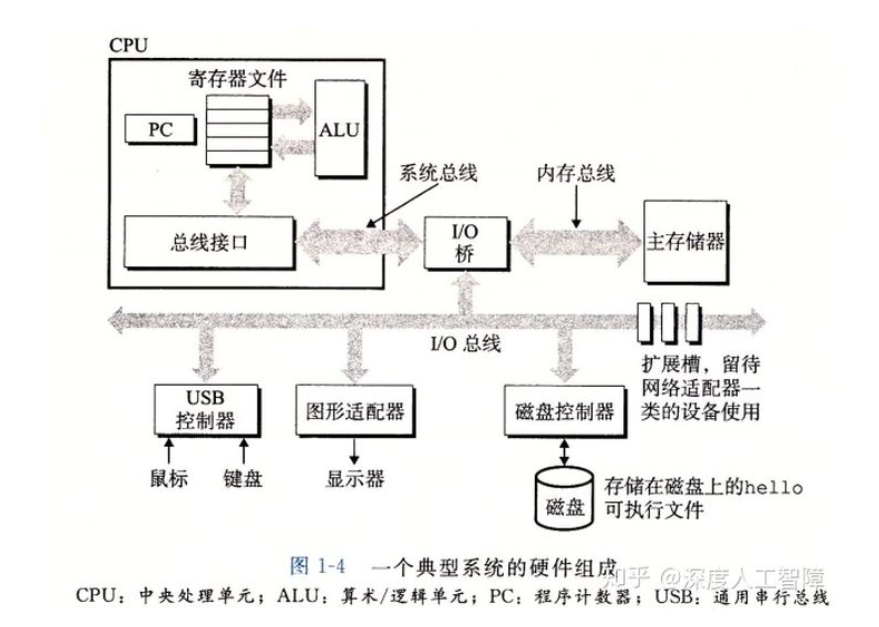
初始时,shell程序执行他的指令,等待我们输入一个命令,当我们输入"./hello"时,shell程序会将字符逐一读入寄存器,然后把它放到内存中,如下图:

当我们敲下回车键,shell程序指导我们结束了输入。然后执行一系列指令来加载可执行的hello文件。这些指令将hello目标文件的代码和数据从磁盘赋值到主存。如下图:
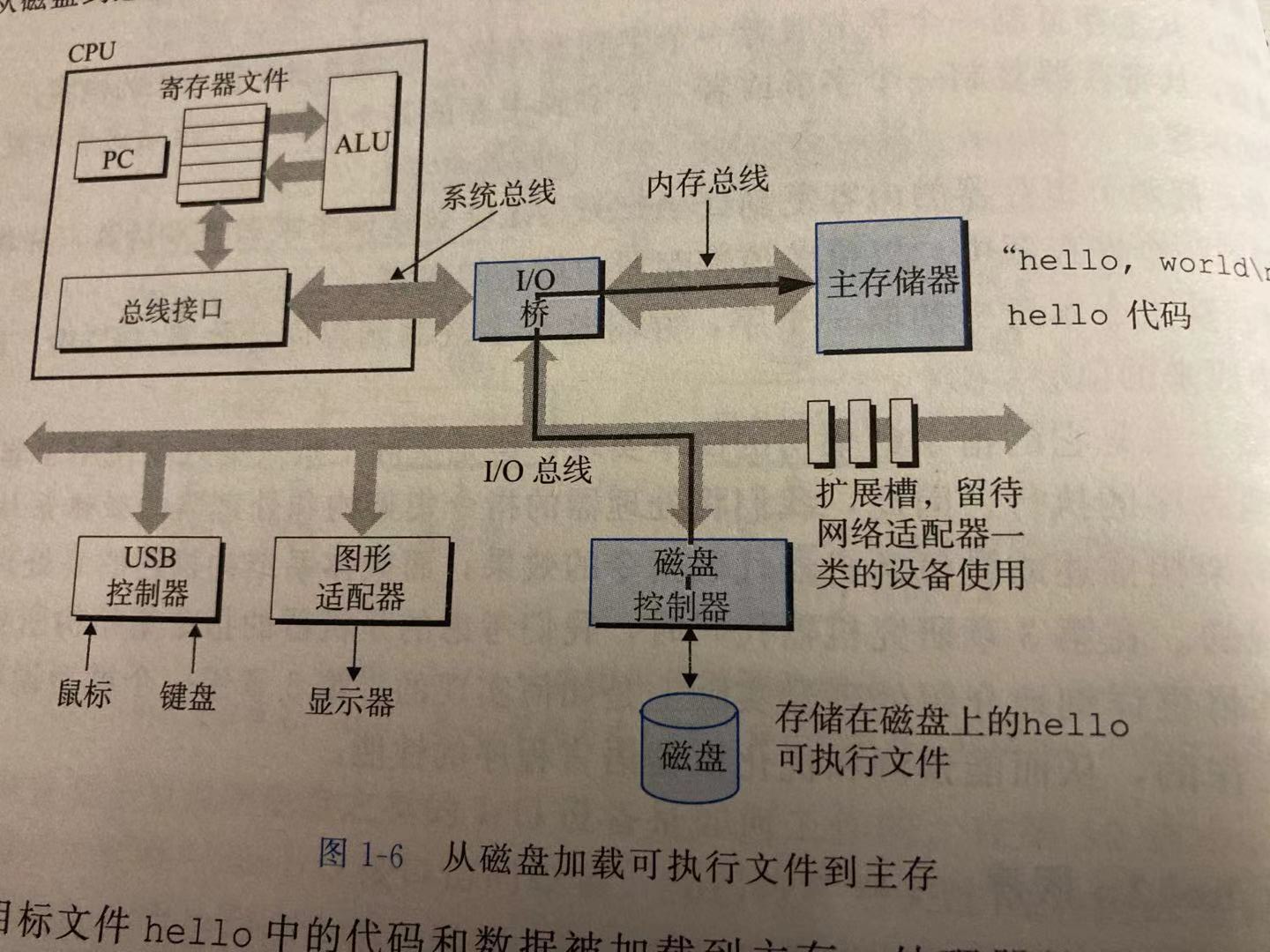
一旦目标文件hello中的代码和数据被加载到主存,处理开始执行hello程序的main程序中的机器语言指令,这些指令将"hello world"字符串中的字节从主存复制到寄存器文件,再将存储器文件中赋值到显示设备,最终显示在屏幕上。如下图:

高速缓存的重要性
从上面hello程序执行流程可以看出,系统花费了大量的时间把信息从一个地方挪到另一个地方。而从内存挪到寄存器需要花费大量时间,针对这中处理器于主存的差异,系统设计者采用了更小更快的存储设备,称为高速缓存寄存器。进而有了以下存储器结构:
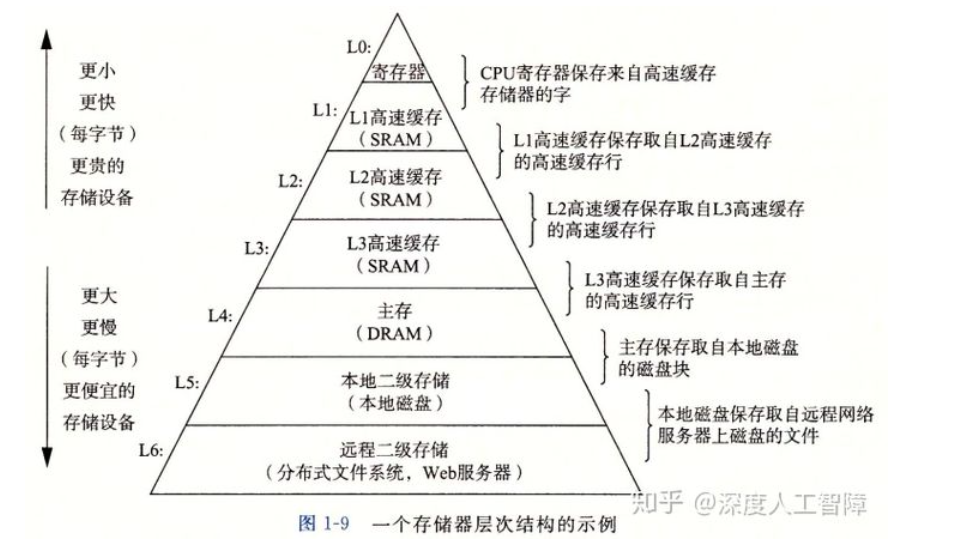
接下来书上简单引出了操作系统,进程线程的简单概念,这里不多加赘述。
系统之间利用网络通信
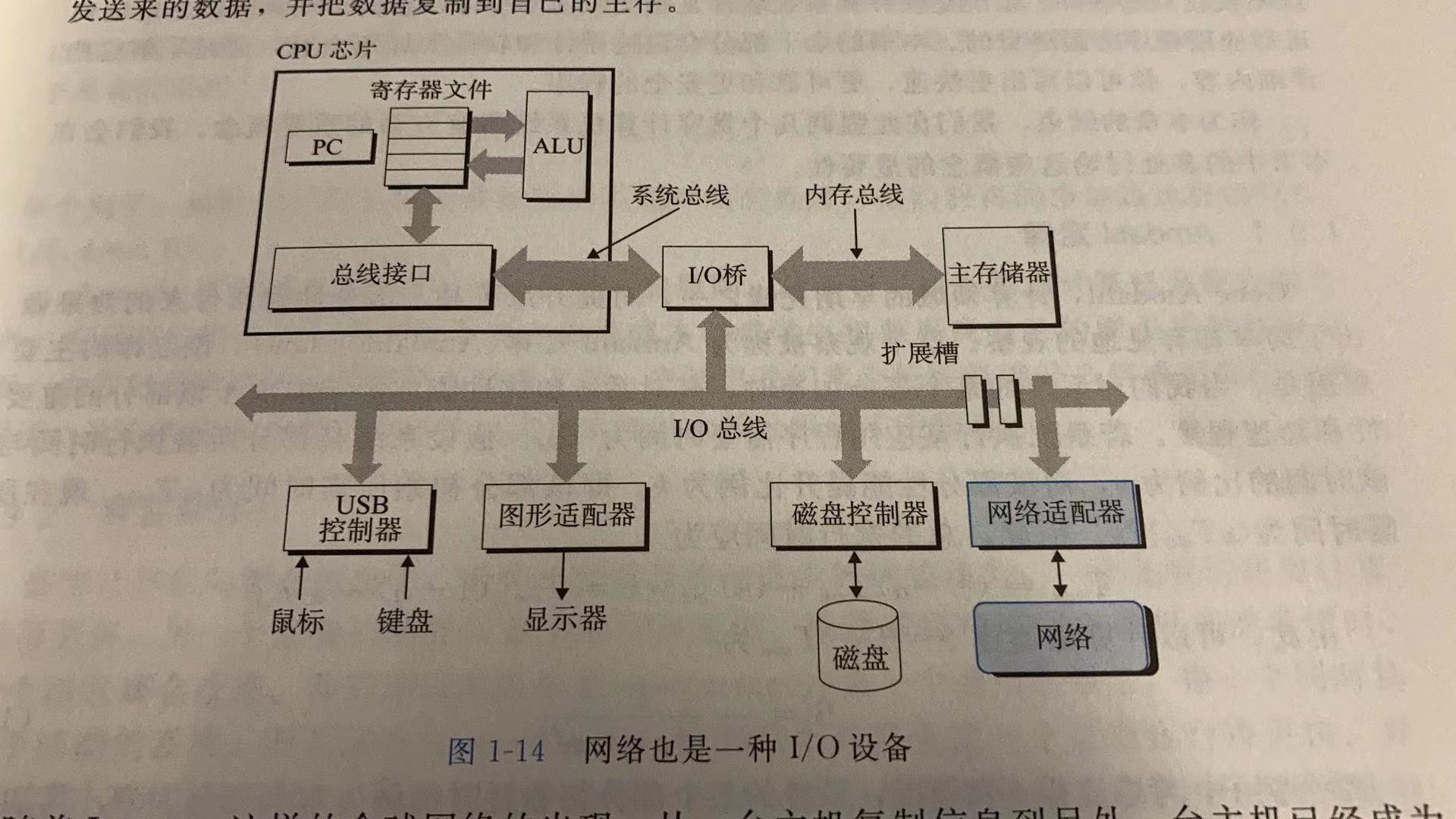
从一个单一的系统来看,网络被视为一个I/O设备,如下图所示,当系统从主存复制一串字节到网络适配器时,网络流经过网络到达另一机器,而不是不如说本地的磁盘驱动器。相似地,系统可以读取从其他机器发送来地数据,而把数据复制到自己地主存。
并发和并行
并发(Concurrency)指一个同时具有多个活动的系统。并行(Paralleism)指的是用并发来时一个系统运行得更快。并行可以在计算机系统的多个抽象层次上运用。
这里引用一下知乎的高赞回答
你吃饭吃到一半,电话来了,你一直到吃完了以后才去接,这就说明你不支持并发也不支持并行。你吃饭吃到一半,电话来了,你停了下来接了电话,接完后继续吃饭,这说明你支持并发。你吃饭吃到一半,电话来了,你一边打电话一边吃饭,这说明你支持并行。并发的关键是你有处理多个任务的能力,不一定要同时。并行的关键是你有同时处理多个任务的能力。所以我认为它们最关键的点就是:是否是『同时』。
这里简单总结一下书上的第一章,方便自己回去复习。