Linux命令介绍
软硬链接
作用:建立连接文件,linux下的连接文件类似于windows下的快捷方式
分类:
软链接:软链接不占用磁盘空间,源文件删除则软链接失效
硬链接:硬链接只能链接不同文件,不能链接目录
创建:
软链接:ln -s 源文件 链接文件
硬链接:ln 源文件 链接文件
注意:
软链接:如果软链接文件和源文件不在同一个目录下,源文件要使用绝对路径,不能使用相对路径
硬链接:两个文件占用相同大小的磁盘空间,即删除源文件,链接文件还是存在。
远程拷贝
本地文件复制到远程:scp -r 本地文件的绝对路径或相对路径 目标用户名@目标主机ip地址: 目标文件的绝对路径
远程文件复制到本地:scp -r 目标用户名@目标主机ip地址: 目标文件的绝对路径 保存到本机的绝对路径或者相对路径
Python环境安装
安装所需包文件
- apt update 更新源信息
- python 或 python3 检查是否安装了python或python3
- apt install python-dev python3-dev 安装python环境开发包
- apt install python-pip python3-pip 安装python包管理工具
- pip install virtualenvwrapper 安装pythonde虚拟环境
配置虚拟环境
- pwd 查看当前目录在/root下
- mkdir .virtualenvs 创建虚拟环境文件
- find / -name virtualenvwrapper.sh 查找虚拟环境文件的位置。文件在/usr/local/bin/virtualenvwrapper.sh位置
- vim .bashrc 末行添加虚拟环境的环境变量。然后wq保存退出。
- # python VirtualEnv
- export WORKON_HOME=/root/.virtualenvs
- source /usr/local/bin/virtualenvwrapper.sh
- source .bashrc 将虚拟环境激活一下
创建虚拟环境
- mkvirtualenv GYPText -p /usr/bin/python3 创建虚拟环境GYPText,并制定python的解释器
- deactivate 退出虚拟环境
创建工程依赖
- 环境迁移:pip install -r requirements.txt [安装 requirements.txt 中所列举的依赖包]
Mysql安装和配置
服务端安装 [Linux]
- sudo apt-get update
- sudo apt-get install mysql-server 安装过程中需要输入用户名密码
- sudo service mysql start 启动服务
- sudo service mysql stop 停止服务
- sudo service mysql restart 重启服务
启动后链接
- mysql -uroot -p 回车后 输入密码连接
- quit 退出连接
- mysql -h 远程ip地址 -uroot -p 连接远程服务器的数据库
可视化软件
- 如果是连接远程服务器的mysql,需要打开远程阿里云服务器的安全组协议[参考本地文档]
Redis安装与配置
下载解压
- redis安装需要去其官网https://redis.io/获取下载地址:http://download.redis.io/releases/redis-5.0.7.tar.gz
- mkdir software 创建自己软件的文件夹
- cd softwate 进入这个文件夹
- wget http://download.redis.io/releases/redis-5.0.7.tar.gz 下载redis
- ls 查看会有一个redis-5.0.7.tar.gz文件
- tar -zxvf redis-5.0.7.tar.gz 解压此文件
- ls 查看会有两个文件redis-5.0.7 redis-5.0.7.tar.gz
编辑安装
- cd redis-5.0.7 进入到redis-5.0.7文件
- make 编译构建一下
- make test 测试一下,需要tcl支持库
- apt install tcl 安装tcl
- make test 再次测试一下。成功
- make install 安装redis,会跳到上层目录
- cd utils 进入到工具文件夹下
- ls 查看,文件夹下有一个安装服务器脚本install_server.sh
- ./install_server.sh 调用此脚本进行安装
- 安装过程
- 选择端口,回车默认6379
- 选择conf名称,回车默认6379.conf
- 选择log日志的位置,回车默认/var/log/redis_6379.log
- 选择存放实例文件夹,回车默认/var/lib/redis/6379
- 选择redis执行实例,回车默认/usr/local/bin/redis-server
- 回车确认配置信息
- 安装 成功
- ps -ef | grep redis 查看redis进程,redis-server已经启动
操作redis
- redis-cli 连接redis,需要在redis-server启动的情况下连接
- ping 结果是pong表示可以连接
Redis主从配置
一个master(主,管理者)可以对应拥有多个slave(工作者),一个slave又可以拥有多个slave,如此下去,就可以形成一个强大的多级服务器集群架构。其实这就是redis分布式的一个问题。比如将ip为112.126.60.17的机器为主服务器,将ip为112.126.60.18机器作为从服务器。一般从服务器不用我们管,我们在主服务器存的数据,从服务器上自动同步做备份过来一份,其实这就是容灾的原理。其实这就是主从配置,也就相当于形成了两个集群,一个集群是主的,一个集群是从的。可能需要在同一个网段才可以实现(自己的两个虚拟机)。一般普通公司不会做主从配置,因为需要另一台服务器开销太大。
-
设置主服务器的配置
-
sudo vim /etc/redis/6379.conf 进入主rides服务器配置文件
-
/bind 底行模式查找bing行配置
-
bing 112.126.60.17 配置为阿里云主redis服务器ip私有IP地址信息
-
wq!
-
ps -aux | grep redis 查看redis进程
-
sudo kill -9 redis进程号
-
sudo /usr/local/redis/src/redis-server /etc/redis/6379.conf 重新启动redis服务
-
-
设置从服务器的配置
-
sudo vim /etc/redis/6379.conf 进入从rides服务器配置文件
-
/bind 底行模式查找bing行配置
-
bing 112.126.60.18 配置上阿里云从redis服务器的私有ip地址信息
-
slaveof 112.126.60.17 6379 配置上阿里云reids主服务器的私有ip地址信息
-
wq!
-
ps -aux | grep redis 查看redis进程
-
sudo kill -9 redis进程号 杀死终止reids进程
-
sudo /usr/local/redis/src/redis-server /etc/redis/6379.conf 重新启动redis服务
-
sudo redis-server /etc/redis/6379.conf 也可以这样启动
-
-
连接使用redis主服务器(master服务器上写数据)
-
redis-cli -h 阿里云公有ip主服务器地址 -p 6379 连接redis服务
-
auth reids密码 输入redis密码连接
-
set aaa bbb 在主服务器中存入键值对aaa:bbb
-
-
连接使用redis从服务器(slave服务器上读取数据)
-
redis-cli -h 阿里云公有ip从服务器地址 -p 6379 连接redis服务
-
auth reids密码 输入redis密码连接
-
get aaa 在从服务器中通过键aaa获取值
-
"bbb"
-
Redis发布订阅
项目环境配置
工程创建:[爬虫工程为例,web工程类似]
最好做到一个项目一个虚拟环境。项目多后方便查看项目所用各工具的版本。
- 先在终端: cd到存放的目录下并进入虚拟环境
- 创建项目: scrapy startproject 工程项目名
- cd到项目的根目录 [一个项目一个虚拟环境的创建虚拟环境方式]
- 虚拟环境: mkvirtualenv 虚拟环境名 [建虚拟环境要在项目的根目录下建]
- 进入环境: source 虚拟环境名/bin/activate [虚拟环境目录在此项目的根目录下]
- 建包文件: touch requirements.txt [新建一个txt文件,用来存放安装的工具包名称]
- 进入文件: vim requirements.txt [编辑输入需要的包文件名称,并保存退出]
- 执行文件: pip install -r requirements.txt [执行该文件会安装里面的包文件;可以pip freeze > requirements.txt生成该文件]
- 创建爬虫: scrapy genspider 爬虫名 域名 [爬虫名最好起爬哪一个板块叫哪一个板块名称,不要和项目名同名]
- 打开项目: 用pycharm打开此项目。
- 然后再在: pycharm中打开此项目(空工程)
- 创建爬虫: scrapy genspider 爬虫名 该网站域名 pycharm终端[gyp@localhost ~/pyword/spider05/MyScrapy] $scrapy genspider budejie budejie.com
- 运行爬虫: scrapy crawl 爬虫名 [-o xx.json/xml/csv] scrapy crawl qiubai -o budejie.json
- 代码调试: scrapy shell
- 查看版本: scrapy version
- 具体查看: 查看运行scrapy的python版本:
- which scrapy 找到scrapy文件存储路径 。scrapy文件是一个可执行文件(也可说是一个python文件)
- vim 查找到的路径。打开此可执行文件后的第一行 #!表示执行此可执行文件的解释器(python)的路径
- 此python解释器的路径 + -V 命令即可知道此执行文件scrapy的解释器python的版本号是多少。
django-debug-toolbar
介绍:django-debug-toolbar 是Django调试工具条,提供了各种信息的获取,拥有极强的调试功能。
官网:https://django-debug-toolbar.readthedocs.io/en/latest/
安装:
- pip install django-debug-toolbar
- pip install django-debug-toolbar -i https://pypi.douban.com/simple
注册:
- settings.py
# Application definition INSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', # 1. 静态文件注册 'user.apps.UserConfig', 'debug_toolbar', # 2. 注册django-debug-toolbar ] MIDDLEWARE = [ 'debug_toolbar.middleware.DebugToolbarMiddleware', # 4. 配置debug-toolbar中间件 'django.middleware.security.SecurityMiddleware', 'django.contrib.sessions.middleware.SessionMiddleware', 'django.middleware.common.CommonMiddleware', 'django.middleware.csrf.CsrfViewMiddleware', 'django.contrib.auth.middleware.AuthenticationMiddleware', 'django.contrib.messages.middleware.MessageMiddleware', 'django.middleware.clickjacking.XFrameOptionsMiddleware', ] STATIC_URL = '/static/' # 3. 配置静态文件路径 STATICFILES_DIRS = [ os.path.join(BASE_DIR, 'static') ] INTERNAL_IPS = ['127.0.0.1','localhost'] # 5. 配置允许访问的主机ip
- urls.py [根URL中]
1 from django.contrib import admin 2 from django.urls import path, include 3 from djangp_work import settings 4 5 urlpatterns = [ 6 path('admin/', admin.site.urls), 7 path('user/',include('user.urls',namespace='user')), 8 ] 9 10 if settings.DEBUG: 11 import debug_toolbar 12 urlpatterns = [ 13 path('__debug__/', include(debug_toolbar.urls)), 14 ] + urlpatterns
效果:
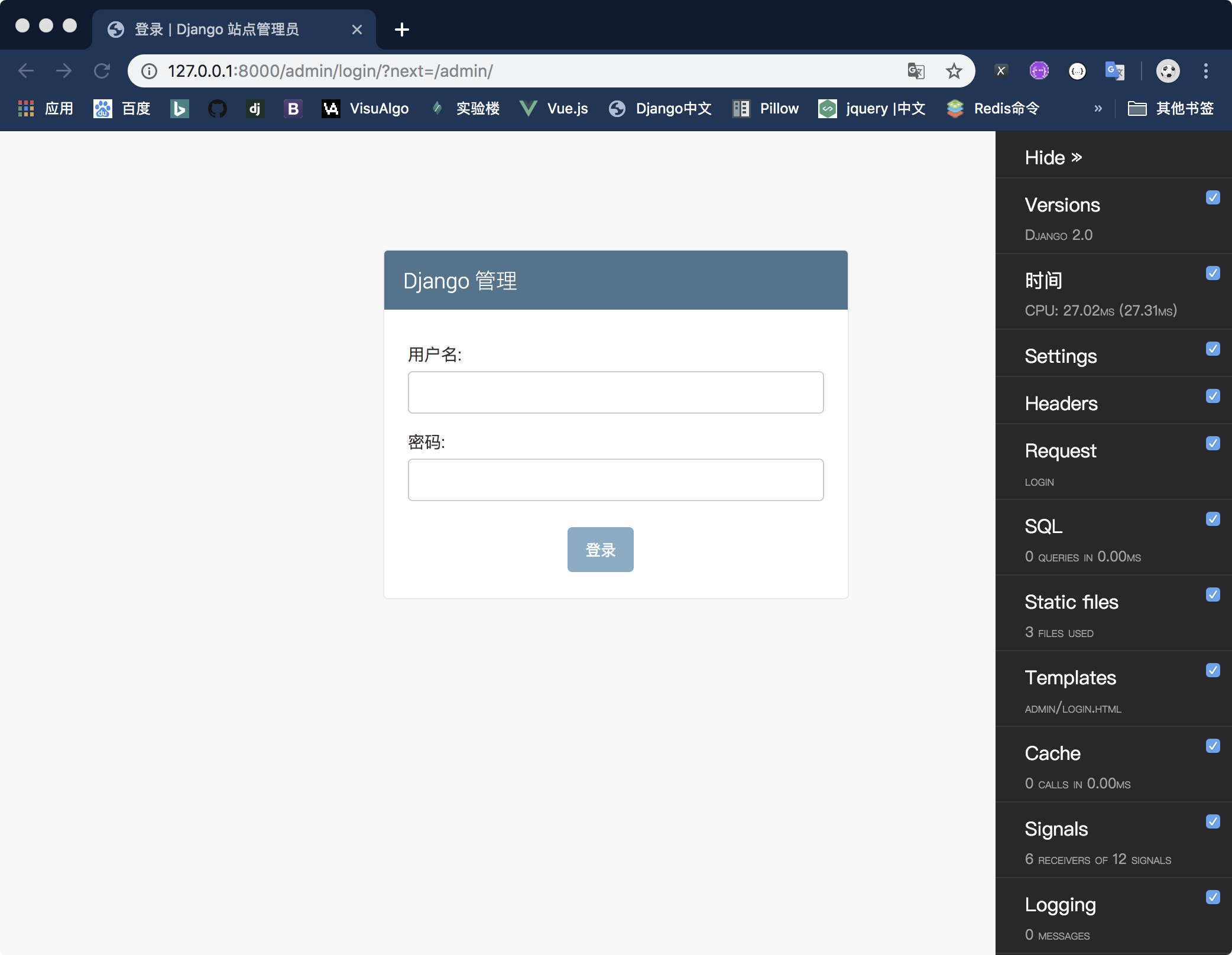
注释:
- Versions:各版本信息
- 时间:各过程加载的时间
- Settings:此项目的所有配置
- Headers:请求头、相应头
- Requets:请求信息
- SQL:可以动态追中所有语句、消耗时间。方便优化
thefuck
文档:https://github.com/nvbn/thefuck
安装:
- brew install thefuck [Mac]
- sudo apt update [Ubuntu]
- sudo apt install python3-dev python3-pip python3-setuptools
- sudo pip3 install thefuck
配置:
- sudo vim .bashrc [Ubuntu] 进入配置文件
- sudo vim ~/.bash_profile [Mac] 进入配置文件
- 末行添加:
- eval $(thefuck --alias)
- # You can use whatever you want as an alias, like for Mondays
- eval $(thefuck --alias FUCK)
- :wq 保存退出
- source .bashrc 刷新启动
使用:
在终端输入命令时,如果命令输入错误不能执行,
输入 fuck 就可以自动更改,上下键选择,ctrl+c退出
如果还不对可以继续fuck