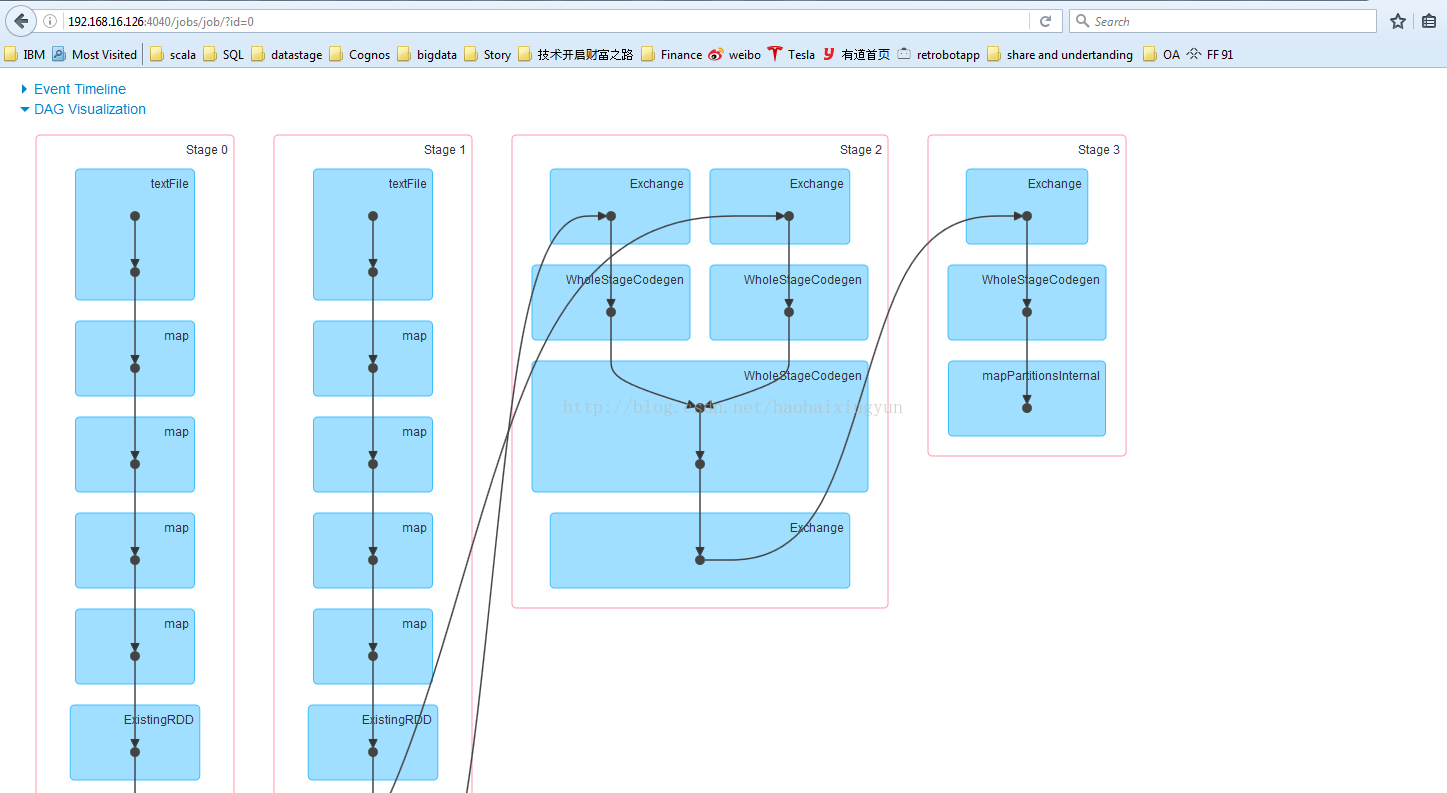
package com.xh.movies
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.{Row, SparkSession}
import org.apache.spark.sql.types.{StringType, StructField, StructType}
/**
* Created by xxxxx on 3/15/2017.
*/
object DataFrameJoin {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local").setAppName("dataframe")
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
val sc = spark.sparkContext // 不同形式风格的sc
//* 1,"ratings.dat": UserID::MovieID::Rating::Timestamp ///For each threat, you should assign ratings of risk impacts for each asset
//* 2,"users.dat": UserID::Gender::Age::OccupationID::Zip-code
val userRDD= sc.textFile("data/medium/users.dat").map(_.split("::")).map(x => (x(0),x(1)))
val ratingRDD= sc.textFile("data/large/ratings.dat").map(_.split("::")).map(x => (x(0),x(1)))
//define the struct and type 这部分内容 让人想让不爽 ,麻烦
val schemaUser = StructType("UserID::Gender".split("::").map(column => StructField(column,StringType,true)))
val schemaRating = StructType("UserID::MovieID".split("::").map(column => StructField(column,StringType,true)))
val rowUser: RDD[Row] = userRDD.map(line => Row(line._1,line._2))
val rowRating: RDD[Row] = ratingRDD.map(line => Row(line._1,line._2))
val userDataFaram = spark.createDataFrame(rowUser,schemaUser)
val ratingDataFram = spark.createDataFrame(rowRating,schemaRating)
ratingDataFram.filter(s" movieid = 3578")
.join(userDataFaram,"userid")
.select("movieid","gender")
.groupBy("gender")
.count()
.show(10)
//gender 挺麻烦
// +------+-----+
// |gender|count|
// +------+-----+
// | F| 319|
// | M| 896|
// +------+-----+3
//userDataFaram.registerTempTable() //已经被遗弃了
userDataFaram.createOrReplaceTempView("users")
ratingDataFram.createOrReplaceTempView("ratings")
val sql = "select count(*) as count ,gender from users u join ratings r on u.userid = r.userid where movieid = 3578 group by gender order by 2"
spark.sql(sql).show()
while (true){}
sc.stop()
}
}