数据准备
课程中获取数据的方法是从库中直接load_data
from keras.datasets import mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
我尝试了一下,报这样的错误:[WinError 10054] 远程主机强迫关闭了一个现有的连接。so,我就直接去官网下载了数据集:http://yann.lecun.com/exdb/mnist/。该数据下载后得到的是idx格式数据,具体处理方法参考了这篇博客https://www.jianshu.com/p/84f72791806f,测试可用的源码如下(规则在注释里写得很详细),在后文中会直接调用里边的函数。


import numpy as np import struct import matplotlib.pyplot as plt # 训练集文件 train_images_idx3_ubyte_file = 'C:\Users\小辉\Desktop\MNIST\train-images.idx3-ubyte' # 训练集标签文件 train_labels_idx1_ubyte_file = 'C:\Users\小辉\Desktop\MNIST\train-labels.idx1-ubyte' # 测试集文件 test_images_idx3_ubyte_file = 'C:\Users\小辉\Desktop\MNIST\t10k-images.idx3-ubyte' # 测试集标签文件 test_labels_idx1_ubyte_file = 'C:\Users\小辉\Desktop\MNIST\t10k-labels.idx1-ubyte' def decode_idx3_ubyte(idx3_ubyte_file): """ 解析idx3文件的通用函数 :param idx3_ubyte_file: idx3文件路径 :return: 数据集 """ # 读取二进制数据 bin_data = open( train_images_idx3_ubyte_file, 'rb').read() # 解析文件头信息,依次为魔数、图片数量、每张图片高、每张图片宽 offset = 0 fmt_header = '>iiii' magic_number, num_images, num_rows, num_cols = struct.unpack_from(fmt_header, bin_data, offset) #print('魔数:%d, 图片数量: %d张, 图片大小: %d*%d' % (magic_number, num_images, num_rows, num_cols)) # 解析数据集 image_size = num_rows * num_cols offset += struct.calcsize(fmt_header) fmt_image = '>' + str(image_size) + 'B' images = np.empty((num_images, num_rows, num_cols)) for i in range(num_images): #if (i + 1) % 10000 == 0: #print('已解析 %d' % (i + 1) + '张') images[i] = np.array(struct.unpack_from(fmt_image, bin_data, offset)).reshape((num_rows, num_cols)) offset += struct.calcsize(fmt_image) return images def decode_idx1_ubyte(idx1_ubyte_file): """ 解析idx1文件的通用函数 :param idx1_ubyte_file: idx1文件路径 :return: 数据集 """ # 读取二进制数据 bin_data = open(idx1_ubyte_file, 'rb').read() # 解析文件头信息,依次为魔数和标签数 offset = 0 fmt_header = '>ii' magic_number, num_images = struct.unpack_from(fmt_header, bin_data, offset) #print('魔数:%d, 图片数量: %d张' % (magic_number, num_images)) # 解析数据集 offset += struct.calcsize(fmt_header) fmt_image = '>B' labels = np.empty(num_images) for i in range(num_images): #if (i + 1) % 10000 == 0: # print('已解析 %d' % (i + 1) + '张') labels[i] = struct.unpack_from(fmt_image, bin_data, offset)[0] offset += struct.calcsize(fmt_image) return labels def load_train_images(idx_ubyte_file=train_images_idx3_ubyte_file): """ TRAINING SET IMAGE FILE (train-images-idx3-ubyte): [offset] [type] [value] [description] 0000 32 bit integer 0x00000803(2051) magic number 0004 32 bit integer 60000 number of images 0008 32 bit integer 28 number of rows 0012 32 bit integer 28 number of columns 0016 unsigned byte ?? pixel 0017 unsigned byte ?? pixel ........ xxxx unsigned byte ?? pixel Pixels are organized row-wise. Pixel values are 0 to 255. 0 means background (white), 255 means foreground (black). :param idx_ubyte_file: idx文件路径 :return: n*row*col维np.array对象,n为图片数量 """ return decode_idx3_ubyte(idx_ubyte_file) def load_train_labels(idx_ubyte_file=train_labels_idx1_ubyte_file): """ TRAINING SET LABEL FILE (train-labels-idx1-ubyte): [offset] [type] [value] [description] 0000 32 bit integer 0x00000801(2049) magic number (MSB first) 0004 32 bit integer 60000 number of items 0008 unsigned byte ?? label 0009 unsigned byte ?? label ........ xxxx unsigned byte ?? label The labels values are 0 to 9. :param idx_ubyte_file: idx文件路径 :return: n*1维np.array对象,n为图片数量 """ return decode_idx1_ubyte(idx_ubyte_file) def load_test_images(idx_ubyte_file=test_images_idx3_ubyte_file): """ TEST SET IMAGE FILE (t10k-images-idx3-ubyte): [offset] [type] [value] [description] 0000 32 bit integer 0x00000803(2051) magic number 0004 32 bit integer 10000 number of images 0008 32 bit integer 28 number of rows 0012 32 bit integer 28 number of columns 0016 unsigned byte ?? pixel 0017 unsigned byte ?? pixel ........ xxxx unsigned byte ?? pixel Pixels are organized row-wise. Pixel values are 0 to 255. 0 means background (white), 255 means foreground (black). :param idx_ubyte_file: idx文件路径 :return: n*row*col维np.array对象,n为图片数量 """ return decode_idx3_ubyte(idx_ubyte_file) def load_test_labels(idx_ubyte_file=test_labels_idx1_ubyte_file): """ TEST SET LABEL FILE (t10k-labels-idx1-ubyte): [offset] [type] [value] [description] 0000 32 bit integer 0x00000801(2049) magic number (MSB first) 0004 32 bit integer 10000 number of items 0008 unsigned byte ?? label 0009 unsigned byte ?? label ........ xxxx unsigned byte ?? label The labels values are 0 to 9. :param idx_ubyte_file: idx文件路径 :return: n*1维np.array对象,n为图片数量 """ return decode_idx1_ubyte(idx_ubyte_file) def run(): train_images = load_train_images() train_labels = load_train_labels() test_images = load_test_images() test_labels = load_test_labels() # 查看前十个数据及其标签以读取是否正确 for i in range(10): print(train_labels[i]) plt.imshow(train_images[i], cmap='gray') plt.show() print('done') if __name__ == '__main__': run()
数据预处理
导入相关包依赖及预处理函数
import numpy as np
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation
from keras.layers import Conv2D, MaxPooling2D, Flatten
from keras.optimizers import SGD, Adam
from keras.utils import np_utils
#clean data
def load_dataset():
x_train, y_train = load_train_images(), load_train_labels()
x_test, y_test = load_test_images(), load_test_labels()
number = 60000
x_train, y_train = x_train[0:number], y_train[0:number]
x_train = x_train.reshape(number, 28*28)
x_test = x_test.reshape(x_test.shape[0], 28*28)
x_train, x_test = x_train.astype('float32'), x_test.astype('float32')
y_train, y_test = np_utils.to_categorical(y_train, 10), np_utils.to_categorical(y_test, 10)
x_train, x_test = x_train / 255, x_test / 255
return (x_train, y_train), (x_test, y_test)
到此,我们得到了训练和测试网络所需要的数据。
网络的搭建及训练结果
搭建网络训练结果
(x_train, y_train), (x_test, y_test) = load_dataset()
model = Sequential()
#搭建三层网络
model.add(Dense(input_dim=28*28,units=633,activation='sigmoid'))
model.add(Dense(units=633,activation='sigmoid'))
model.add(Dense(units=10,activation='softmax'))
model.compile(loss='mse',optimizer=SGD(lr=0.1),metrics=['accuracy'])
model.fit(x_train,y_train,batch_size=100,epochs=20)
result = model.evaluate(x_test,y_test)
print('Test loss:', result[0])
print('Accuracy:', result[1])
效果如下图所示:
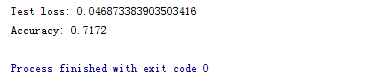
改动地方主要为:
- 激励函数由sigmoid改为relu
- loss function由mse改为categorical_crossentropy
- 增加了Dropout,防止过拟合
改动后构建模型代码:
#搭建网络训练结果
(x_train, y_train), (x_test, y_test) = load_dataset()
model = Sequential()
#搭建三层网络
model.add(Dense(input_dim=28*28,units=700,activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(units=700,activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(units=10,activation='softmax'))
model.compile(loss='categorical_crossentropy',optimizer=SGD(lr=0.1),metrics=['accuracy'])
model.fit(x_train,y_train,batch_size=100,epochs=20,validation_split=0.05)
result = model.evaluate(x_test,y_test)
print('Test loss:', result[0])
print('Accuracy:', result[1])
效果如下所示:
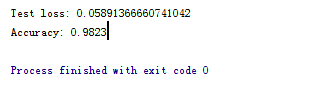
得到了比较好的测试结果。其中,最主要的还是激励函数影响。
1. 采用sigmoid等函数,算激活函数时(指数运算),计算量大,反向传播求误差梯度时,求导涉及除法,计算量相对大,而采用Relu激活函数,整个过程的计算量节省很多。
2. 对于深层网络,sigmoid函数反向传播时,很容易就会出现梯度消失的情况(在sigmoid接近饱和区时,变换太缓慢,导数趋于0,这种情况会造成信息丢失,从而无法完成深层网络的训练。
3. Relu会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生。
参考:https://blog.csdn.net/waple_0820/article/details/79415397