CUDA有自己的存储器模型,线程在执行时将会访问到处于多个不同存储器空间中的数据。cuda应用程序开发中涉及8中存储器,层次结果如图所示:
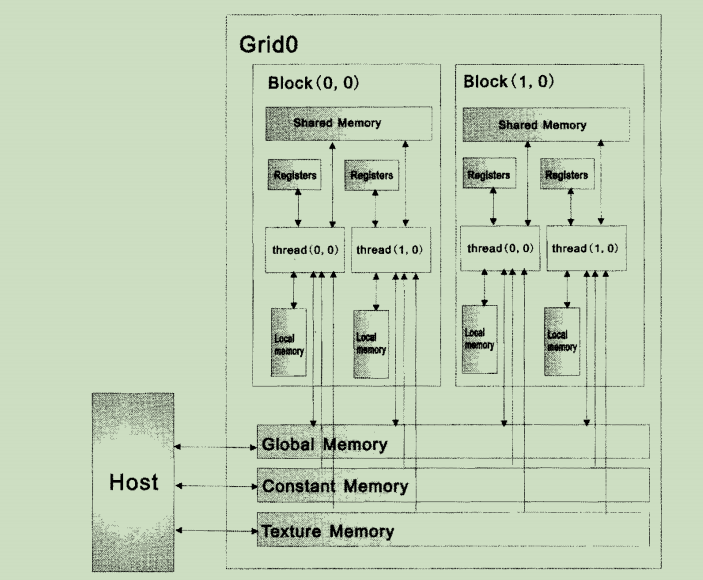
每一个线程拥有自己的私有存储器寄存器和局部存储器;每一个线程块拥有一块共享存储器(shared_memory);最后,grid中所有的线程都可以访问同一块全局存储器(global memory)。除此之外,还有两种可以被所有线程访问的只读存储器:常数存储器(constant memory)和纹理存储器(Texture memory),他们分别为不同的应用进行了优化。全局存储器、常数存储器和纹理存储器中的值在一个内核函数执行完成后将被继续保持,可以被同一程序中的其他内核函数调用。
各类存储器比较:
| 存储器 | 位置 | 拥有缓存 | 访问权限 | 变量生命周期 |
|---|---|---|---|---|
| register | GPU片内 | N/A | device可读/写 | 与thread相同 |
| local_memory | 板载显存 | 无 | device可读/写 | 与thread相同 |
| shared_memory | CPU片内 | N/A | device可读/写 | 与block相同 |
| constant_memory | 板载显存 | 有 | device可读,host可读/写 | 可在程序中保持 |
| texture_memory | 板载显存 | 有 | device可读,host可读/写 | 可在程序中保持 |
| global_memory | 板载显存 | 无 | device可读/写,host可读/写 | 可在程序中保持 |
| host_memory | host内存 | 无 | host可读/写 | 可在程序中保持 |
| pinned_memory | host内存 | 无 | host可读/写 | 可在程序中保持 |
说明
(1)Register和shared_memory都是GPU片上的高速存储器;
(2)通过mapped memory实现的zero copy功能,某些功能GPU可以直接在kernel中访问page-locked memory。
GPU执行的是一种内存的加载/存储模型(load-storage model),即所有的操作都要在指令载入寄存器之后才能执行,因此掌握GPU的存储器模型对于GPU代码性能的优化具有重要意义。