高可用配置案例
(一)、failover故障转移
在完成单点的Flume NG搭建后,下面我们搭建一个高可用的Flume NG集群,架构图如下所示:

(1)节点分配
Flume的Agent和Collector分布如下表所示:
|
名称 |
Ip地址 |
Host |
角色 |
|
Agent1 |
192.168.137.188 |
hadoop-001 |
WebServer |
|
Collector1 |
192.168.137.189 |
hadoop-002 |
AgentMstr1 |
|
Collector2 |
192.168.137.190 |
hadoop-003 |
AgentMstr2 |
Agent1数据分别流入到Collector1和Collector2,Flume NG本身提供了Failover机制,可以自动切换和恢复。下面我们开发配置Flume NG集群。
(2)配置
在下面单点Flume中,基本配置都完成了,我们只需要新添加两个配置文件,它们是flume-client.conf和flume-server.conf,其配置内容如下所示:
1、hadoop-001上的flume-client.conf配置
|
#agent1 name agent1.channels = c1 agent1.sources = r1 agent1.sinks = k1 k2
#set gruop agent1.sinkgroups = g1 #set sink group agent1.sinkgroups.g1.sinks = k1 k2
#set channel agent1.channels.c1.type = memory agent1.channels.c1.capacity = 1000 agent1.channels.c1.transactionCapacity = 100
agent1.sources.r1.channels = c1 agent1.sources.r1.type = exec agent1.sources.r1.command = tail -F /root/log/test.log
agent1.sources.r1.interceptors = i1 i2 agent1.sources.r1.interceptors.i1.type = static agent1.sources.r1.interceptors.i1.key = Type agent1.sources.r1.interceptors.i1.value = LOGIN agent1.sources.r1.interceptors.i2.type = timestamp
# set sink1 agent1.sinks.k1.channel = c1 agent1.sinks.k1.type = avro agent1.sinks.k1.hostname = hadoop-002 agent1.sinks.k1.port = 52020
# set sink2 agent1.sinks.k2.channel = c1 agent1.sinks.k2.type = avro agent1.sinks.k2.hostname = hadoop-003 agent1.sinks.k2.port = 52020
#set failover agent1.sinkgroups.g1.processor.type = failover agent1.sinkgroups.g1.processor.priority.k1 = 10 agent1.sinkgroups.g1.processor.priority.k2 = 5 agent1.sinkgroups.g1.processor.maxpenalty = 10000 #这里首先要申明一个sinkgroups,然后再设置2个sink ,k1与k2,其中2个优先级是10和5,#而processor的maxpenalty被设置为10秒,默认是30秒。‘ |
|
|
启动命令:
|
bin/flume-ng agent -n agent1 -c conf -f conf/flume-client.conf -Dflume.root.logger=DEBUG,console |
2、Hadoop-002和hadoop-003上的flume-server.conf配置
|
#set Agent name a1.sources = r1 a1.channels = c1 a1.sinks = k1
#set channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100
# other node,nna to nns a1.sources.r1.type = avro a1.sources.r1.bind = 0.0.0.0 a1.sources.r1.port = 52020 a1.sources.r1.channels = c1 a1.sources.r1.interceptors = i1 i2 a1.sources.r1.interceptors.i1.type = timestamp a1.sources.r1.interceptors.i2.type = host a1.sources.r1.interceptors.i2.hostHeader=hostname
#set sink to hdfs a1.sinks.k1.type=hdfs a1.sinks.k1.hdfs.path=/data/flume/logs/%{hostname} a1.sinks.k1.hdfs.filePrefix=%Y-%m-%d a1.sinks.k1.hdfs.fileType=DataStream a1.sinks.k1.hdfs.writeFormat=TEXT a1.sinks.k1.hdfs.rollInterval=10 a1.sinks.k1.channel=c1
|
启动命令:
|
bin/flume-ng agent -n agent1 -c conf -f conf/flume-server.conf -Dflume.root.logger=DEBUG,console |
(3)测试failover
1、先在hadoop-002和hadoop-003上启动脚本
|
bin/flume-ng agent -n a1 -c conf -f conf/flume-server.conf -Dflume.root.logger=DEBUG,console |
2、然后启动hadoop-001上的脚本
|
bin/flume-ng agent -n agent1 -c conf -f conf/flume-client.conf -Dflume.root.logger=DEBUG,console |
3、Shell脚本生成数据
|
while true;do date >> test.log; sleep 1s ;done |
4、观察HDFS上生成的数据目录。只观察到hadoop-002在接受数据
5、Hadoop-002上的agent被干掉之后,继续观察HDFS上生成的数据目录,hadoop-003对应的ip目录出现,此时数据收集切换到hadoop-003上
6、Hadoop-002上的agent重启后,继续观察HDFS上生成的数据目录。此时数据收集切换到hadoop-002上,又开始继续工作!
load balance负载均衡
(1)节点分配
如failover故障转移的节点分配
(2)配置
在failover故障转移的配置上稍作修改
hadoop-001上的flume-client-loadbalance.conf配置
|
#agent1 name agent1.channels = c1 agent1.sources = r1 agent1.sinks = k1 k2
#set gruop agent1.sinkgroups = g1
#set channel agent1.channels.c1.type = memory agent1.channels.c1.capacity = 1000 agent1.channels.c1.transactionCapacity = 100 agent1.sources.r1.channels = c1 agent1.sources.r1.type = exec agent1.sources.r1.command = tail -F /root/log/test.log
# set sink1 agent1.sinks.k1.channel = c1 agent1.sinks.k1.type = avro agent1.sinks.k1.hostname = hadoop-002 agent1.sinks.k1.port = 52020
# set sink2 agent1.sinks.k2.channel = c1 agent1.sinks.k2.type = avro agent1.sinks.k2.hostname = hadoop-003 agent1.sinks.k2.port = 52020
#set sink group agent1.sinkgroups.g1.sinks = k1 k2
#set load-balance agent1.sinkgroups.g1.processor.type = load_balance # 默认是round_robin,还可以选择random agent1.sinkgroups.g1.processor.selector = round_robin #如果backoff被开启,则 sink processor会屏蔽故障的sink agent1.sinkgroups.g1.processor.backoff = true
|
Hadoop-002和hadoop-003上的flume-server-loadbalance.conf配置
|
#set Agent name a1.sources = r1 a1.channels = c1 a1.sinks = k1
#set channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100
# other node,nna to nns a1.sources.r1.type = avro a1.sources.r1.bind = 0.0.0.0 a1.sources.r1.port = 52020 a1.sources.r1.channels = c1 a1.sources.r1.interceptors = i1 i2 a1.sources.r1.interceptors.i1.type = timestamp a1.sources.r1.interceptors.i2.type = host a1.sources.r1.interceptors.i2.hostHeader=hostname a1.sources.r1.interceptors.i2.useIP=false #set sink to hdfs a1.sinks.k1.type=hdfs a1.sinks.k1.hdfs.path=/data/flume/loadbalance/%{hostname} a1.sinks.k1.hdfs.fileType=DataStream a1.sinks.k1.hdfs.writeFormat=TEXT a1.sinks.k1.hdfs.rollInterval=10 a1.sinks.k1.channel=c1 a1.sinks.k1.hdfs.filePrefix=%Y-%m-%d |
(3)测试load balance
1、先在hadoop-002和hadoop-003上启动脚本
|
bin/flume-ng agent -n a1 -c conf -f conf/flume-server-loadbalance.conf -Dflume.root.logger=DEBUG,console |
2、然后启动hadoop-001上的脚本
|
bin/flume-ng agent -n agent1 -c conf -f conf/flume-client-loadbalance.conf -Dflume.root.logger=DEBUG,console |
3、Shell脚本生成数据
|
while true;do date >> test.log; sleep 1s ;done |
4、观察HDFS上生成的数据目录,由于轮训机制都会收集到数据
5、Hadoop-002上的agent被干掉之后,hadoop-002上不在产生数据
6、Hadoop-002上的agent重新启动后,两者都可以接受到数据
1. 案例场景:日志的采集及汇总
A、B两台日志服务机器实时生产日志主要类型为access.log、nginx.log、web.log
现在要求:
把A、B 机器中的access.log、nginx.log、web.log 采集汇总到C机器上然后统一收集到hdfs中。
但是在hdfs中要求的目录为:
/source/logs/access/20190101/**
/source/logs/nginx/20190101/**
/source/logs/web/20190101/**
2. 场景分析

图一
3. 数据流程处理分析
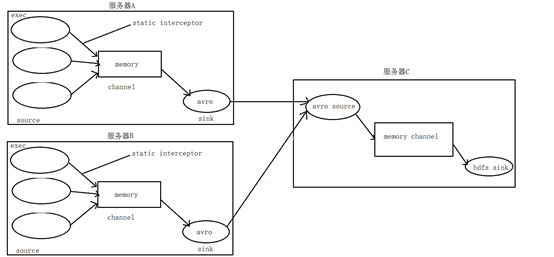
4. 实现
服务器A对应的IP为 192.168.137.188
服务器B对应的IP为 192.168.137.189
服务器C对应的IP为 192.168.137.190
① 在服务器A和服务器B上的$FLUME_HOME/conf 创建配置文件 exec_source_avro_sink.conf 文件内容为
# Name the components on this agent
a1.sources = r1 r2 r3
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /root/data/access.log
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = static
## static拦截器的功能就是往采集到的数据的header中插入自己定## 义的key-value对
a1.sources.r1.interceptors.i1.key = type
a1.sources.r1.interceptors.i1.value = access
a1.sources.r2.type = exec
a1.sources.r2.command = tail -F /root/data/nginx.log
a1.sources.r2.interceptors = i2
a1.sources.r2.interceptors.i2.type = static
a1.sources.r2.interceptors.i2.key = type
a1.sources.r2.interceptors.i2.value = nginx
a1.sources.r3.type = exec
a1.sources.r3.command = tail -F /root/data/web.log
a1.sources.r3.interceptors = i3
a1.sources.r3.interceptors.i3.type = static
a1.sources.r3.interceptors.i3.key = type
a1.sources.r3.interceptors.i3.value = web
# Describe the sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = 192.168.200.101
a1.sinks.k1.port = 41414
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 20000
a1.channels.c1.transactionCapacity = 10000
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sources.r2.channels = c1
a1.sources.r3.channels = c1
a1.sinks.k1.channel = c1
② 在服务器C上的$FLUME_HOME/conf 创建配置文件 avro_source_hdfs_sink.conf 文件内容为
#定义agent名, source、channel、sink的名称
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#定义source
a1.sources.r1.type = avro
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port =41414
#添加时间拦截器
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = org.apache.flume.interceptor.TimestampInterceptor$Builder
#定义channels
a1.channels.c1.type = memory
a1.channels.c1.capacity = 20000
a1.channels.c1.transactionCapacity = 10000
#定义sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path=hdfs://192.168.200.101:9000/source/logs/%{type}/%Y%m%d
a1.sinks.k1.hdfs.filePrefix =events
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
#时间类型
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#生成的文件不按条数生成
a1.sinks.k1.hdfs.rollCount = 0
#生成的文件按时间生成
a1.sinks.k1.hdfs.rollInterval = 30
#生成的文件按大小生成
a1.sinks.k1.hdfs.rollSize = 10485760
#批量写入hdfs的个数
a1.sinks.k1.hdfs.batchSize = 10000
flume操作hdfs的线程数(包括新建,写入等)
a1.sinks.k1.hdfs.threadsPoolSize=10
#操作hdfs超时时间
a1.sinks.k1.hdfs.callTimeout=30000
#组装source、channel、sink
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
③ 配置完成之后,在服务器A和B上的/root/data有数据文件access.log、nginx.log、web.log。先启动服务器C上的flume,启动命令
在flume安装目录下执行 :
bin/flume-ng agent -c conf -f conf/avro_source_hdfs_sink.conf -name a1 -Dflume.root.logger=DEBUG,console
然后在启动服务器上的A和B,启动命令
在flume安装目录下执行 :
bin/flume-ng agent -c conf -f conf/exec_source_avro_sink.conf -name a1 -Dflume.root.logger=DEBUG,console