MySQL 几大部分:存储引擎、索引、事务、锁
MySQL的MyISAM和InnoDB存储引擎的区别是啥?
myisam,不支持事务,不支持外键约束,索引文件和数据文件分开,这样在内存里可以缓存更多的索引,对查询的性能会更好,适用于那种少量的插入,大量查询的场景。
innodb,主要特点就是支持事务,走聚簇索引,强制要求有主键,支持外键约束,高并发、大数据量、高可用等相关成熟的数据库架构,分库分表、读写分离、主备切换,全部都可以基于innodb存储引擎。
聊聊MySQL的索引实现原理?各种索引你们平时都怎么用的?
- MySQL索引的原理和数据结构能介绍一下吗?
- b+树和b-树有什么区别?
- Myisam和Innodb存储引擎的索引实现?
- MySQL聚簇索引和非聚簇索引的区别是什么?
- 他们分别是如何存储的?
- 使用MySQL索引都有哪些原则?
- MySQL复合索引如何使用?
先说什么索引?
索引就是用一个数据结构组织某一个列数据,然后根据这一列数据查询时,不用全表扫描,根据特定数据结构找到那一列的值,然后找到对应行的物理地址。
先说b-树,画图如下:
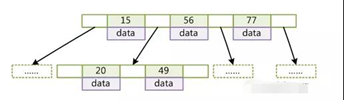
查找时,从根节点开始二分查找。
b+树是b-树的变形,不一样的地方:
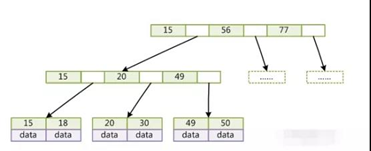
B-和B+树区别:
1. B+树只有叶子节点存储数据,其他中间节点只有索引没有数据,同样的大小的磁盘页可以容纳更多的节点元素。相同数量下,B+树更“矮胖”,查询IO次数更少。
2. B+树查询必须查找叶子节点,B+树查询更稳定(并不慢)。B-树查询性能不稳定,最好只查根节点,最坏查到叶子节点。
3. B+树范围查询更简便。B+树中序遍历要简单得多。
Myisam和Innodb存储引擎的索引实现?
myisam的索引中,每个叶子节点的data存放的是数据行的物理地址,每行对应一个物理地址。数据文件单独存放一个文件。最大特点是数据文件和索引文件是分开的。
innodb的数据文件本身就是索引文件,必须有主键,会根据主键建立一个默认索引,叫聚簇索引。
innodb下,对某个非主键字段创建索引,那么最后那个叶子节点的值就是主键的值,再用主键的值到聚簇索引里查找到数据,叫回表。
innodb,建议统一用auto_increment自增值作为主键,可以保持聚簇索引直接加记录,不用修改原来b+树的结构,浪费时间。
索引常见使用规则?
比如product表,创建索引:
create index (shop_id, product_id, gmt_create)
1. 全列匹配
where条件正好用到这3个字段,就用到联合索引。
2. 最左前缀匹配
SQL里,正好用到联合索引最左边的一个或几个列表。
3. 最左前缀匹配,但中间某个值没有匹配
如果sql用了联合索引第一列和第三列,会按照第一列在索引里找,找完后对结果集根据第三列做全表扫描,不会走第三列的索引了。
4. 前缀匹配
如果不是等值,或比如=, >, <=等操作,而是Like操作。则只有Like ‘xx%’ (%在最后)这种才能用上索引。
5. 范围匹配
只有符号最左前缀的列的范围才用到索引,范围之后的列用不到索引。
比如: select * from product where shop_id >= 1 and product_id = 1;
这里就只用到shop_id索引。
6. 包含函数
对某个列用了函数,则该列不走索引。
索引缺点以及使用注意?
常见缺点:增加磁盘消耗,占用磁盘文件,同时高并发频繁插入和修改索引,会导致性能损耗。
使用注意:1. 尽量创建少的索引,一个表,两三个。
2. 一个字段的值几乎都不太一样的,比如id,这样用索引效果最好。
小结:
互联网系统中,一般尽量降低SQL复杂度,用简单的主键索引(聚簇索引)+少数联合索引,
可以覆盖一个表的所有SQL查询,更复杂的业务逻辑,应该放在Java代码里实现。
SQL越简单,后面迁移,分库分表,读写分离的成本更低,减少对SQL的改造。
MySQL最好用在在线及时存储,不要用于计算(Join, 子查询,函数等等)。高并发场景下,计算放在Java内存里。
说说事务的几个特性是啥?有哪几种隔离级别?
特性:ACid
原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)
隔离级别:
1. 读未提交
事务A把id=1, name=张三修改为李四,但是还未提交,这时事务B已经看到id=1的name为李四了。
2. 读已提交(不可重复读)
事务A把id=1, name=张三修改为李四,但是还未提交。事务B第一次读,读到是张三,看不见李四。
紧接着事务A提交了事务,事务A在第二次读的时候,读到的是修改后的李四。
这个也叫不可重复读,就是所谓一个事务内对一个数据的两次读,可能读到不一样的值。
3. 可重复读
无论事务A什么时候把张三修改为李四,事务B不管什么时刻读到值,都是事务B刚开启时读到的值。事务开启后对一行读取的值都是一样的。
幻读(不是隔离级别):事务A第一次查询所有数据,就一行id=1。后面事务B插入一行数据id=2,事务A查询时发现2条数据,感觉发生幻觉。
针对数据件数发生变化。
4. 串行化
事务A运行期间,事务B不允许运行。事务A提交完事务后,事务B才开始运行。串行化是为了解决幻读。
MySQL是怎么实现可重复读的?
MySQL是通过MVCC机制来实现的,就是多版本并发控制(Multi-Version Concurrency Control)。
Innodb存储引擎会在每行数据最后增加两个隐藏列,
一个保证行的创建时间,一个保存行的删除时间,但这里存放的不是时间,是事务id,事务id是mysql自己维护的自增,全局唯一。
举例1:
id name 创建事务id 删除事务id
1 张三 101 空
事务id=101的事务查询id=1的这一行,一定能找到创建事务id<=当前事务id的一行。
当事务id=102把id=1的一行删除了,这时id=1的行的删除事务id设置为102.
id name 创建事务id 删除事务id
1 张三 101 102
事务id=101的事务,再次查询id=1的行,仍然能查到。因为创建事务id<=当前事务id,且当前事务id<删掉事务id。
举例2:(同一行被修改)
id name 创建事务id 删除事务id
2 李四 201 空
2 王五 202 空
事务201创建了id=2的数据,事务202修改了id=2的数据,把name修改为王五,这时候事务201仍然可以查询到创建事务id<=当前事务id的数据,
查不到比自己创建事务id大的记录。
MySQL就是通过MVCC实现可重复读,事务可以读取该事务启动时创建事务id的记录,读不到后面事务的版本。
说说MySQL数据库锁的实现原理吗?如果死锁了咋办?
数据库锁有哪些类型?锁如何实现的?MySQL行级锁有哪两种?一定会锁指定行吗?为什么?
悲观锁和乐观锁是什么?使用场景是什么?
MySQL的死锁原理以及如何定位和解决?
1. MySQL锁
锁类型:表锁、行锁和页锁。
myisam一般加表锁,查询时,默认加共享锁,也就是表读锁,别人可以查,但不能写;
myisam写的时候,加表独占锁,也就是表写锁,别人不能读也不能写。现在用的很少。
innodb的行锁分共享锁(S)和排他锁(X)。
共享锁,多个事务可以加共享锁读同一行数据,但别的事务不能写这行数据;
排他锁,一个事务可以写这行数据,别的事务只能读不能写。
innodb表锁,分成意向共享锁,就是加共享行锁的时候,必须先加这个共享表锁;
还有一个意向排他锁,给某行加排他锁的时候,必须先给表加排他锁。这个表锁,是innodb引擎自动加的。
insert、update、delete时,innodb会自动为这一行加行级的排他锁。
select时,innodb啥锁都不加,默认实现可重复读,MVCC机制,所有多个事务随便读一个数据,不会有冲突,大家读的是自己的快照,不涉及锁。
手动加共享锁:
select * from table where id=1 lock in share mode; //id=1这行加了共享锁,其他事务不能修改
手动加排他锁(悲观锁):
select * from table where id=1 for update; //id=1这行加了排他锁,表示该事务准备修改,其他事务被卡住等待。慎用!线上一般不用,容易出问题。
乐观锁:
select id, name, version from table where id = 1; update table set name=’new name’, version = version + 1 where id = 1 and version = 1;
每次修改比较这条数据和之前查出的数据版本号是否一致,一致就修改并且版本号+1,否则就不更新。
乐观锁可以提高并发访问的效率,但是如果出现了冲突只能向上抛出,然后重来一遍;悲观锁可以避免冲突的发生,但是会降低效率。
高并发场景用乐观锁!
死锁:
事务A,B对自己的资源持有锁的同时,又要去请求对方持有的锁,结果谁也拿不到锁,导致死锁。
死锁排查,查看死锁日志,找到对应的sql,找到代码,具体判断为什么死锁。
MySQL的SQL调优一般都有哪些手段?你们一般怎么做?
1. SQL慢,一般就是没有用索引。看执行计划,有没有走索引。
explain select * from table table|type|possible_keys|key|key_len|ref|rows|extra
table: 哪个表
type: 类型 all:全部扫描 const:读常量,最多一条记录匹配 eq_ref:走主键,一般最多一条记录 index:扫描全部索引 range: 扫描部分索引 possible_keys: 显示可能使用的索引
key: 实际使用的索引
key_len: 使用索引的长度
ref: 联合索引哪一列被用到
rows: 一共扫描和返回了多少行
extra: using filesort:需要额外进行排序, using temporary: mysql构建了临时表,比如排序的时候 using where:就是对索引扫描出来的数据再次根据where来过滤出结果
参考资料:
互联网Java工程师面试突击(第三季)-- 中华石杉