本篇文章是Integration Services系列的第四篇,详细内容请参考原文。
回顾增量加载
记住,在SSIS增量加载有三个使用案例:
1、New rows-add rows to the destination that have been added to the source since the previous load.
2、Updated rows-update rows in the destination that have been updated in the source since the previous load.
3、Deleted rows-remove rows from the destination that have been deleted from the source.
在这篇文章中,我们将关注SSIS增量加载功能中的更新行——自从加载到目标之后在源中有变更的行。
添加更新代码
在进行检测更改和更新行之前,我们需要配置另一个测试。使用之前相同的方法更改目标表中的行(dbo.Person)。打开SSMS并连接到你的SQL Server实例。打开一个新的查询窗口,输入下面的T-SQL语句:
use [AdventureWorks2012] go update dbo.Person set MiddleName='Ray' where MiddleName Is Null
按F5执行语句,目标表中将有8499行记录被更新。我们将MiddleName为NULL的值更新为Ray.
打开BIDS然后打开My_First_SSIS_Project解决方案。点击数据流页签,我们需要对上篇文章中加入的查找组件做些更改。双击查找打开查找转换编辑器。
点击列页。在页的右上部分有一些表格形式的表。左边的一个标记为可用输入列。这包含查找转换的输入列列表(记住,查找转换是连接到OLE DB源适配器的输出,这些列就是从那来的)。另一个网格标记可用查找列。这些是连接页上配置的表、视图或查询的列。
在上一篇中,我们将可用输入列的EntityID列映射到可用查找列的EntityID列。我将查找比作是Join,
EntityID列之间的线表示Join子句的ON。这个"ON"定义的匹配准则强迫查找起作用。
在上一篇我们没有选择可用查找列的复选框。可用查找列旁边有复选框,在网格的顶部有一个选择所有的复选框。如果查找转换是一个Join,这些复选框就是用于从连接表中添加列到SELECT子句。点击可用查找列的选择所有复选框。
在可用输入列和可用查找列的下面有一个网格。输出别名用于修改可用查找列返回的列名称。继续Join类比,输出别名类似于查询语句中使用AS来给列设置别名。我喜欢使用LkUp_或Dest_来识别从查找操作返回的行。这让我很容易区分从OLE DB源进来的列和从查找转换返回的列。另外,如果列名相同,SSIS会自动在列名后面加上(1)。我们这里添加LkUp_前缀来区分: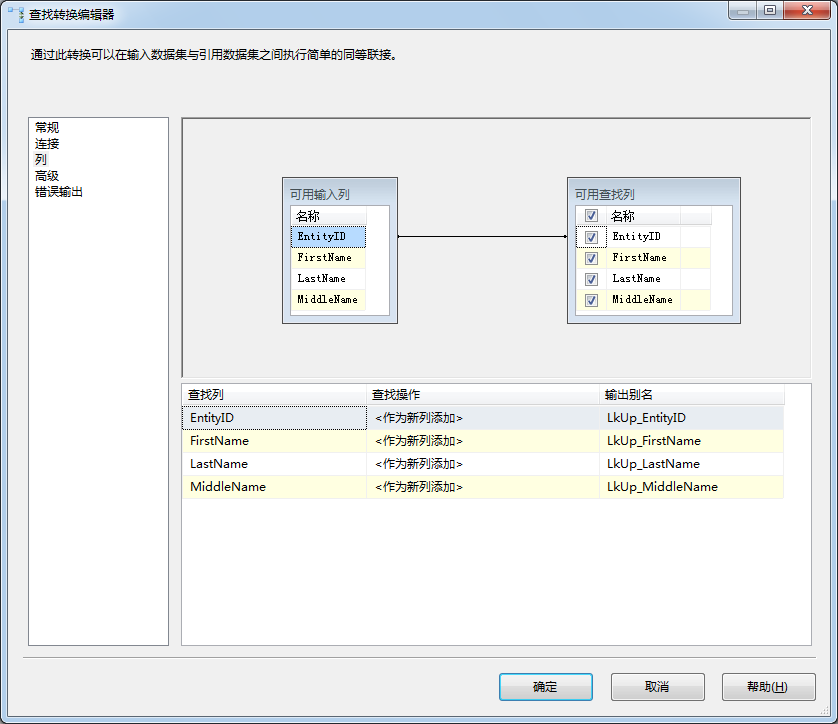
图4.1 查找转换编辑器-勾选可用查找列
查找转换中流入到数据流管道中记录来自OLE DB源适配器,是从Person.Person表加载到数据流中。目标表是dbo.Person,我们通过查找转换编辑器中的连接页配置访问。查找转换打开目标表,尝试匹配存在于数据流管道与目标表中的记录。当发现没有匹配到时,无匹配项的行将被发送到无匹配输出。
我们修改了查找转换配置,安查找转换在源和目标表中的EntityID列找到匹配时,会将目标表中的EntityID、FirstName、LastName和MiddleName列返回出来。在它们流经查找转换时,这些列会添加到数据流记录中。
接下来我们在数据流画布添加条件性拆分和OLE DB命令组件。点击查找转换,将绿箭头拖放到条件性拆分: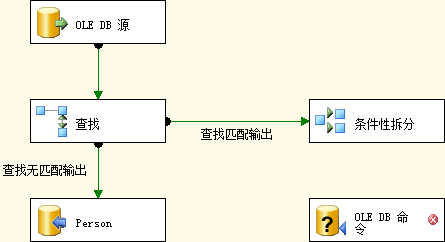
图4.2 添加条件性拆分和OLE DB命令
查找转换唯一可用的绿色数据流路径是查找匹配输出,因此,这次没有提示我们选择输出,默认就是查找匹配输出。除了它们所包含的数据,查找转换的无匹配输出和匹配输出还有其他的不同,最大的不同是返回的列。
我将会向你展示查找转换输出会把查找列添加到源行。首先让我们查看输入列。右击OLE DB源与查找转换之间的数据流路径,选择编辑:
图4.3 编辑OLE DB源与查找之间的数据流路径
当打开数据流路径编辑器后点击元数据页,路径元数据如图4.4所示:
图4.4 OLE DB源与查找之间数据流路径的元数据
查找转换的列来自OLE DB源。关闭这个数据流路径编辑器,右击查找转换和OLE DB目标之间叫做查找无匹配输出的数据流路径,选择编辑打开数据流路径编辑器,点击元数据页: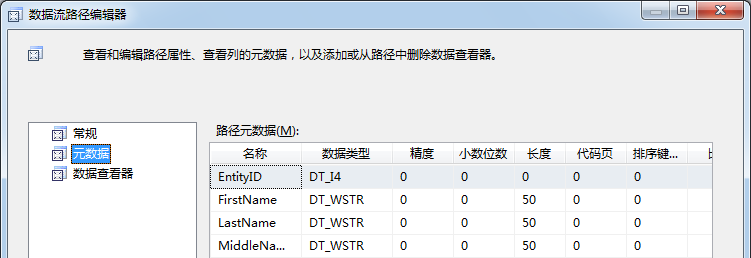
图4.5 查找与OLE DB目标之间数据流路径的元数据
上一篇我们看过这个元数据。查找转换的无匹配输出的元数据和查找转换输入的元数据完全相同。这是本身设计的,查找只能传递这些行,通过转换它们不能找到匹配。
因为我们配置了查找转换,在找到匹配记录时会有不同的情况:目标中的列会额外返回。要查看数据流的这些更改,右击查找转换和条件性拆分之间叫做查找匹配输出的数据流路径:
图4.6 查找与条件性拆分之间数据流路径的元数据
在图4.6中很容易发现数据流路径中添加的额外列,因我我们在查找转换匹配操作时增加了别名。关闭数据流路径编辑器。
在上一篇,我们配置查找无匹配输出,没有配置从查找表中返回列。因为在增量加载新行不需要它们,但现在我们需要它们来比较源和目标表中的值。
Change Detection
查找匹配输出中的"匹配"是什么意思?它表示源表(Person.Person-通过OLE DB源适配器加载到数据流任务)中的EntityID列与目标表(dbo.Person-通过查找转换中的连接页访问)中的EntityID列有相同的值。我们知道EntityID列值匹配,但我们不确定是否其他列也匹配,我们需要知道这些。
如果源和目标的所有列值都匹配,源中的记录就没有做任何变更,我们可以在进一步考虑中排除它。如果源中有变更,我们想要捕获那些变更并且应用到目标。这就是增量加载中更新的目标。首先我们要检测不同,其次应用更新。
SSIS中应用Change Detection
打开条件性拆分,当条件性拆分转换编辑器打开,它展示三部分。左上部分包含两个虚拟文件夹:变量和列:
图4.7 变量与列虚拟文件夹
我们主要操作列,因此展开图4.7中的列虚拟文件夹。为了检测源和目标中列的不同,我们将对比FirstName、LastName、MiddleName列。为什么我们不对比EntityID列?这些行的EntityID列已经匹配上,在查找中我们就是用源和目标表的EntityID列作为Join中的on联接条件。
首先让我们对比FirstName,点击列列表中的FirstName并拖动到条件性拆分转换编辑器下方的条件列:
图4.8 将FirstName拖放到条件
当你在条件列放开FirstName,然后点击其他地方就会发生验证。文本会变红因为验证失败。这里为什么会失败?条件必须返回布尔值——真或假。FirstName是一个字符串,此时如果你点击确定试图关闭转换编辑器,你将得到一个错误信息。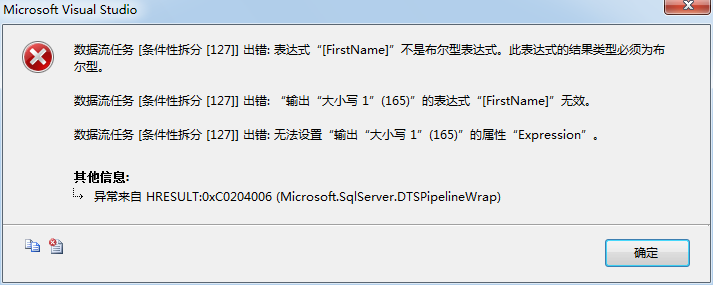
图4.9 错误信息
点击确定,我们还没结束。在条件性拆分转换编辑器的右上部分包含有SSIS表达式语言。
我们想检测FirstName和LkUp_FirstName不同。在SSIS表达式语言,展开运算符虚拟文件夹,选择不等于操作:
图4.10 运算符虚拟文件夹下的不等于
点击不等于操作并拖动到条件表达式下FirstName列的右边,然后从列虚拟文件来下拖动LkUp_FirstName放到条件表达式下不等于的右边:
图4.11 条件中添加不等于及LkUp_FirstName
因为表达式现在可以得出一个布尔值,它通过验证并且字体变黑。如何检查的呢?源和目标中EntityID列匹配的记录中检测FirstName与LkUp_FirstName是否匹配。如果FirstName不同,源和目标就存在差异。因为目标通常是滞后的源,它们假设源有更新、更好、更准确的数据。如果是这样的话,我们需要把数据输入到目标。
因为在测试查询中没有对FirstName列做任何更改,这个条件返回总是假:因为他们总是相等。我们需要添加条件表达式获取所有变更。让我们在变化检测条件表达式中分离这部分,用括号包住这段表达式:
图4.12 用括号包住表达式
接下来我们要添加MiddleName。我们停下思考下我们需要什么,我们要检测源和目标中任何列差异。只要一个改变,就足以触发目标上的更新。因此我们想要检查一列或另一列不相等。"Or"操作符合需求。
下拉SSIS表达式语言列表,将逻辑或拖放到表达式的右边:
图4.13 运算符虚拟文件夹下的逻辑或
在逻辑或的后面添加括号如图4.14所示:
图4.14 添加逻辑或及括号
从转换编号器左上部分的列虚拟文件夹将MiddleName拖放到括号中,在MiddleName列的右边拖放一个不等于操作,然后拖入LkUp_MiddleName。
继续按照之前的步骤将LastName加入到条件表达式,最终的条件表达式如图4.15所示:
图4.15 最终的条件表达式
在我们关闭转换编辑器前,我们重命名输出名称为Updated Rows。
你可能会被表达的不必要的括号所困扰,在图4.16中,我清理掉表达式中不必要的括号和空格:
图4.16 总体表达式
我们完成了什么?查找转换匹配输出传送到条件性拆分转换。这意味着这些行的EntityID列和LkUp_EntityID列有相同的值。EntityID和LkUp_EntityID列被用于查找转换执行匹配操作。我们在条件性拆分转换中配置了一个叫做Updated Rows的条件。Updated Rows条件分离FirstName、MiddleName、LastName列有差异的行。
注意:条件性拆分转换将行定向到不同的输出。当我们定义了一个条件,我们还创建了一个新的输出,一个新的路径,数据可以从条件性拆分转换中流出。
源中和目标中列相同的行到哪去了呢?指定将输入行定向到特定的输出时所要遵循的条件。如果输入行不符合任何条件,则该行被定向到条件性拆分默认输出。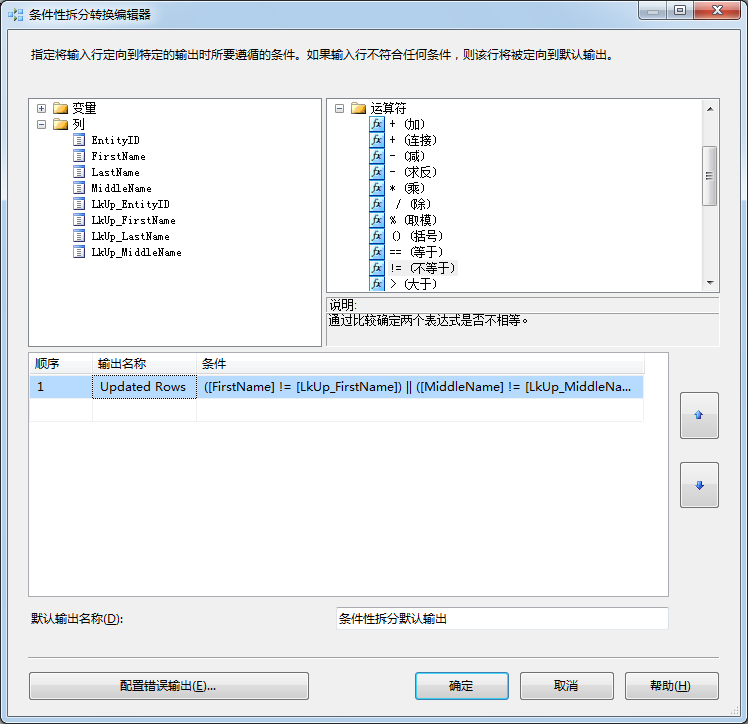
图4.17 配置后的条件性拆分转换编辑器
点击确定关闭条件性拆分转换编辑器。点击条件性拆分然后拖动绿色箭头到OLE DB命令,在选择输入输出中选择Updated Rows: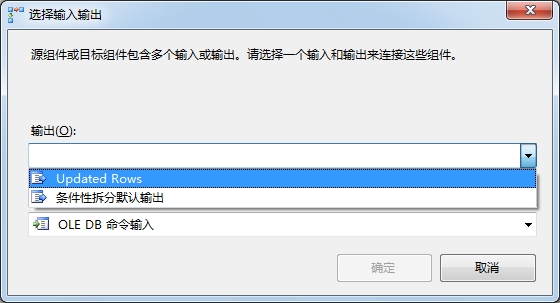
图4.18 选择输入输出
此时你的数据流任务应该如图4.19所示: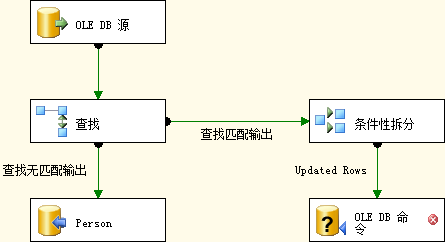
图4.19 数据流画布
我们将用OLE DB命令转换执行更新目标表中的行。
我们检测源与目标存在差异的行,通过Updated Rows输出将更新的行发送给OLE DB命令转换。是时候配置OLE DB命令的更新功能了。右击OLE DB命令转换打开OLE DB命令的高级编辑器。
在OLE DB命令的高级编辑器"连接管理器"页签,设置OLE DB连接管理器到127.0.0.1,5377.AdventureWorks2012.sa。点击"组件属性"页签,下拉到自定义属性,点击SqlCommand的属性值文本框中的省略号打开"字符串值编辑器"。在字符串值键入下面T-SQL语句:
update dbo.Person set FirstName = ? ,MiddleName = ? ,LastName = ? where EntityID = ?

图4.20 OLE DB命令组件属性
在OLE DB,用问号(?)代表参数占位符。我们将在下一个标签中映射这些参数。单击确定以关闭"字符串值编辑器"。单击"列映射"页签:
图4.21 OLE DB命令列映射
The question marks form a zero-based array.这意味着param_0代表第一个问号,param_1代表第二个问号,等等。我们通过拖动可用输入列中的列,将它们释放到可用目标列中的映射参数上。从源和目标表中的列存在于可用输入列。记住,前缀为LkUp_的列实际上是查找转换返回的目标数据。所以我们只要映射源表的列(因为我们假设源包含最新的数据)。因为第一个?映射FirstName,我们将FirstName映射Param_0,MiddleName映射Param_1,LastName映射Param_2,EntityID映射Param_3: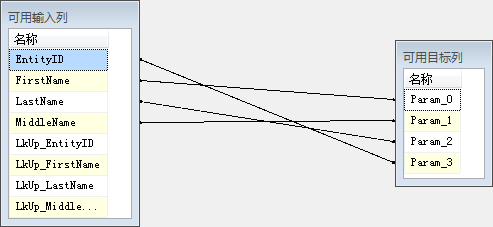
图4.22 OLE DB命令映射列
你已经完成参数映射和OLE DB命令配置。点击确定按钮关闭OLE DB命令的高级编辑器。你的数据流任务看起来应该如4.23所示:
图4.23 数据流画布
让我们测试一下,按F5启动调试器:
图4.24 执行过程中的数据流任务
…它几乎可以工作。让我们在进度标签检查错误信息。我发现了错误,但很难阅读:
图4.25 进度标签错误信息
但是可以右击错误信息选择复制消息文本:
[条件性拆分 [127]] 错误: “输出“Updated Rows”(165)”的表达式“(FirstName != LkUp_FirstName) || (MiddleName != LkUp_MiddleName) || (LastName != LkUp_LastName)”的计算结果为 NULL,但“组件“条件性拆分”(127)”要求布尔值结果。请修改输出中的错误行处理设置,以将此结果视为 False (忽略失败),或者将该行重定向到错误输出(重定向行)。表达式结果必须是用于“条件性拆分”的布尔值。NULL 表达式结果不对。
问题出现在我的表达式上面。某些表达式的计算为NULL。当你验证等于/不等于,并且其中有一个为NULL时,这个结果不会是真/假,而是NULL。因为NULL不是一个布尔值,所以条件表达式失败。
我将从源表:Person.Person,执行三个查询搜索NULL:
use [AdventureWorks2012] go select * from Person.Person where FirstName Is Null select * from Person.Person where MiddleName Is Null select * from Person.Person where LastName Is Null
执行这些查询告诉我源表中8499行的MiddleName列是NULL。记得在开始我们更新过目标表中MiddleName列为NULL的记录,正好是8499行。
为了解决这个问题,停止BIDS调试器然后打开条件性拆分转换编辑器。我们需要把NULL值分离到一种方法中以允许我们比较MiddleName列的值而不出错。我们使用SSIS表达式语言中的IsNull()函数。这个函数并不是T-SQL中我们熟知的IsNull()。T-SQL函数使用另一个值代替NULL。SSIS表达式语言的IsNull()函数是一个NULL值的检测,它返回一个布尔结果(真/假)。我们组合IsNull()和条件操作来检查NULL并返回它们是否存在。更新Updated Rows条件语句如下形式:
(FirstName != LkUp_FirstName) || ((ISNULL(MiddleName) ? "Humperdinck" : MiddleName) != (ISNULL(LkUp_MiddleName) ? "Humperdinck" : LkUp_MiddleName)) || (LastName != LkUp_LastName)

图4.26 更新的的Updated Rows条件语句
我们是如何处理NULL?首先我们用ISNULL(MiddleName)检测它们。ISNULL()函数返回真/假,并且是条件操作的"条件"。条件操作函数格式是<Condition>?<True>:<False>. 如果MiddleName是NULL,条件操作中True部分(本例Humperdinck)将会应用。如果MiddleName不是NULL,条件操作中False部分(本例MiddleName)将会应用。因此如果MiddleName是NULL,我们用Humperdinck代替作对比。如果MiddleName不是NULL,我们直接用MiddleName的值做对比。
LkUp_MiddleName列使用相同的逻辑,当LkUp_MiddleName是NULL,我们用Humperdinck代替,如果不是NULL,我们用非空的值做对比。这样我们就避免了NULL != NULL这种表达式。
这里需要注意的是:Humperdinck不能是一个可用的MiddleName的值。考虑加载的名称数据中没有MiddleName会出现什么情况。比如John Smith。后来,他在网上或通过客服代表更新自己的姓名信息。如果John的MiddleName是Humperdinck那会发生什么呢?存储在目标表中的MiddleName值是空的。源表已更新为Humperdinck。当条件性拆分Updated Rows条件应用于这一行,对不等式的MiddleName侧不为空,因此使用MiddleName(Humperdinck)比较。不平等LkUp_MiddleName侧为空,因此替换为Humperdinck。不平等按照设计进行对比,但未能确定这些值的不同。
点击确定关闭条件性拆分转换编辑器,按F5重新执行SSIS包:
图4.27 重新执行SSIS包
我注意这个执行一些趣事。首先,它成功执行;其次,它花费了一段时间。在我的电脑上,它花费了近2分多钟。
图4.28 SSIS包执行时间
为什么执行花费那么长时间?大部分的时间花费在OLE DB命令中的更新语句上。OLE DB命令每次只处理一行。等效于SSIS游标,并且SQL Server不喜欢基于行的操作,他们执行太慢。
基于集合的更新
是否有方法避免基于行的操作?当然存在。让我们看下如何使用。如果你的SSIS包还在运行,把它停止。数据流任务中点击OLE DB命令然后删除它,在它的位置从工具箱拖一个OLE DB目标,并将条件性拆分的输出Updated Rows连接到OLE DB目标: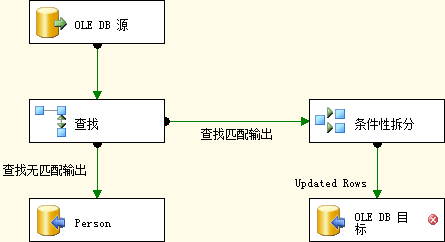
图4.29 添加OLE DB目标
将OLE DB目标重命名为StageUpdates。右击OLE DB目标打开编辑器。连接管理器下选择127.0.0.1,5377.AdventureWorks2012.sa,接受默认的数据访问模式"表或视图-快速加载"。在表或视图名称的旁边点击新建:
图4.30 OLE DB目标编辑器
在我们点击确定之前我们做些调整,表名来自OLE DB的名称-这就是开始我们重命名它的原因。数据定义语句的列,是从数据流路径的元数据读取的。它包括将SSIS数据类型转换成SQL Server数据类型。
在我们执行前,将LkUp_前缀的列移除。我们只需保存源中的数据来更新。最终语句修改为:
CREATE TABLE [StageUpdates] ( [EntityID] int, [FirstName] nvarchar(50), [LastName] nvarchar(50), [MiddleName] nvarchar(50) )
点击确定,在AdventureWorks2012库下就会创建StageUpdates表。注意OLE DB目标编辑器的确定按钮是灰色的,并且在底部有一个警告信息。点击映射页: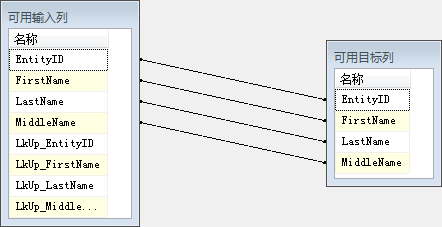
图4.31 OLE DB目标编辑器映射页
列自动匹配因为列名和数据类型相同。类型相匹是因为可用目标列是从可用输入列的元数据构建的。点击确定按钮。你的数据流画布如图4.32所示:
图4.32 数据流画布
在执行前我们需要处理StageUpdates中的行。现在需要更新的数据保存在StageUpdates表。我们需要这些数据应用到dbo.Person表。点击控制流页签然后画布添加一个执行SQL任务。点击数据流任务将绿箭头拖动到执行SQL任务:
图4.33 添加执行SQL任务
我们将在执行SQL任务中执行一个基于集合的更新。不像每次只loop一行记录,基于集合的几乎可以一次把所有更新应用到目标表。
右击执行SQL任务打开执行SQL任务编辑器。在常规页,修改名称属性为"Apply Staged Updates",修改连接属性为127.0.0.1,5377.AdventureWorks2012.sa。点击SQLStatement属性的省略号打开"输入SQL查询",并键入下面T-SQL语句:
update dest set dest.FirstName = stage.FirstName , dest.MiddleName = stage.MiddleName , dest.LastName = stage.LastName from dbo.Person dest join dbo.StageUpdates stage on stage.EntityID = dest.EntityID
这个语句将StageUpdates和dbo.Person联接,并将更新从Stage应用到目标。在我们执行这个包之前,让我们重置目标表中的数据,执行下面T-SQL语句:
use [AdventureWorks2012] go update dbo.Person set MiddleName='Ray' where MiddleName Is NULL
返回到BIDS,按F5执行SSIS包。我的控制流如下所示: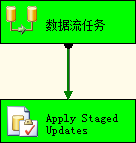
图4.34 控制流画布
我的数据流任务如下所示:
图4.35 数据流任务
在BIDS的进度页签显示了改进后的执行时间:
图4.36 改进后的执行时间
2.792秒远好于2分钟!
我们仍然需要对StageUpdates表做更多处理。当前的配置会继续往StageUpdates表中保存记录然后应用于更新。我们可以在更新应用到dbo.Person目标表之后,删除StageUpdates表中的记录。但如果在执行过程中发生一些"坏"的情况,执行过程中保留这些记录可以让我有更多的数据点来检查线索。因此,我们在数据流任务加载前清空StageUpdates表,让StageUpdates表中的记录在执行期间一直保留。
为了达到这个目的,首先停止BIDS调试器。然后在控制流画布添加另一个执行SQL任务,连接执行SQL任务到数据流任务: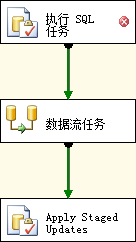
图4.37 添加执行SQL任务
双击打开执行SQL任务编辑器。配置常规页如图4.38所示:
图4.38 配置常规页面
下面我们准备执行,点击F5执行SSIS包:
图4.39 控制流画布
数据流任务执行一个增量加载:
图4.40 数据流画布
总结
在这篇文章中,我们从一个存在于目标的数据不会有变更的SSIS增量加载开始。这种很适用于给定日期的高温数据,或每天货币兑换率的案例。有些数据是随着时间变化的。为了捕捉这些变化,我们需要检测源和目标之间的差异,并将更新应用到目标。本篇文章覆盖了几种更新的方法,越往后面效率越高。