分布式存储-Redis实战&常见问题解决
前面讲了一些Redis的使用场景和数据类型,本章会聊到:
- 一个抽奖的例子来阐述redis如何被应用去解决实际问题(代码有点多,不适合放在博文中,如需请留言,我可以发送),并且会使用到前面并发模块聊的CountDownLatch和springBoot中的事件去异步缓存数据,和异步等待。
- 常见的一些使用redis带来的问题,比如缓存穿透、缓存雪崩、以及数据库和redis中数据不一致的问题,和布隆过滤器的一些底层思想(位图)
- 常用的redis客户端和他们的底层实现
- 自己动手实现一个Redisclient
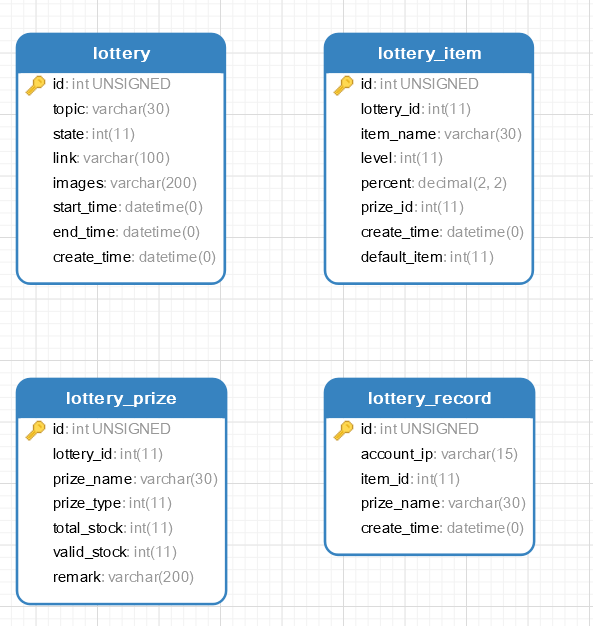
Redis抽奖实现
整体流程:
设计思路:当一个请求过来的时候,会携带一个活动id
- 缓存奖品信息:我们会使用这个活动id去查询数据库,并把查询到的数据缓存在redis中(这个步骤是异步的,我们用一个CountDownLatch去对他进行控制,缓存完成后,给count-1,后续需要redis中数据的流程就可以继续处理)
- 开始抽奖:这是一个简单的区间算法,在lottery_item中有对于每个奖品的概率比。从redis中拿到所有的奖项,如果没有则从数据库中获取(因为上面缓存的那一步骤是异步的,可能这个时候还有缓存成功)。我们根据随机数去落到我们设置好的概率区间中(区间越大,抽到某个奖品的概率越大)
- 发放奖品:我们的奖品类型不同 (lottery_prize#prize_type)根据不同奖品的类型,走不同的逻辑,比如我们有的奖品要发送短信,有的奖品不要,我们就定一个模板方法,然后不同类型的奖品走不同类型的发送逻辑。
- 扣减库存:我们前面已经异步缓存了数据到redis中,那这里直接使用incur的命令(之前说,这个命令是原子的,所以不会产生安全问题),我们可以先扣减redis中,然后进行数据的内存扣除
SpringBoot中使用方法(Lettuce)
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> </dependency>redis: port: 6379 host: ip lettuce: pool: max-active: -1 max-idle: 2000 max-wait: -1 min-idle: 1 time-between-eviction-runs: 5000@Autowired RedisTemplate<String,String> redisTemplate;
Redis的客户端
常见的:Jedis、Redission、Lettuce(上面给的pom)
我们发送一个命令(set n v)到redis上的时候,使用抓包工具发现
这里的$*表示key的长度 ,比如:$3表示set的长度是3 *3 表示我们传递了三个参数给redis
那解析下来的命令就是:*3 $3 SET $1 n $ v,** 那是不是证明只要我们符合这样的编码协议就可以和redis交流了呢
定义get set 命令
 View Codepublic class CommandConstant { public static final String START="*"; public static final String LENGTH="$"; public static final String LINE=" "; //这里提供两个命令 public enum CommandEnum{ SET, GET } }
View Codepublic class CommandConstant { public static final String START="*"; public static final String LENGTH="$"; public static final String LINE=" "; //这里提供两个命令 public enum CommandEnum{ SET, GET } }封装api
View Codepublic class CustomerRedisClient { private CustomerRedisClientSocket customerRedisClientSocket; //连接的redis地址和端口 public CustomerRedisClient(String host,int port) { customerRedisClientSocket=new CustomerRedisClientSocket(host,port); } //封装一个api 发送指令 public String set(String key,String value){ //传递给redis,同时格式化成redis认识的数据 customerRedisClientSocket.send(convertToCommand(CommandConstant.CommandEnum.SET,key.getBytes(),value.getBytes())); return customerRedisClientSocket.read(); //在等待返回结果的时候,是阻塞的 } //获取指令 public String get(String key){ customerRedisClientSocket.send(convertToCommand(CommandConstant.CommandEnum.GET,key.getBytes())); return customerRedisClientSocket.read(); } //这里按照redis的要求格式化 就是前面抓包后拿到的格式 *3 $3 SET $1 n $ v public static String convertToCommand(CommandConstant.CommandEnum commandEnum,byte[]... bytes){ StringBuilder stringBuilder=new StringBuilder(); stringBuilder.append(CommandConstant.START).append(bytes.length+1).append(CommandConstant.LINE); stringBuilder.append(CommandConstant.LENGTH).append(commandEnum.toString().length()).append(CommandConstant.LINE); stringBuilder.append(commandEnum.toString()).append(CommandConstant.LINE); for (byte[] by:bytes){ stringBuilder.append(CommandConstant.LENGTH).append(by.length).append(CommandConstant.LINE); stringBuilder.append(new String(by)).append(CommandConstant.LINE); } return stringBuilder.toString(); } }连接redis
View Codepublic class CustomerRedisClientSocket { //这里可以使用nio private Socket socket; private InputStream inputStream; private OutputStream outputStream; public CustomerRedisClientSocket(String ip,int port){ try { socket=new Socket(ip,port); inputStream=socket.getInputStream(); outputStream=socket.getOutputStream(); } catch (IOException e) { e.printStackTrace(); } } //发送指令 public void send(String cmd){ try { outputStream.write(cmd.getBytes()); } catch (IOException e) { e.printStackTrace(); } } //读取数据 public String read(){ byte[] bytes=new byte[1024]; int count=0; try { count=inputStream.read(bytes); } catch (IOException e) { e.printStackTrace(); } return new String(bytes,0,count); } }测试
View Codepublic class MainClient { public static void main(String[] args) { CustomerRedisClient customerRedisClient=new CustomerRedisClient("ip",6379); System.out.println(customerRedisClient.set("customer","Define")); System.out.println(customerRedisClient.get("customer")); } }结果 +ok(redis返回的成功报文) $6(返回的value是6的长度)
根据上面我们自己实现的中间件,我们可以悟出,从这些层面选择中间件:
- 通信层面的优化:当我们获取返回结果的时候是阻塞的(我们自己实现的中间件)
- 是否采用异步通信:多线程(效率高)
- 针对key和value的优化 :传递的报文越小,传递的速度肯定更快
- 连接的优化(连接池)
我们发现redisson是提供这些功能做的比较好的,集成网上很多例子,这里不聊了。



使用redis中遇见的问题
【数据库和redis的数据一致性问题】:实际上很难解决强一致性问题,常见有两种操作
- 先更新数据库,再删除缓存(删除缓存就等于更新)推荐
- 更新数据库成功,但是删除缓存失败
- 当数据库更新成功后,把更新redis的消息放在mq中,这个时候一定能保证都更新成功。
- 解析数据库的binary log,然后更新缓存
- 先删除缓存,再更新数据库(不推荐)
- 删除缓存成功,更新数据库失败(看起来没有什么问题,但是看下面的场景):线程A先去删除一个key,线程B去获取这个Key,发现没有数据,那他就去更新Redis缓存,这个时候线程A去更新数据库 。那就会导致数据库的数据是最新的,但是缓存不是最新的
【缓存雪崩】
- 【原因】大量的热点数据同时失效,因为设置了相同的过期时间,刚好这个时候请求量又很大,那这个时候压力就到了数据库上,从而就导致了雪崩。
- 【方案】 这是几个设置过期的命令,(我们可以给key设置不同的过期时间,这样就能有效地避免雪崩,或者热点数据不设置过期时间 )
- 【redis key 过期实现原理】想一下redis是如何实现过期的,如果我们存储的数据库十分巨大,redis怎么精确的知道那个key过期了?并且对他进行删除呢?
- 想法:我们给去key每个key设置一个定时器,一个个进行轮询。性能太差了!!
- Redis对过期key的做法:
- 存储:实际上redis使用了一个hash的结构进行存储,对你设置的过期的key单独用一个value存储了一个过期时间
- 删除:
- 被动删除:当我们使用get命令的时候,他去查询他存储的我们传递的过期时间和电脑时间对比,如果过期,则进行删除
- 主动删除:随机抽取20个key,删除这20key中已经过期的key,如果发现这20个key中有20%的key已经过期了,那么就再次抽取20个key,用这个方式循环。
【缓存穿透】:
- 【原因】:Redis和数据库中都不存在查询的数据,那这就是一次无效查询,如果有人伪造了很多请求,那可能会引发数据库宕机,因为redis中没有数据,请求肯定就请求到数据库,这就叫缓存穿透
- 【方案】:使用布隆过滤器
- 【流程】:
- 项目在启动的时候,把所有的数据加载到布隆过滤器中
- 【实现】:
- 使用guava
<dependency> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> <version>21.0</version> </dependency>- 程序初始的时候加载数据到布隆过滤器中
- 客户端访问时增加验证
@GetMapping("/bloom/{id}") public String filter(@PathVariable("id")Integer id){ String key=RedisKeyConstants.CITY_KEY+":"+id; if(BloomFilterCache.cityBloom.mightContain(key)){ return redisTemplate.opsForValue().get(key).toString(); } return "数据不存在"; } public class BloomFilterCache { public static BloomFilter<String> cityBloom; }- 剖析布隆过滤器:布隆过滤器是一种空间利用率极高的数据结构,他的底层实际上并不存储我们缓存的元素的内容,而是存储缓存元素的标记 都是0/1。比如:一个int类型是32位4个字节,32位意味着我们可以存储32个0或者1,那我现在如果要存储32个条数据,只需要一个int类型,到底这是怎么做到的?底层用到了位图
- 一个例子解释位图:
- 现在有32位 【0000 0000 0000 0000 0000 0000 0000 0000】
- 比如存储5这个数字 ->5 的二进制是101 【0000 0000 0000 0000 0000 0000 0010 1000】
- 第二个数字是9 ->9的二进制是 1001 【0000 0000 0000 0000 0000 0010 0110 1000】
- 布隆过滤器引入了多个函数去生成hash数值,我们传入的数据通过这些函数计算,则落入了这32位中。比如 有x y z 三个函数,我们传入了一个的数据,通过这三个函数进行hash换算,落到了 32位中的5 6 9 ,那就把这5 6 9 这几个地方变为1,当我们要查询时候我们之前传递的数据是否存在的时候,再次用这些函数进行换算,如果相关位置是1 则说明数据存在,否则数据则不存在。
- 解析布隆过滤器的参数:传递的 100000000是我们要构建多少个int类型(一个int类型可以存储32位),0.03是误判率(误判率指的就是对我们传递的数据进行hash换算的函数)
