音视频消费的新场景催生了越来越多新的技术需求,从当下的直播、点播、RTC,到未来的 XR 和元宇宙,音视频技术对新场景的支撑越来越趋向于综合性,近年来 AI 算法发展迅猛,但是较好的算法效果往往需要消耗很大的算力资源,这使算法商业化落地面临非常大的挑战。我们应该如何充分发挥软硬一体的能力?如何有效平衡算法效果和性能?
在 LiveVideoStackCon2021 北京峰会,阿里云智能视频云高级算法专家杨凤海,从阿里云视频云的最新场景探索出发,带来了阿里云视频云在虚拟背景、视频超分等方向的最佳创新实践经验分享。
文 | 杨凤海
整理 | LiveVideoStack

本次分享主要分为 5 部分,包括前言、算法层面的创新和优化、软硬件层面的深度优化、未来展望和 QA。
1. 前言
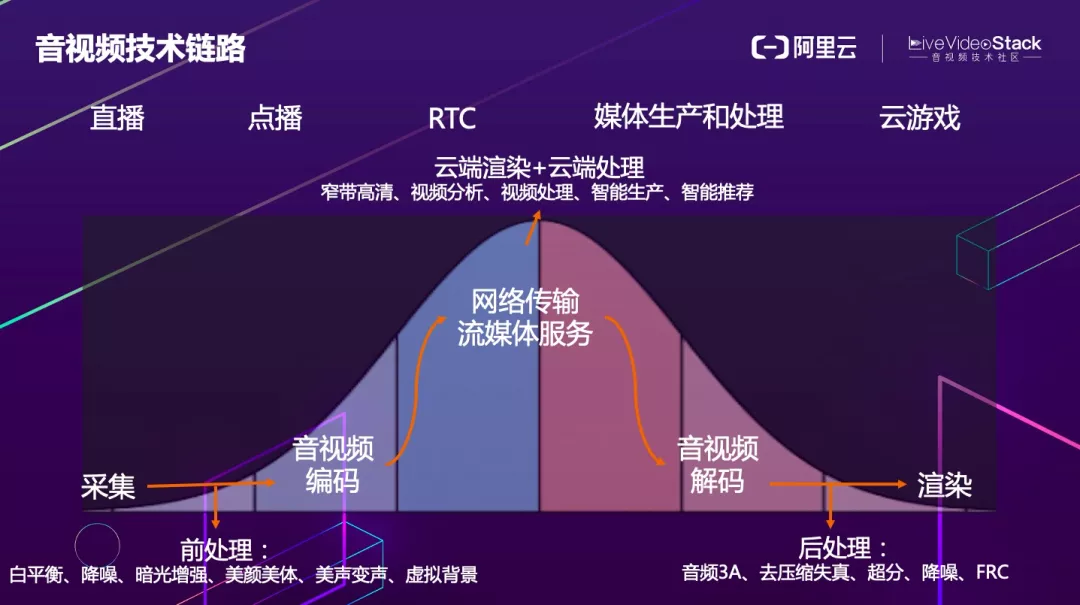
音视频从业务形态上来说包括直播、点播、RTC、媒体生产和处理,以及云游戏、云桌面等。从技术链路上来讲包括采集、编码、传输、云端转码 / 处理 / 渲染、网络分发、接收端解码和渲染,其中涉及到算法的部分包括编码前处理、解码后处理、云端视频处理。
按照算力高低排序,服务端算力最强,端上相对较差,因此可以大致描述为一个正态分布的形式。根据该正态分布曲线,现在大部分算法都部署在云端,少部分会部署在端侧。
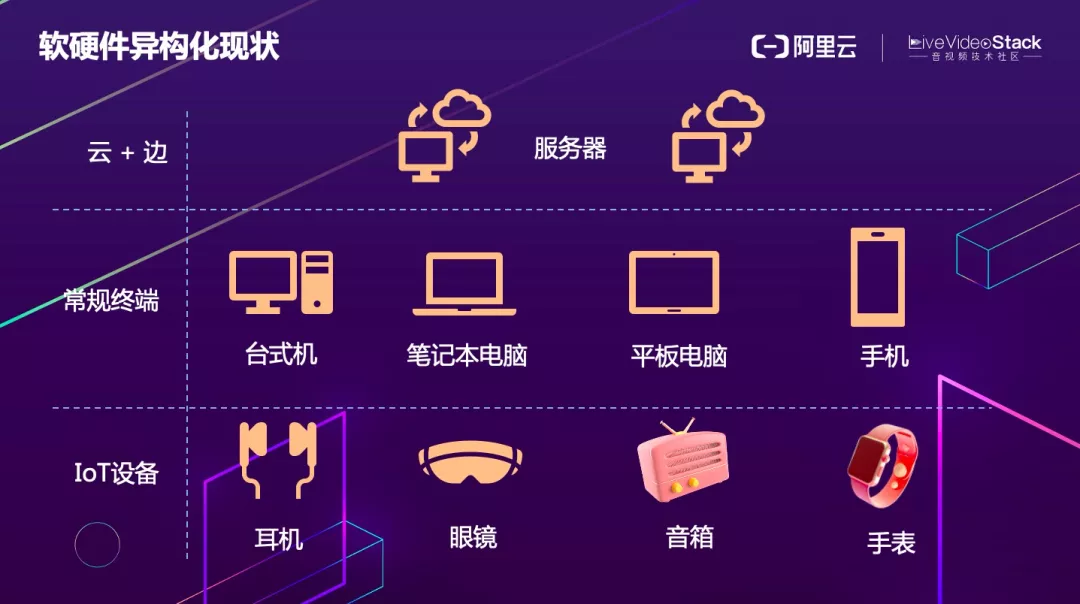
从音视频和算法部署的现状来看,整个软硬件体系是异构的,基本上涵盖了云端服务器和边缘服务器、各种终端设备和 IOT 设备。

从硬件层面来讲,包括 CPU+GPU、CPU+FPGA、CPU+DSP 和 CPU+ASIC 芯片等。涉及到的芯片厂商也非常多,主流的包括 Intel、AMD、ARM、Nvidia、高通、苹果等,操作系统覆盖也比较全面。另外,软件标准、开发编译环境、深度学习的训练和推理框架也千差万别。

如此复杂的异构软硬件环境对算法落地提出了前所未有的挑战,如何充分发挥软硬一体的能力?如何有效平衡算法效果和性能?这是两个必须要解决的问题。
2. 算法层面的创新和优化
下面我将通过虚拟背景和超分两个算法来介绍我们是如何从算法层面做到性能和效果的平衡,从而为业务创造价值的。
虚拟背景

我们先来看下算法的背景,相信大家从去年疫情到现在都体验过线上视频会议、陪娃上网课等,当然没娃的朋友肯定也看过直播、短视频、关注过线上相亲等场景,这些场景大家其实非常希望能够把自己置身到一个虚拟的环境中,一方面可以保护个人隐私,另一方面也能有效的增加趣味性和沉浸式的体验。

了解了算法背景,我们现在来看下如何在业务中落地?
首先是场景可能会非常复杂,光线、噪声、场景(室内、室外、单人 / 多人、会议室、办公区、场馆、居家等)、前景背景边界不清晰、手持物、服装装饰非常多样化;
其次是可用来训练学习的数据非常少,各开源数据集标注标准不同而且精度不满足商用要求,人工标注费时费力;
最后是计算性能方面,云端要求高并发低延时、终端要求低延时低功耗低资源占用。
这就要求我们必须设计一个鲁棒性非常好的算法,并且能够满足不同部署端的性能要求。我们知道区分人像的像素级算法有分割和抠图两大类,当然还有一些细分的领域,例如语义分割、实例分割、视频目标分割(VOS)、全景分割(Panoptic Segmentation)、蓝绿幕抠图、自然场景抠图。
我们应该选择哪一种来进行落地呢?首先要知道我们落地的场景目前主要是教育 / 会议 / 泛娱乐场景,经过效果和性能的综合评估,我们认为针对人像的语义分割可以满足业务诉求。
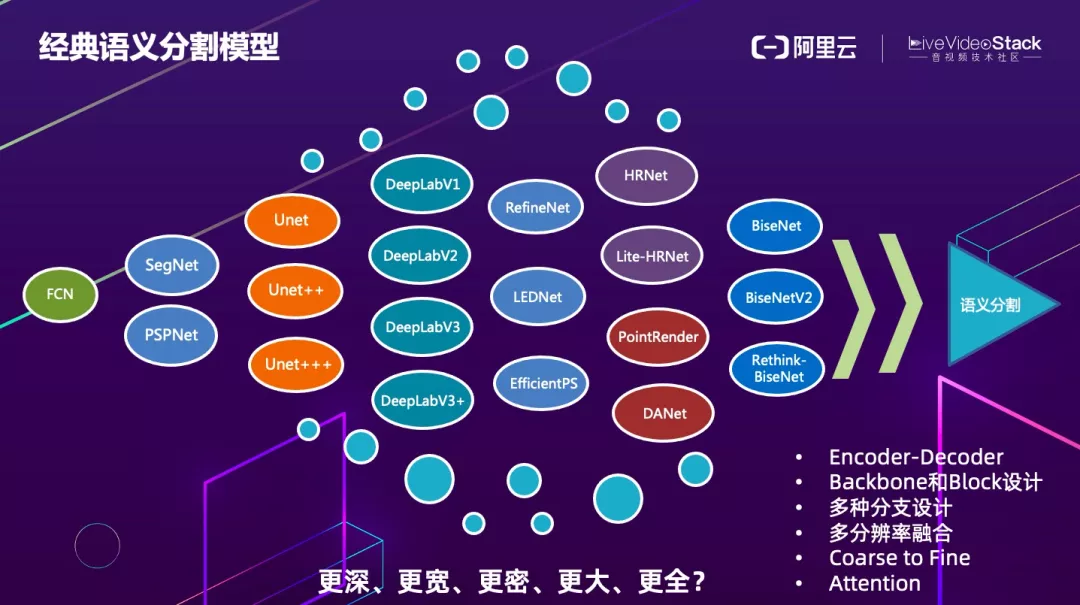
确定好算法方向后,我们首先要做的就是要站在巨人的肩膀上进行创新,那就必须要了解过往多年该领域的算法发展脉络。
可以看到从最初的 FCN 到后来的 segnet、Unet 系列、DeepLab 系列、HRNet 等,从算法设计和创新角度基本上遵循了 Encoder-Decoder 的结构,然后尝试设计不同的 backbone 和 Block 来平衡算法效果和性能,再就是多分枝设计、多分辨率的融合、以及 Coarse2Fine 的结构和各种 Attention 等等。
从发论文的角度很多算法模型会设计的更深(更多层)、更宽(更多并行分支、更多的 channel、更大的 featuremap)、更密集的连接、更大的感受野、获取更多全局信息等,但是从业务落地的角度来讲,这些复杂的算法都很难在端侧设备上实时运行。
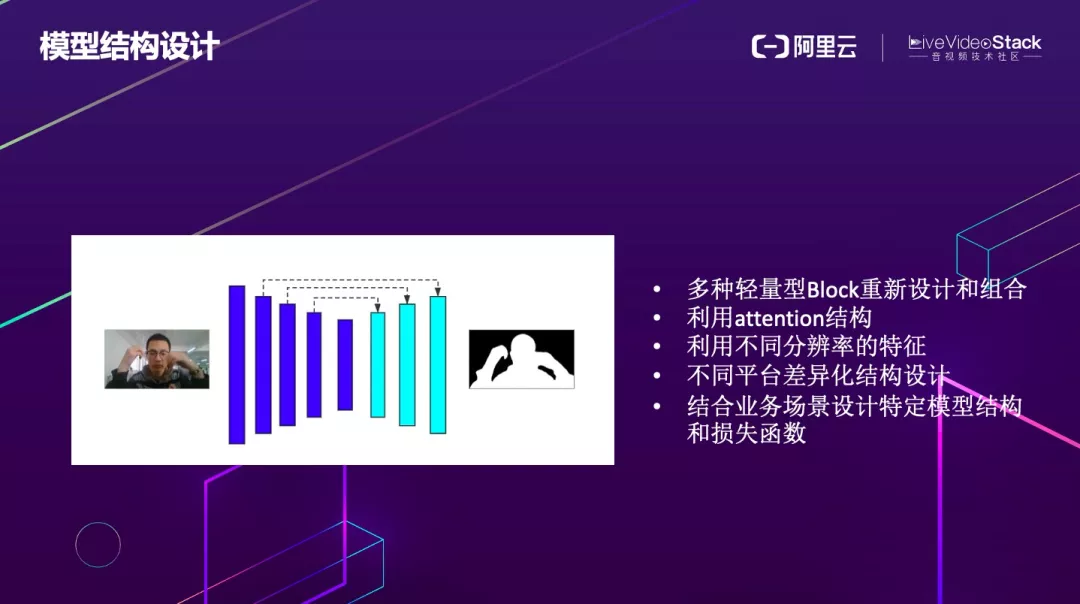
大道至简,我们算法天生是要以满足不同异构平台的部署为目标的,因此我们采用了 Unet 的框架,然后融合了各种轻量化 Block 的设计思路,参考了包括 SqueezeNet、MobileNet、ShuffleNet、EfficienNet、GhostNet 等。
另外充分利用空间维度和 channel 维度的 attention 结构,充分融合多分辨率特征,但同时又要保证计算不被拖慢,针对不同硬件平台差异化的设计、最后就是结合业务场景设计特定结构和损失函数等,包括特定的边缘 loss,在线难样本挖掘等。
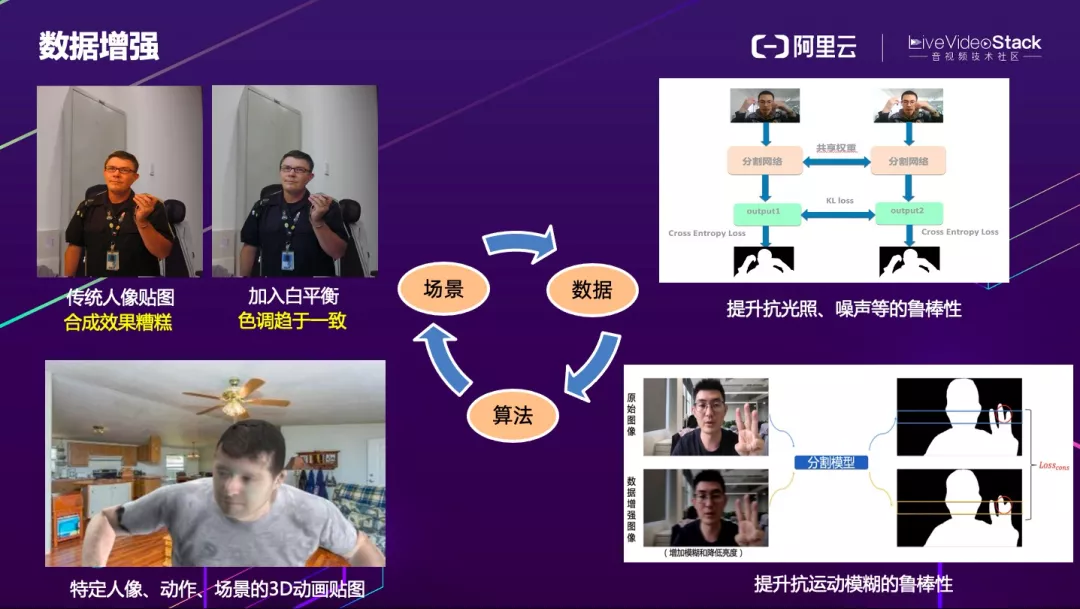
神经网络模型的提升离不开场景和数据,因此在设计算法之前我们首先要定义好当前的业务场景,然后再构建数据集,并通过数据训练迭代算法,算法反过来再通过线上业务实践收集 badcase,重新清洗和扩充数据集,再次 fintune 算法模型,最终场景、数据和算法三者有机结合、循环迭代才能趋于完美。
由于数据集本身的分布有限,因此数据增强是必不可少的。传统人像贴图色温差异大,合成效果糟糕。如果拿这样的数据加入训练,对整体的收益不会很高,而且合成效果不好的话可能还会有副作用。因此我们采取动态白平衡和金字塔融合的策略,来保证前景和背景融合更真实。
由于人工数据采集成本较高,而且也很难覆盖所有人像动作姿态、环境和服饰等,因此像左下角图中所示,我们通过特定人像、动作、场景的 3D 动画贴图来进行数据扩充;右边分别是对光照、噪声和运动模糊的抗干扰能力的提升,我们对原始数据和增强后的数据经网络输出的结果计算一致性 loss,以提升模型的鲁棒性。
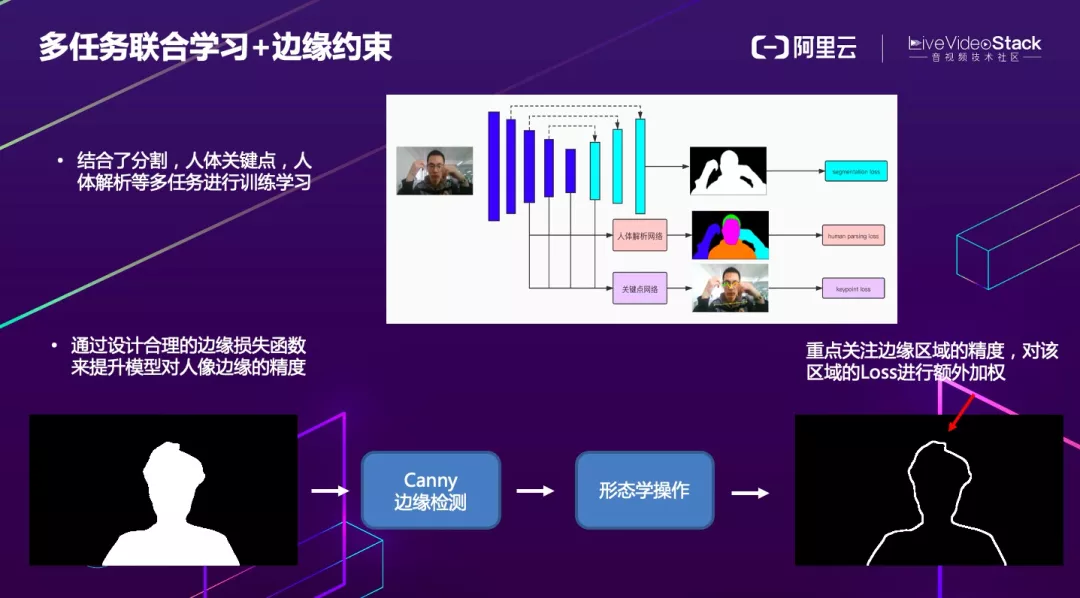
算法设计的再好,实际业务场景中难免会出现一些 badcase。例如人坐在桌前,手臂和身体不是一个连通体,如果单纯使用之前的模型,可能手臂会被误认为背景,为此我们研发了多任务联合学习方法。同时结合人像分割、人体关键点,人体解析等对模型进行多任务联合训练学习 。
最终推理时,其他任务不参与推理,只在训练阶段用于帮助分割模型提取和学习相关信息。这样做不仅可以提升模型效果,还不会增加模型的复杂度。
另外大家或多或少应该都体验过虚拟背景的应用,可以看到不论哪家厂商,在边缘的处理上都不是很好,因此我们针对边缘还专门设计了特殊的 loss 约束,使得边缘精度得到明显改善。

在最终落地时需要对模型进行轻量化处理。常用的方法包括剪枝、压缩、蒸馏、量化和 NAS,这里以蒸馏为例来介绍下我们是如何进行模型轻量化的。
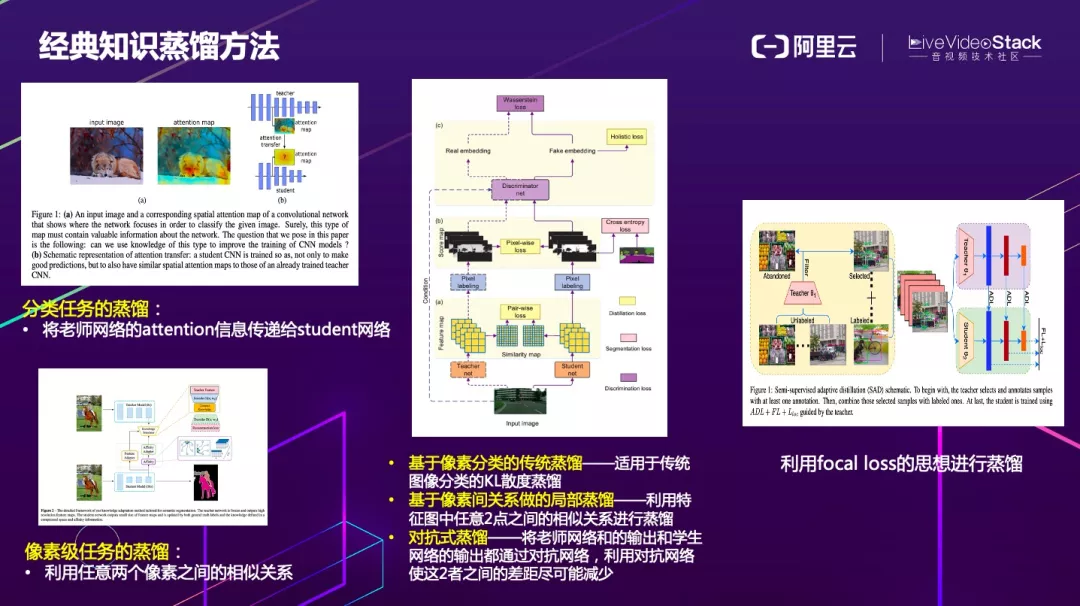
首先来看下知识蒸馏的发展历程,2014 年 Hinton 发布了开山之作 Distill the knowledge in a neural network,简单来说就是分别训练一个复杂的老师网络和轻量的学生网络,然后利用 KL 散度使学生的输出和老师的输出逼近,后来一些改进的文章中也有人讨论了在分类网络中传递的 spatial attention 给学生网络的方法。
蒸馏在分类任务上表现相对较好,但在像素级任务,无论是分割、matting,还是超分,蒸馏都非常难调节。这些年也有论文在论述该问题,比如微软的文章:structured knowledge distillation for semantic segmentation 就提出利用特征图中任意两个像素之间的相似关系进行蒸馏,同时还利用了像素分类的 KL 散度蒸馏、以及基于 GAN 的对抗式蒸馏等。
除此之外,还有论文利用 focal loss 的思想进行蒸馏。首先计算学生网络 loss,对 loss 大的位置赋予更大的权重,最后根据这些权重来计算蒸馏的 loss。
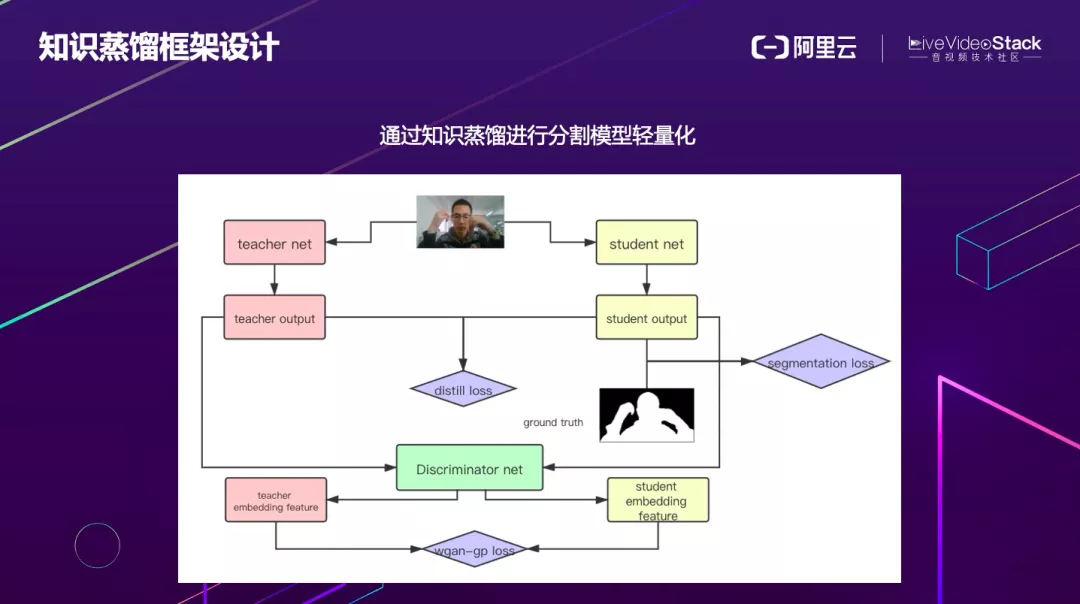
我们充分结合了像素分类的 KL 散度蒸馏和基于 GAN 的蒸馏方法等来进行蒸馏。

这是实际的算法效果,有单人换背景、虚拟课堂、虚拟会议室等,可以在保护隐私的同时为枯燥的会议和课堂等提供一些小小的乐趣。
视频超分辨率算法
目前视频超分算法应用在端上功耗非常大,所以其主要应用在服务端视频超高清场景中,包括 2K 超 4K、4K 超 8K 等。
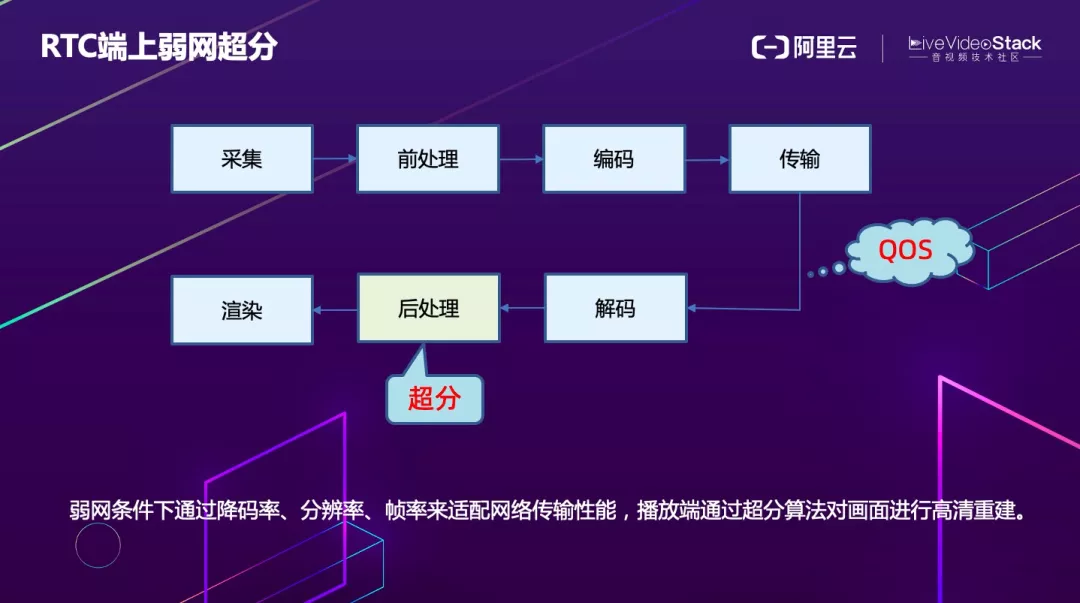
如何在端上进行超分?我们现在落地场景主要为 RTC,RTC 无论是延时、包的大小、功耗还是资源占用要求都很极致。基于 RTC 业务特性,阿里云选择端上弱网场景进行超分。
弱网时,通过 QOS 策略可以把分辨率、码率、帧率降低来满足网络流畅传输的要求。在播放端通过超分算法对画面进行高清重建。这样不仅可以在弱网情况下保证传输质量,还可以使用户获得不错的观看体验。
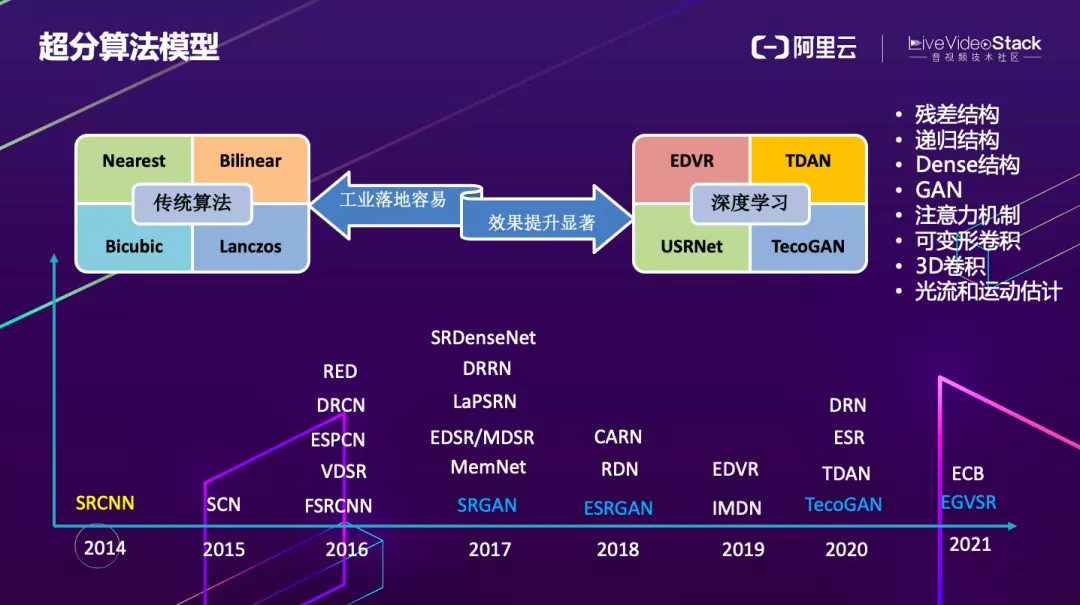
回顾近几年超分模型发展历程。主要分为传统算法和深度学习算法两大类。传统算法就是大家熟知的几种插值算法。从 2014 年的 SRCNN 开始到现在,不断的有新的关于深度学习的论文出现,但是这些论文真正能够在端上跑起来的很少。
通过这些网络结构可以总结提炼出一些设计思路,基本上就是采用残差结构,或者递归结构,亦或者 Dense 结构,还有一种是基于 GAN 的,但是 GAN 在端上实现起来更为困难。为了提取视频帧之间的相关性信息,可以使用 3D 卷积、可变性卷积、光流和运动估计等方法,计算资源消耗同样很大。
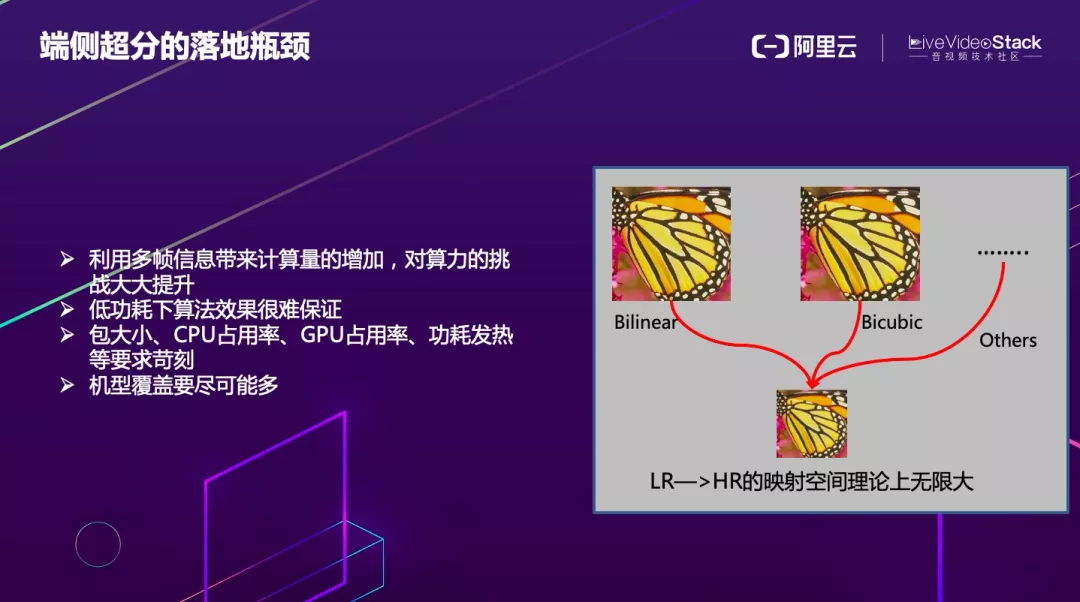
超分算法本身要解决的是个病态问题,无论是从低分辨率到高分辨率,还是从高分辨率到低分辨率,不存在一个确定的映射函数,所以学习起来十分困难,而且在视频中,要利用帧间的信息进行对齐,难以满足在端上的实时性和功耗要求。
在 RTC 的场景下,要在低功耗的前提下保证算法效果,并且对包大小、CPU 占用率、GPU 占用率、功耗发热等要求都十分苛刻。另外,即便覆盖了中高端机型,如果仍然有很大一部分中低端机型无法覆盖,从业务和商业化的角度来讲会损失掉一部分客户,因此我们的目标是要覆盖所有的机型。
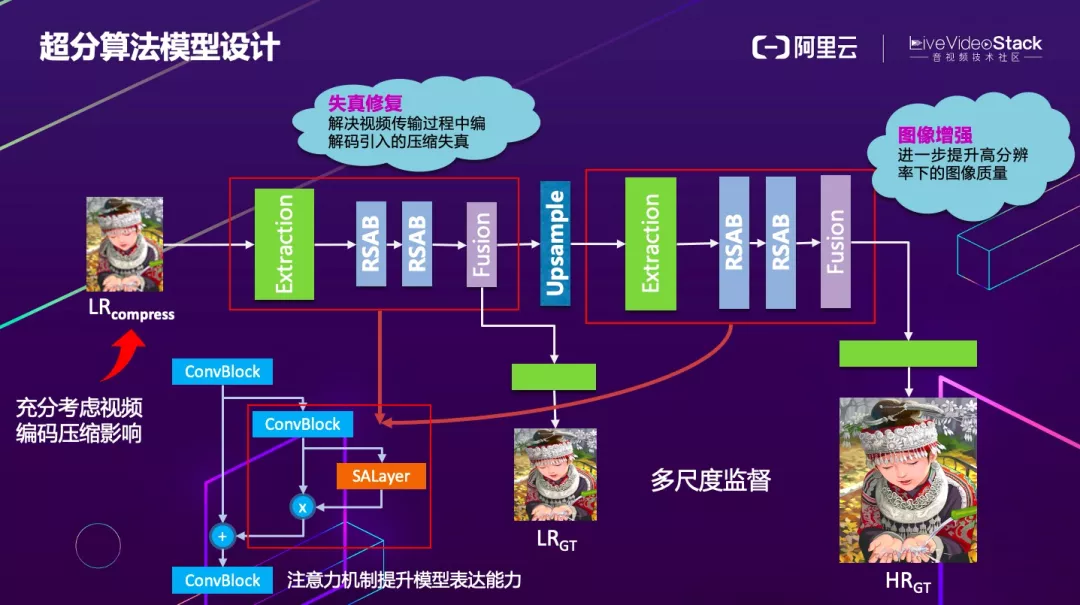
图中大致描述了我们超分的网络结构。我们知道算法离不开真实场景,只有场景化的算法才会有更好的业务价值,在 RTC 场景中,首要考虑的就是编码的压缩以及下采样导致的损失。
我们在设计模型时,就已经将编码的压缩以及下采样的损失考虑进去,在模型前半部分添加了失真修复的模块。在模型的后半部分是对上采样后的图增强来逼近 GroundTruth。两部分都采用了 Attention 的结构辅助特征提取。

对人像和普通画面进行超分相对容易,但是对存在文字、字幕的场景进行超分,文字高频信息不仅在下采样过程中易丢失,同时在编码过程中也极易被破坏,非常容易出现 badcase,我们针对该问题进行了一系列优化。
首先会对文字进行大量的数据增强,包括字体、颜色、角度等,另外,引入针对边缘优化的 EdgeLoss,能够有效地提升文字超分效果。
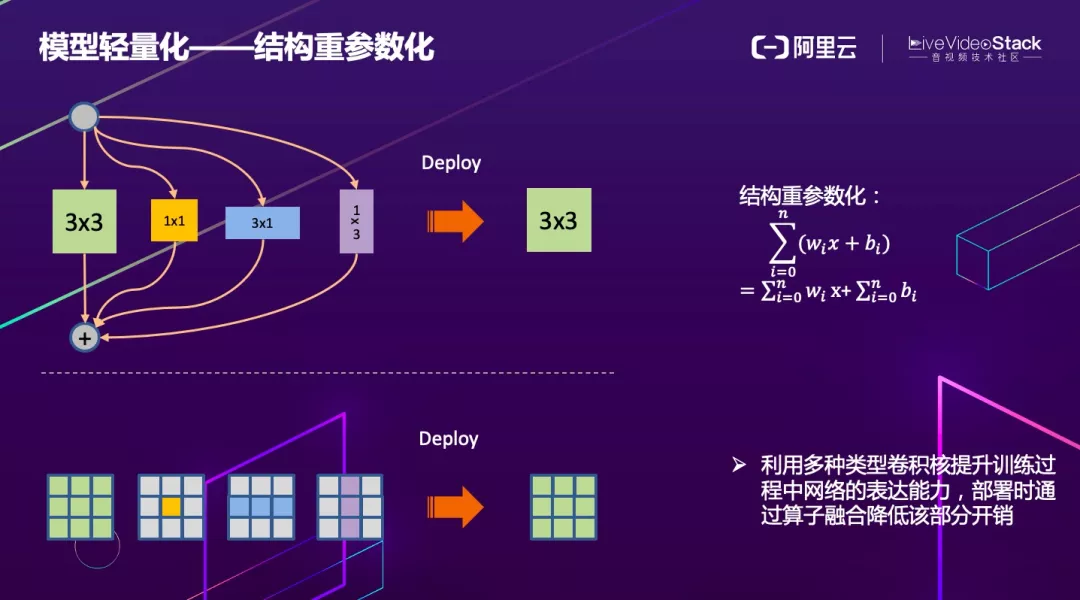
在落地时轻量化一直是需要考虑的问题。我们使用结构重参数化来设计网络,结构重参数化的本质就是通过并联一些特征提取分支进行训练。
例如本身只存在一条 3x3 的连接提取特征,可以并行几条其他的卷积,最终推理时通过结构重参数化公式进行合并。虽然在训练时会增加大量的计算量,但是在推理时完全没有影响,而且可以提取更多的信息和特征。通过这种结构,我们很好的平衡了算法效果和功耗。
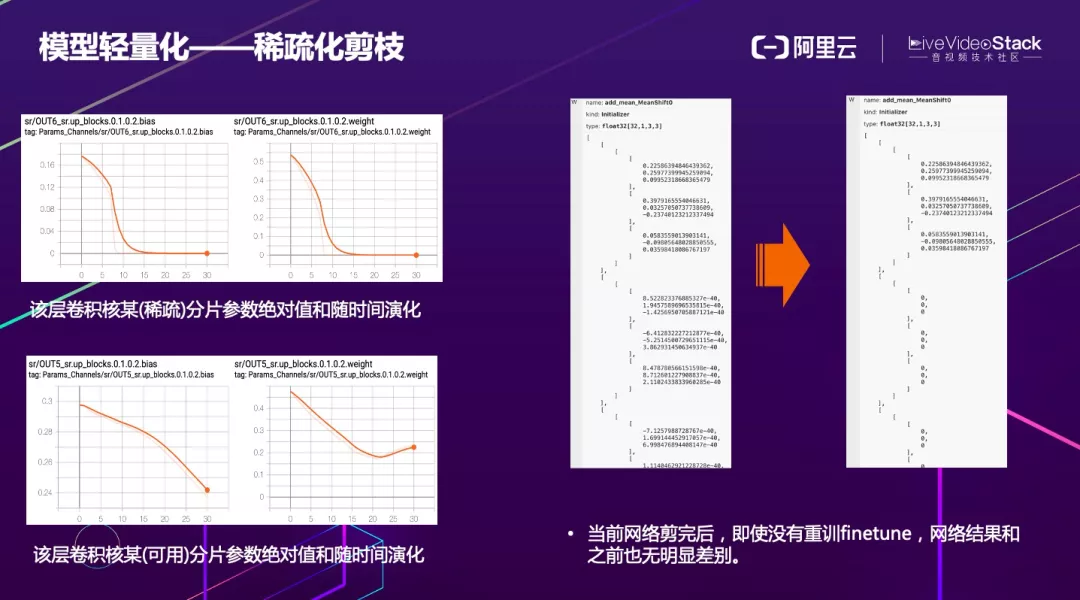
轻量化不仅可以使用结构重参数化,还可以使用稀疏化剪枝。如果纯粹对连接进行稀疏,稀疏完后在 CPU、GPU 的计算不一定会变快。对于 GPU 的计算来说,高度并行的数据相对来说更为友好,纯粹对连接进行稀疏,看似将部分连接被掏空简化参数和计算量,但实际计算时由于 channel 对齐或访存不连续等不一定会减少计算延时。
因此,目前业界大多采用结构化的稀疏方式。左边两张图某个卷积核相关的参数,在统计其参数绝对值的和随时间变化的曲线后发现,如果逐渐趋向于 0,说明这个分支本身非常稀疏。对于其中一些数值非常小的连接,可以进行裁剪,但在裁剪时,也要考虑到前后 layer 的连接问题,从整体结构上进行裁剪。
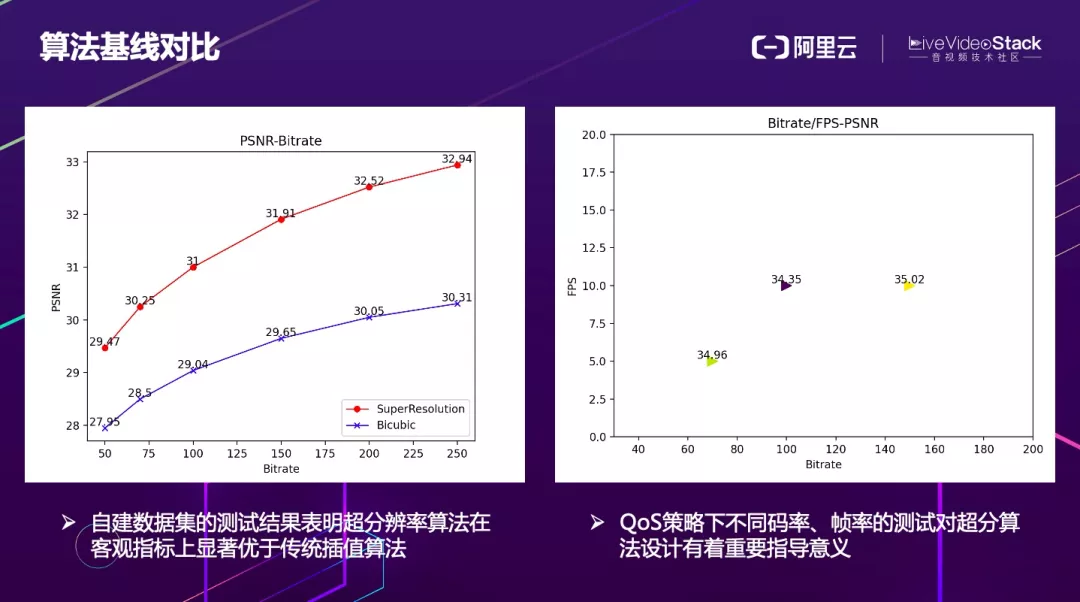
这里的两张图上表示了超分算法的统计基线对比。通过左图可以发现,超分算法在不同的档位效果都比传统算法好,很明显不在一个档次上。右图,我们统计了超分算法在不同的码率帧率下 PSNR 大致的分布,有了这个分布图之后,就可以反过来指导 QoS 策略,在不同带宽下合理的降码率和帧率。

这是直播场景的超分算法效果。

这是文字场景的超分算法效果。
3. 软硬件层面的深度优化
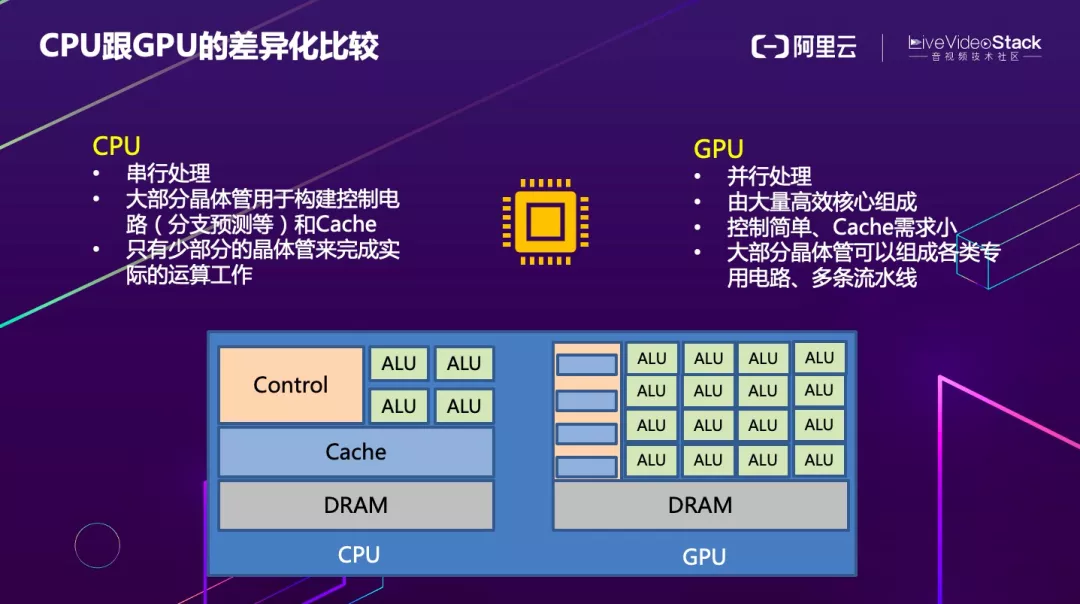
在开头我们已经提到异构硬件非常多,但是在实际业务场景中 CPU 和 GPU 优化会工作会占据 90% 以上,所以这部分我们主要以 CPU 和 GPU 为例来介绍优化策略。对比来看 CPU 更适合做控制逻辑比较复杂、串行的工作,而 GPU 因为有大量 ALU 单元,更适合做并行的计算。
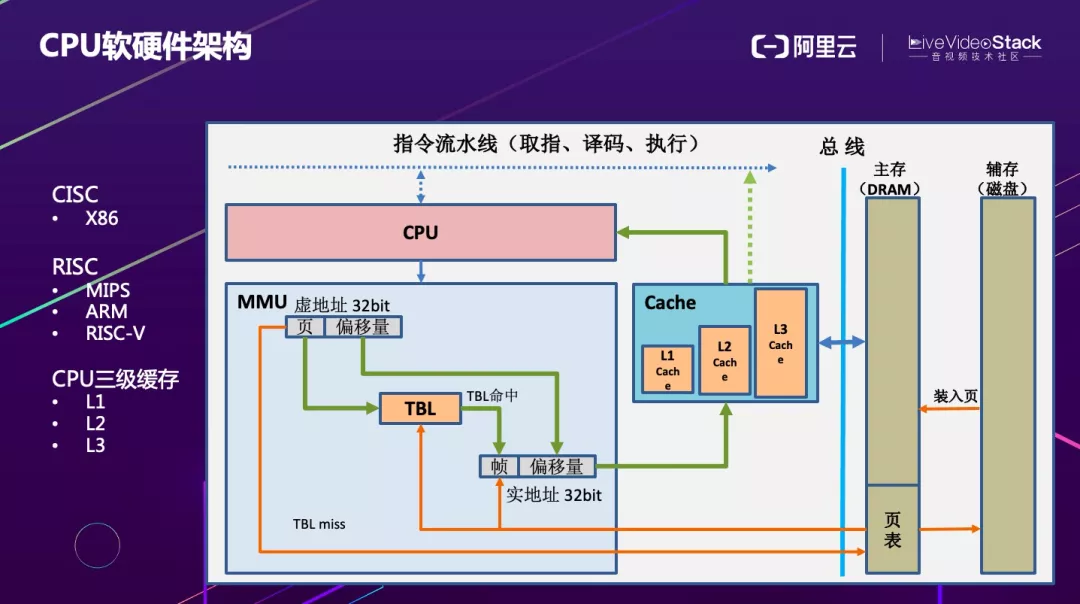
该图简单介绍了 CPU 的软硬件架构。从整体的设计来看,CPU 的架构分为复杂指令集和精简指令集两类。复杂指令集以 X86 为代表,精简指令集以 MIPS、ARM、RISC-V 为代表。CPU 有一个重要的特征是其三级缓存。在优化时必须要先了解其软硬件结构,才能选取更适合的优化方法。
图中描述了 CPU 计算的流程,要完成计算首先要取数据,需要拿一个虚拟地址去内存管理单元通过 TBL 查表寻址,如果命中可以直接从 Cache 里面取数据进行计算,这样的效率非常高,如果没有找到(Cache miss),就需要通过总线(效率较低)去访问主存甚至磁盘来加载数据,这种情况下对功耗、性能、延时影响都非常大,在做优化时必须重点考虑。
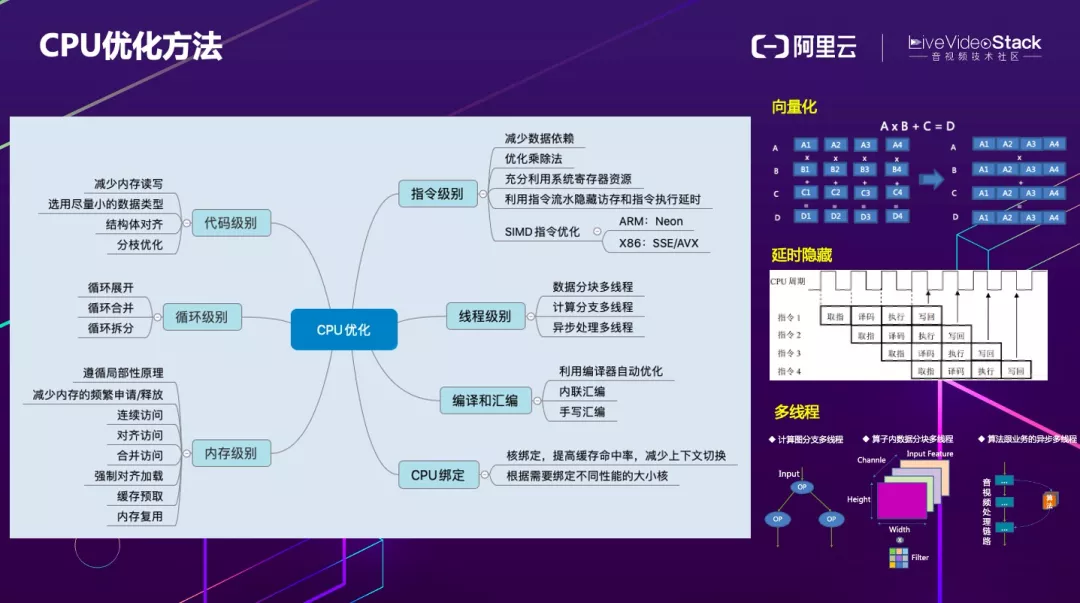
由此引出了 CPU 的优化方法。大体上分为代码级别、循环级别,内存级别,指令级别和线程级别。代码级别需要尽量减少内存的读写、尽量选用小的数据类型,还需要结构体对齐以及分枝优化。
循环级别常用的方法为循环展开,循环合并,循环拆分。内存级别主要遵循时间局部性和空间局部性原理,保证一次读取数据可以为多条计算指令用到。
另外需要尽量减少内存的频繁申请和释放,以及保证对内存的连续访问、对齐访问、合并访问、强制对齐加载、缓存预取、内存复用等。指令级别要减少数据依赖、优化乘除法、充分利用系统寄存器资源、利用指令流水隐藏访存和指令延时执行、SIMD 指令优化等。
关于 SIMD 指令优化,对于 ARM 有 NEON,对于 X86 有 SSE/AVX 等。所谓向量化,例如一个矩阵计算 A×B+C=D,用标量计算的话需要多次访存和计算,但是如果使用向量计算,可以大幅减少访存和计算次数。
在 CPU 的指令流水里面,一条指令的执行需要经过取指、译码、执行和回写几个过程。可以在上一条指令取指完成开始译码的同时启动下一条指令的取值操作,循环往复,通过这样的方法不仅可以最大化 CPU 的吞吐量,还可以隐藏访存和计算延时。线程级别的优化,包括数据分块多线程、计算分支多线程以及异步处理多线程。
编译和汇编可以采用利用编译器自动优化、内联汇编或者手写汇编等方式。CPU 绑定方面,如果经常在 CPU Core 之间切换会导致上下文切换频繁,对性能的影响非常大,因此可以选择性的绑定 Core 来提升性能。手机端存在大核和小核的区别,要根据需要绑定不同性能的核以得到最优的性能。

下面来看下 GPU 的软硬件架构,服务器 GPU 主要厂商是英伟达和 AMD,PC 端 GPU 主要是英特尔的 HD 系列以及 AMD 的 APU 系列以及 Radeon 系列。移动 GPU 主流的是高通骁龙 Adreno 系列、ARM 的 Mali 系列以及苹果的 A 系列,Imagination PowerR 系列现在使用的相对较少。
GPU 软件标准主要包括微软的 DirectX 系列、Khronos Group 维护的 OpenGL、Vulkan、OpenGL ES、OpenCL 等、Apple 的 Metal、AMD 的 Mantle 以及 Intel 的 ONE API 等。
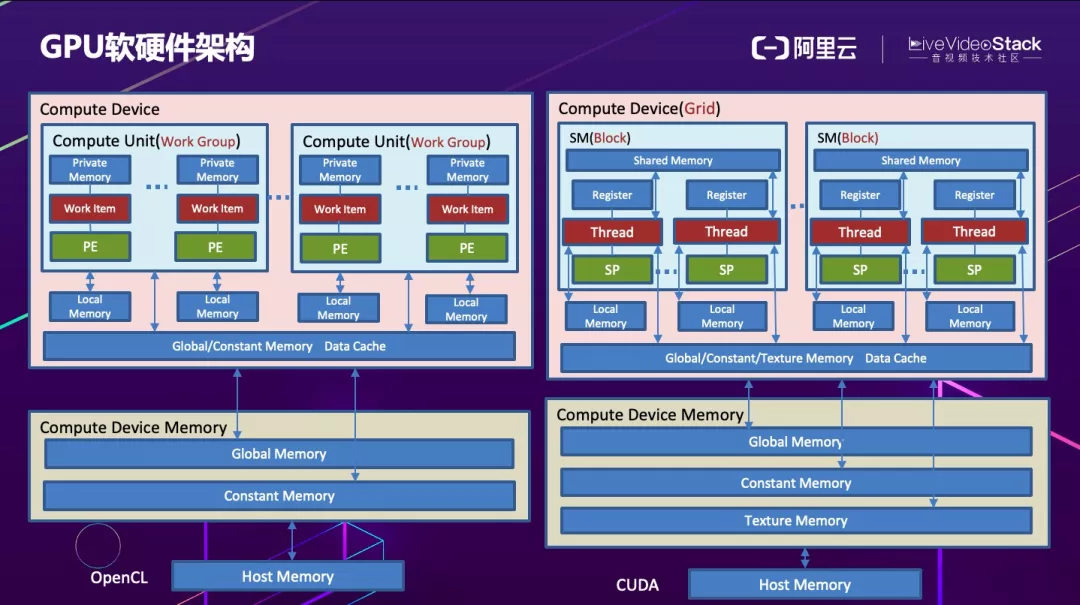
通过这张图简单了解 GPU 的软硬件结构。在硬件层面分为主设备和从设备。主设备一般来说是 CPU 端,从设备一般来说是 GPU 端。这里以 OpenCl 和 CUDA 为例来介绍下软硬件层面的架构。
CUDA 的硬件层面主要包括多流处理器 SM、众多的流处理器 SP 和一些寄存器等,Open CL 包含 CU 和 PE。从内存角度看,CPU 端主存,GPU 端显存。显存也分为全局内存、常量内存、纹理内存、局部内存和共享内存、私有内存等。从线程执行角度,CUDA 分为 Grid、Block、Thread 三个层次,OpenCL 分为 WorkGroup 和 WorkItem。
了解 GPU 的基本结构后,现在来介绍下 GPU 的优化方式。
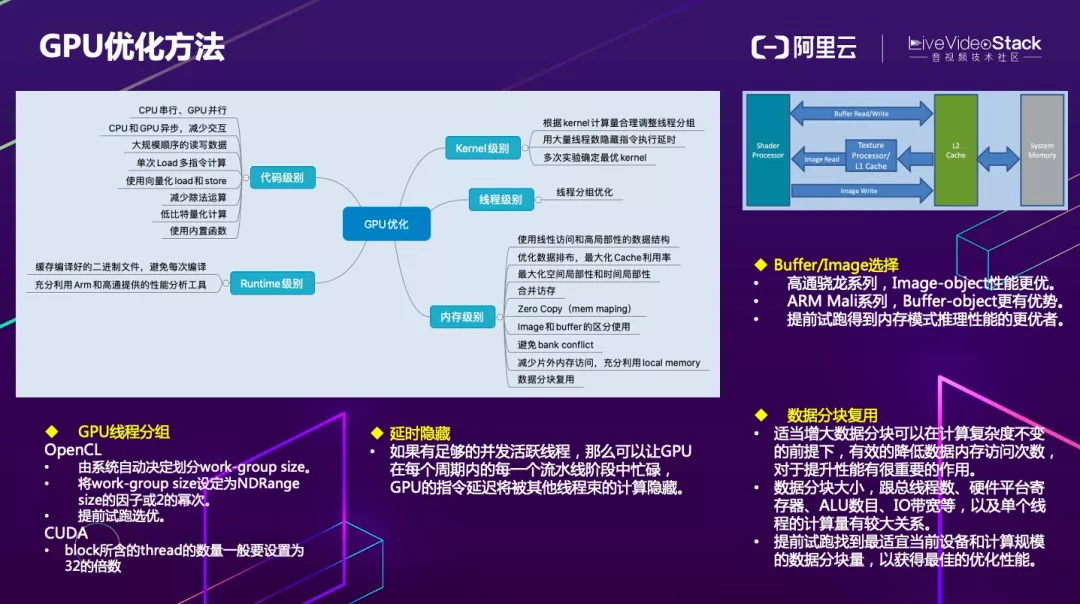
代码级别,串行计算尽量使用 CPU,大量并行计算尽量使用 GPU。CPU 和 GPU 之间尽量采用异步方式,减少直接交互,否则会受到访存和 IO 的限制而影响性能。大规模顺序的读写数据、单次 Load 多指令计算、使用向量化 load 和 store、减少除法运算、低比特量化和使用内置函数也可以划归代码级别优化的方法。
Kernel 级别优化方式包括根据 kernel 合理调整线程分组、用大量线程数隐藏指令执行延时和多次试验确定最优 kernel 等。
线程级别的分组优化在 OpenCL 中可以由系统自动决定如何划分 WorkGroup size。根据经验通常也可以将 WorkGroup size 设定为 NDRange size 的因子或 2 的幂次方。保底的方法是 Auto-Tuning 找到最优分组方式。
CUDA 方面,SM 的配置会影响其所支持的线程块和 warp 并发数量,另外,由于 warp 的大小一般为 32,所以 block 所含的 thread 的大小一般要设置为 32 的倍数。
内存级别优化,包括使用线性访问和高局部性的数据结构、优化数据排布最大化 Cache 利用率、最大化空间局部性和时间局部性、合并访存、Zero Copy、Image 和 buffer 的区分使用等。
理论上,在高通骁龙系列中,Image-object 性能更优,ARM Mali 系列,Buffer-object 更有优势,但这不是绝对的,可以提前试跑得到内存模式推理性能的更优者。另外要避免 bank 冲突、减少片外内存访问,充分利用 Local Memory 以及数据的分片复用。
GPU 的数据块片复用和 CPU 类似,适当增大数据分块可以在计算复杂度不变的前提下,有效的降低数据内存访问次数,对于提升性能有很重要的作用。

如何根据软件特性设计更为轻量的算子,我列出了以下 6 点:
第一, 运算量较小、并行度较低的模型适合 CPU 计算。
第二, 大量并行的模型适合 GPU 计算。
第三, 减少低计算量、无计算量和高访存算子的使用,可以采取和其他算子融合的方法减少访存次数。
第四, 避免使用不好并行的算子。
第五, 卷积核不宜太大,必要时可用多个小卷积核替代。例如 1 个 5x5 可用 2 个 3x3 代替,参数量可以减少到原来 18/25;1 个 7×7 的卷积核可以用 3 个 3×3 的卷积核来代替,参数量可以减少为原来的 27/49。
第六, 通道数对齐要结合硬件和推理框架来调整。MNN 推理时数据一般是按照 NC4H4W4 组织,华为的 HiAI 对应的排布一般选择 16 对齐。如果不了解这些框架的底层实现,就会造成计算资源的浪费。

对于深度学习来说,计算图优化是十分核心的部分。这里包括节点的替换、分支优化、子图变换和算子融合,其中算子融合相对来说使用最多。右边是卷积和 BN 融合的例子,从数学上可以通过公式推导出 BN 可以和卷积完全融合,简化成一个卷积来使用,从而减少推理阶段的访存和计算消耗。
下面另外一个例子,可以将多个 1x1 卷积合并,之后再进行 3 x3 和 5 x5 的卷积,由于最后的 concat 是纯访存操作,因此可以和卷积操作融合到一起,在内存释放前同步完成 concat 操作。
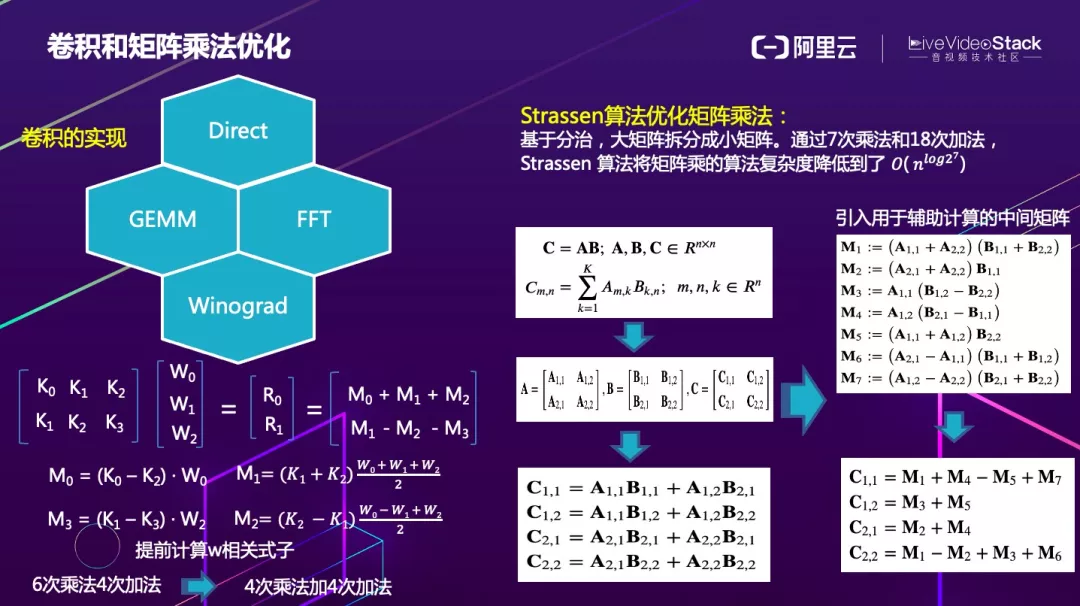
卷积和矩阵乘法是使用频率最高的两个算子。卷积有很多种实现方式,它可以采用滑窗的方式直接实现,通过循环展开、数据分块多线程以及指令集并行等进行优化。还可以通过矩阵乘实现,但需要先进行 img2col 然后再进行矩阵乘法。
FFT 现在用到的比较少,FFT 适合大 kernel 的卷积,小 kernel 的卷积采取直接实现的方法会比 FFT 更快。Winograd 是现在用的比较多的一种优化方式,它的思路也很简单,就是利用加法比乘法消耗的指令周期较短的优势,尽量合并计算把一些常量算式提前计算好,并用加法代替乘法,以减少访存和计算总量。
右边是矩阵乘法的 Strassen 算法优化方法,主要是对矩阵进行分块计算,简化掉很多乘法,再引入一个用于辅助计算的中间矩阵,使得计算量进一步降低。该算法可以通过 7 次乘法和 18 次加法,将矩阵乘的算法复杂度降低到了 。
这是算法层面的优化,最终工程优化层面还需要从以下几方面着手,包括循环优化、数据分块和重排、增加数据复用度、减少 cache miss、向量化、浮点转定点、低比特量化、多线程等。
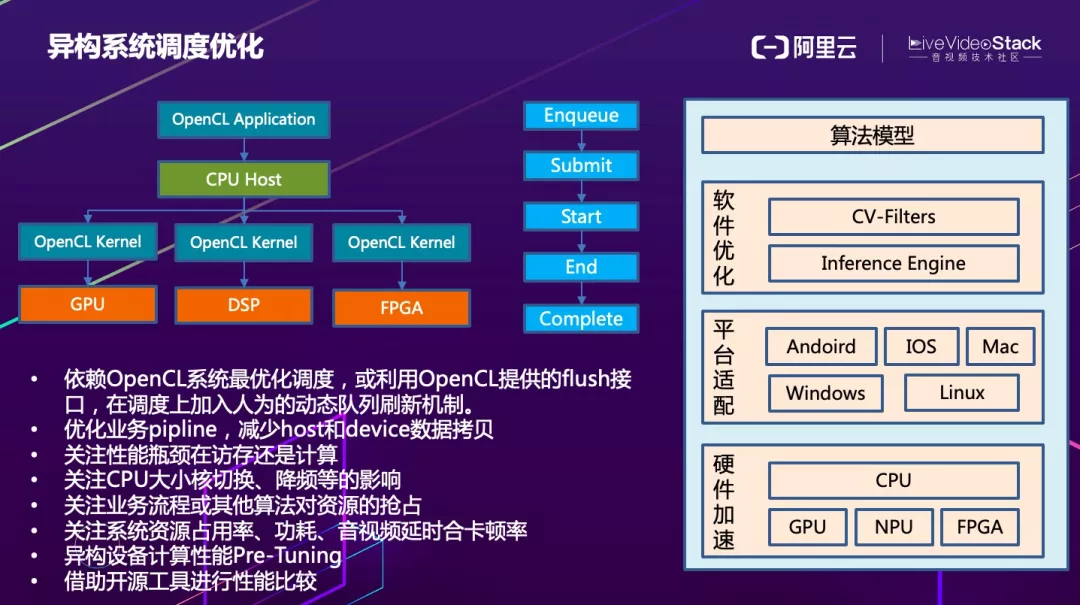
整个算法优化的过程大概如图中所述,先设计好轻量化的算法模型,然后进行软件优化,包括各种前后处理所用到的 CV-Filter 和 Inference Engine 的优化,再往下就是需要各种平台操作系统的适配,最后是硬件加速。
OpenCL 框架下首先需要创建很多个 kernel 将计算任务分发至各个硬件上运行,线程和指令的执行会通过队列的方式来管理,这个队列也存在一定优化策略,可以依赖 OpenCL 系统的最优化调度,也可以利用 OpenCL 提供的 flush 接口,在调度上加入人为的动态队列刷新机制来提高性能。
优化业务 pipline,减少 host 和 device 数据拷贝。关注性能瓶颈在访存还是计算,确定之后再选择优化策略。关注 CPU 大小核切换、降频等的影响。关注业务流程或其他算法对资源的抢占。关注系统资源占用率、功耗、音视频卡顿率。异构设备在优化时可以考虑进行计算性能 Pre-Tuning 来选择最佳的计算方式。还可以借助开源工具进行性能优化。
以上就是我关于算法和软硬件层面的优化方法的分享,下面我们来一起展望下未来。
四、未来展望

随着音视频技术的发展,人们的交互方式在逐渐进化,线上和线下、虚拟和现实会越来越紧密的融合。新的交互方式必然出现催生全新一代云边端一体、软硬一体的实时音视频处理架构。并且会对软硬件的发展和算法的优化提出了更低延时、更大算力、更低功耗的极致挑战。
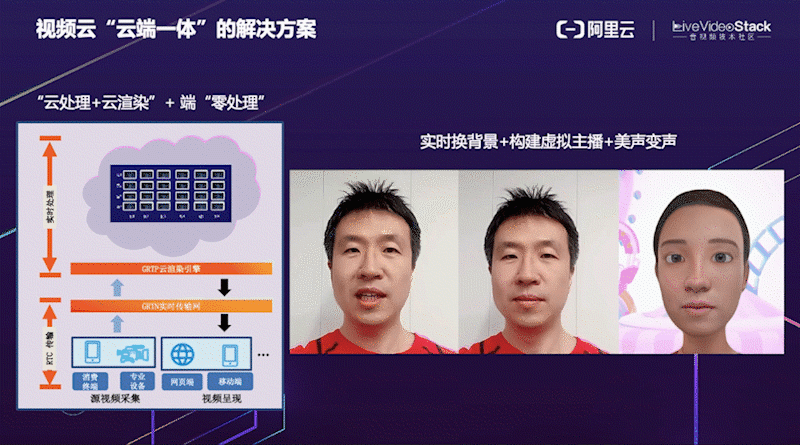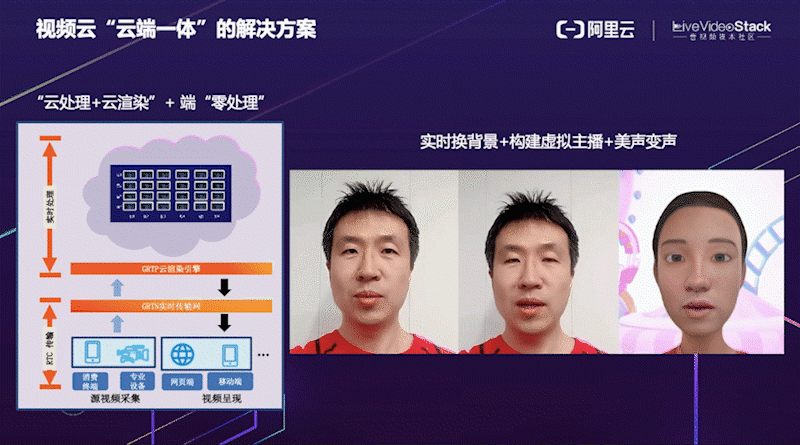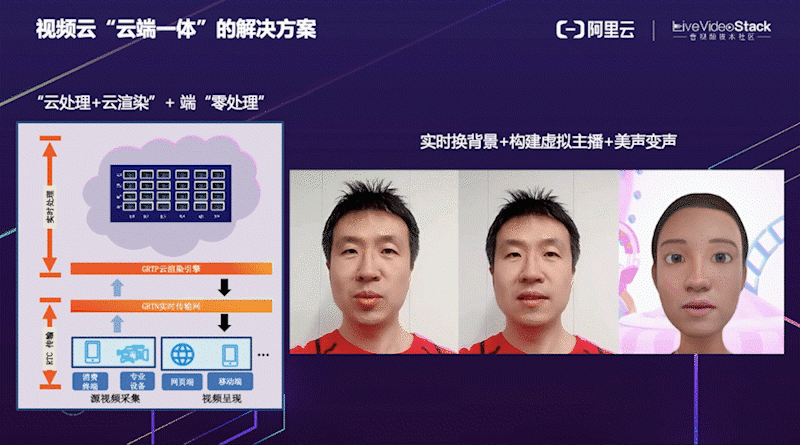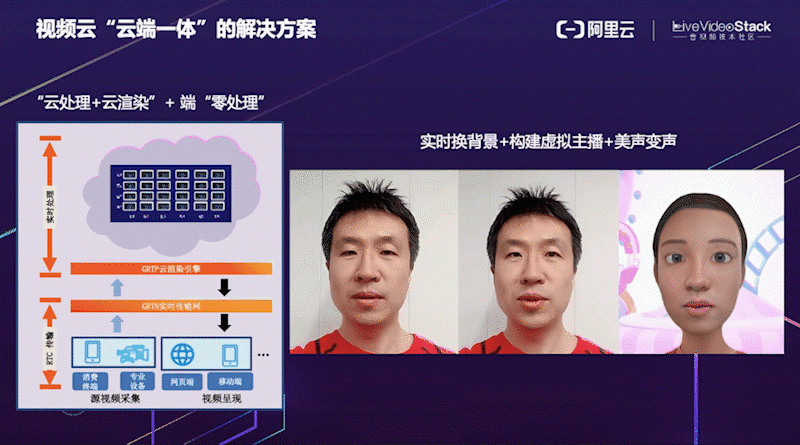
这是阿里云视频云 “云端一体” 的解决方案。考虑到端侧设备计算资源有限,将一些对算力和延时要求比较高的算法可以放在云端 GRTP 引擎进行处理和渲染,处理完成之后端上只需要做普通的渲染即可,真正做到端侧 “零处理”。右边是我们云端一体实时换背景 + 构建虚拟主播 + 美声变声的视频演示效果。

未来 AI、AR、VR、XR、元宇宙等对算力的要求会越来越高,单纯依靠算法和软件优化本质上是有局限性的,因此必须共同推动硬件的快速发展,真正打开算力和性能的天花板。我们判断未来需要云边端更加深度融合、通过软硬一体的方案进一步降本增效,如此算法才能真正赋能千行百业。
以上是我本次的分享,谢谢大家!
「视频云技术」你最值得关注的音视频技术公众号,每周推送来自阿里云一线的实践技术文章,在这里与音视频领域一流工程师交流切磋。公众号后台回复【技术】可加入阿里云视频云产品技术交流群,和业内大咖一起探讨音视频技术,获取更多行业最新信息。