参考文献:深度学习如何提取特征
引题:
一个粗糙的想法,简单粗暴:
法1:每幅图我让机器一个一个像素看,从像素来说,它最能准确地表达某个具体的物体具体的姿势。可以想到,来了一个像素,你能干嘛,你能判断它是谁?逐像素,你只能:(1)对比一张图片和你有损压缩之后相差多少(2)设一个阀值,然后灰度分级。一旦涉及特征,不会只是像素(尽管有raw features ,但这是输入,之后会对它自动提取特征)。
法2:我可能直观地想到,把图片分成若干块,这些若干块中逐部分去和其他图像对比,选择和它相似的块数最多的。这样的分割有点滑稽,比如你分割到物体中间的部分,全是一种颜色,你去搜索和它相似的?那你只能够搜到衣服相同的人了,不同的只是少部分。比如,你看一个陌生人的衣服,你能记住他吗?
法3:提取某种特征。手动选,如sift,hog,harris...
法4:......
法N(N>=4):其实对于图片来说,如果表达式很关键的。比如,对于我们人类来讲,轮廓是一种特征。人类如果只用轮廓就能达到很高的识别度,如素描。机器也应该存在某种描述方式。因此,描述方式才是最重要。
思路:
竟然描述方式这么重要,那我给出人脑的粗糙分层习惯:
先看眼睛感受到一些聚集的像素,然后逐渐判断出分别是手,脚,腰,头,然后再上半身,下半身,然后整个人,最终判断出谁。看起来有点诡异,貌似我们就看高度、肥胖、脸,甚至是先整个人,然后看细节(判断方式)。也许这么说是对的,但是从描述的方式来看,底层到高层是没有问题的,因为他们是组合关系。你不可能先有整体的描述,在分解出细节的描述。假如有,先整体描述,整体怎么描述?(描述方式)。
讲个故事:
1995年,两个学者找到许多黑白照片,他们从中精心挑选出400个patches,记为si,i=1,2,...,400。然后从黑白照片中任意找一个patches 记为T,他们发现:

那么,如果“精心挑选”呢?他们这样做( 稀疏编码):
稀疏编码是一个重复迭代的过程,每次迭代分两步:
1)选择一组 S[k],然后调整 a[k],使得Sum_k (a[k] * S[k]) 最接近 T。
2)固定住 a[k],在 400 个碎片中,选择其它更合适的碎片S’[k],替代原先的 S[k],使得Sum_k (a[k] * S’[k]) 最接近 T。
经过几次迭代后,最佳的 S[k] 组合,被遴选出来了。令人惊奇的是,被选中的 S[k],基本上都是照片上不同物体的边缘线,这些线段形状相似,区别在于方向。
这意味着:
复杂图形,往往由一些基本结构组成。比如下图:一个图可以通过用64种正交的edges(可以理解成正交的基本结构)来线性表示。比如样例的x可以用1-64个edges中的三个按照0.8,0.3,0.5的权重调和而成。而其他基本edge没有贡献,因此均为0 。
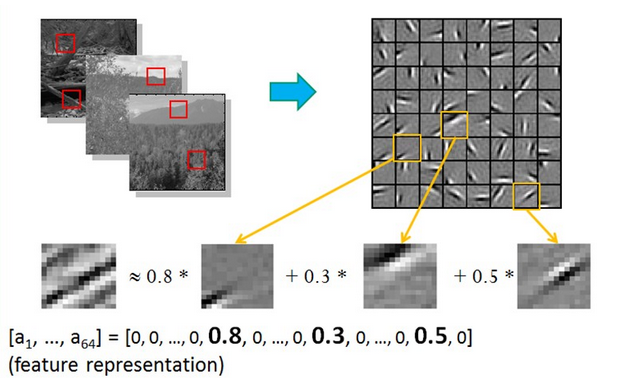
扩展:
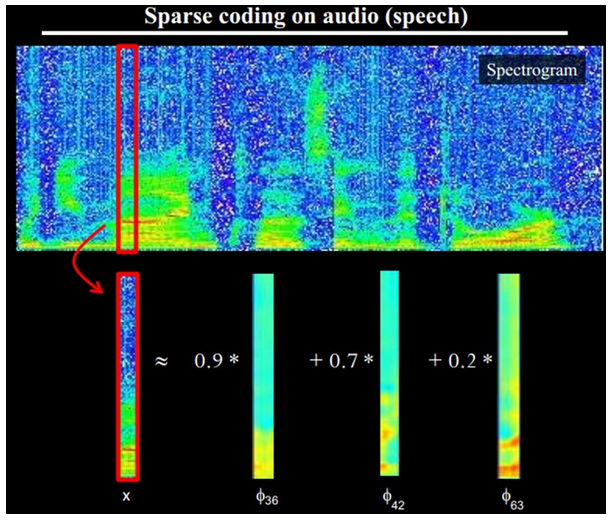
另外,大牛们还发现,不仅图像存在这个规律,声音也存在。他们从未标注的声音中发现了20种基本的声音结构,其余的声音可以由这20种基本结构合成。

分层的思想:
既然这样,我们可以创建更多的层次:
例子1:

例子2:
