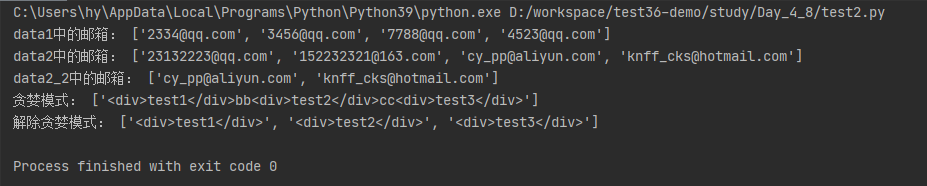
# re 正则表达式 import re import requests with open('youdao.html',encoding='utf-8',mode='r') as f: date = f.read() pattren = re.compile('翻译') # 输入要匹配的内容 r1 = pattren.findall(date) # 在date 中查找匹配的内容,全部匹配 r2 = pattren.search(date) # 在date 中查找匹配的内容,匹配到第一个就停止(一般写代码的时候测试使用) print('r1---->',len(r1),r1) print('r2---->',r2) # 练习 # DD 匹配所以在一起的2个除数字以外的内容 都可以以此类推 data1 = "a236jnfdjka908098?a《《doifjq345431kjalf+ad7f98a7f89amla" result1 = re.compile('d') # 匹配所有的数字 result2 = re.compile('dd') # 匹配在一起的2个数字 result3 = re.compile('D') # 匹配除数字以外的其他内容 result4 = re.compile('w') # 匹配所有的数字和字母和_ result5 = re.compile('W') # 匹配除数字和字母之外的内容 s1 = result1.findall(data1) s2 = result2.findall(data1) s3 = result3.findall(data1) s4 = result4.findall(data1) s5 = result5.findall(data1) print('s1 data1中所有的数字:',len(s1),s1) print('s2 data1中所有在一起的2个数字:',len(s2),s2) print('s3 data1中除数字以外的其他内容:',len(s3),s3) print('s4 data1中所有的数字和字母:',len(s4),s4) print('s5 data1中除数字和字母以外的其他内容:',len(s5),s5)
运行结果:
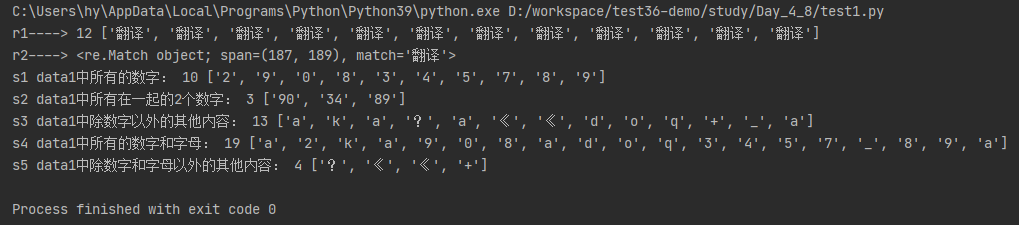
import re # 练习一:邮箱正则 data1 = "2334@qq.com, 13456@qq.com,7788@qq.com。 4523@qq.com" pattren1 = re.compile('dddd@ww.com') j1 = pattren1.findall(data1) print('data1中的邮箱:',j1) # 次数匹配: # d{1,10} 表示在data2中匹配数字,最少1次,最长10次(具体次数范围根据实际情况定义即可) # {2} 表示只匹配2次 # {2,} 表示最少2次,上不封顶。同理{,6} 最少0次,最高6次 # d+ 表示在data2中匹配数字,最少1次,最长无限次,等同于{1,} # d* 表示在data2中匹配数字,最少0次,最长无限次,等同于{0,} # . 表示匹配所有 # . 转义,表示匹配. data2 = "23132223@qq.com, 152232321@163.com、cy_pp@aliyun.com。 knff_cks@hotmail.com" patten2 = re.compile('w+@w+.com') j2 = patten2.findall(data2) print('data2中的邮箱:',j2) data2_2 = "23132223@qqxcom, 152232321@163,com、cy_pp@aliyun.com。 knff_cks@hotmail.com" patten2_2 = re.compile("w+@w+.com") j2_2 = patten2_2.findall(data2_2) print('data2_2中的邮箱:',j2_2) # 匹配模式:正则表达式默认是贪婪匹配的原则,就是尽可能多的去匹配想要的元素,如果想要解除贪婪模式可以使用? data = 'aa<div>test1</div>bb<div>test2</div>cc<div>test3</div> ' pattern_4_1 = re.compile('<div>.*</div>') pattern_4_2 = re.compile('<div>.*?</div>') r1 = pattern_4_1.findall(data) r2 = pattern_4_2.findall(data) print('贪婪模式:',r1) print('解除贪婪模式:',r2) # 正则表达式的万能表达式:.*? .+?
运行结果: