记录下学习过NLP,就是个作业草稿
本次选取论文[1]《Knowledge Graph Embedding Based Question Answering》
论文代码网址:
https://github.com/xhuang31/KEQA_WSDM19
概念介绍
Simple Question:If a natural language question only involves a single head entity and a single predicate in the knowledge graph, and takes their tail entity/entities as the answer, then this question is referred as a simple question (只有一个主语,一个谓语的问题)
下列概念均来自[2] :基于知识图谱的问答系统研究与应用
知识图谱:是一种新兴的数据存储方式,主要特征为使用 RDF 三元组格式进行存储。相比于文本知识,知识图谱具有更丰富的语义表达、更精确的数据内容、更高效的检索方式。
实体识别:是指从非结构化的文本中识别出具有特定意义或者指代性强的实体,例如人名、地名、组织机构名、日期时间、专有名词等。
实体连接:通过实体识别模块识别出问句中的实体信息后,需要将识别出的实体信息正确地指向到知识图谱中目标实体上去。一般实体链接系统会分别采用候选实体生成和实体消歧两个模块解决。候选实体生成模块的输入是上一节实体识别模块识别出的实体提及(Entity Mention),输出是知识图谱中与该提及相关的实体。该过程要求系统尽可能多的返回实体,提升系统召回率。候选实体生成模块通常采用词表匹配的方法。构造出的词表通常包含同义词信息、缩写全称映射信息与别名信息等。实体消歧模块的输入为候选实体生成模块产生的候选实体集和用户输入问句,输出是候选实体集中与问句最相关的实体,或者是经过排序后的候选实体集。
关系检测(Relation Detection):是将用户输入映射到知识图谱某一关系的过程。通过实体链接步骤后,我们可以将问答范围缩小至该实体所在的知识图谱局部范围内。使用关系检测技术确定用户所提及的关系后,结合实体链接搜索出的实体,构造出(实体,关系)对,就可以完成单关系简单问题的回答。
评价指标:
精确度(Precision):代表了系统正确识别出的实体占全部识别出的实体中的比例。
召回率(Recall):指正确识别出的实体占数据集中全部实体的比例。
仅使用精确度和召回率无法全面的评价系统的好坏,使用 F-score 来平衡这两个指标的结果。
这里简单介绍以下词向量:想要详细了解可以参考《自然语言处理实战》Manning出版社的。

词向量可以看作一个权重列表,列表中每个权重都对应这个词在某个特定维度的含义。比如玛丽居里可以由五个维度(和平,有人情味,动物,概念化,女性)表示
WordVector[‘Marie_Curie’] = [-0.46(placeness); 0.35(peopleness); 0.17(animalness);-0.32(conceptness); 0.26(femaleness)]
词向量可以做数学运算,再把得到的结果向量转成词
数据集介绍
数据集使用 Freebase 的子集 FB2M和FB5M作为支撑知识图谱,问句总数达到了 10 万规模。FB2M 共包含 6701个关系类别。
相比于其他的数据集,Simple Questions 一定程度上弥补了训练集无法覆盖知识图谱的问题。

SimpleQuestions 数据集使用实体编号来代替实体名称 “/location/location/time_zones”用于表示知识图谱中的关系名称。
大纲图
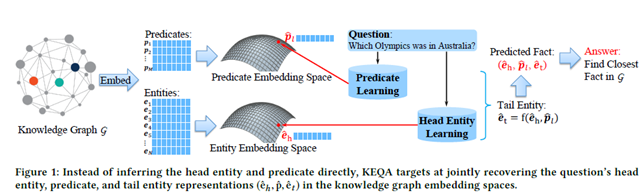
从图中可以看出首先将知识图谱(KG)嵌入成两个低维vector, Predicates(谓语),Entities(名词),
再根据数据集训练Predicate and Head Entity Model,详细的说这两个model的input都是question,输出分别为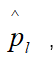
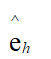
通过给定的函数计算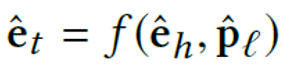
,最后通过精心设计的评价函数,得到最符合fact作为answer。
Knowledge Graph Embedding
嵌入部分是用低维向量尽可能的表示原始数据。我们学习样本为使用TransE和TrainsR训练得到的知识图谱的嵌入空间。
下载网址:https://www.dropbox.com/s/o5hd8lnr5c0l6hj/KGembed.zip。
里面的 entities_emb.bin, predicates_emb.bin是我们需要学习的嵌入空间
Predicate and Head Entity Learning Models
这是模型双向LSTM和Attention , LSTM 是为了考虑一个question中词的顺序,Attention考虑了每个词对于理解这个问题的重要程度不同。

从上图可以看出首先将问题嵌入成带顺序的词向量 ,j = 1-L, L为问题的单词词数量。这里应用的嵌入模型是GloVe
args.vector_cache = "data/sq_glove300d.pt" if os.path.isfile(args.vector_cache):# 如果glove文件存在 # stoi : [3 'the': 2,...,'sábato': 52282] 词和对应的序号 # vector = torch.Size([52283, 300]) 每个词的向量表示 # dim = 300 用dim个元素表示一个词 stoi, vectors, words_dim = torch.load(args.vector_cache) # 加载文件 else: # 如果文件不存在 报错并退出 print("Error: Need word embedding pt file") exit(1) match_embedding = 0 # 嵌入词的个数 TEXT.vocab.vectors = torch.Tensor(len(TEXT.vocab), words_dim) # 定义待数据集,申请内存空间 for i, token in enumerate(TEXT.vocab.itos): # 读取数据集中的词 wv_index = stoi.get(token, None) # 如果数据集中的词在GloVe中存在,则取下标 if wv_index is not None: # 如果wv_index存在 # 将使用GloVe中的向量替换该词,并储存在待训练数据集中 TEXT.vocab.vectors[i] = vectors[wv_index] match_embedding += 1 # 能在GloVe中找到的词个数+1 else: # 使用随机生成的向量代替在GloVe找不到对应的词 TEXT.vocab.vectors[i] = torch.FloatTensor(words_dim).uniform_(-0.25, 0.25)
为了在模型中应用将词向量矩阵移动到模型中model.embed.weight.data.copy_(TEXT.vocab.vectors),
并且将文本变为,
x = self.embed(text)
嵌入后的 通过双向LSTM得到 = [正向:反向]
outputs, (ht, ct) = self.lstm(x) # 通过双向LSTM的hj 其中self.lstm = nn.LSTM(input_size=config.words_dim, hidden_size=config.hidden_size, num_layers=config.num_layer, dropout=config.rnn_dropout, bidirectional=True)
再经过注意力机制
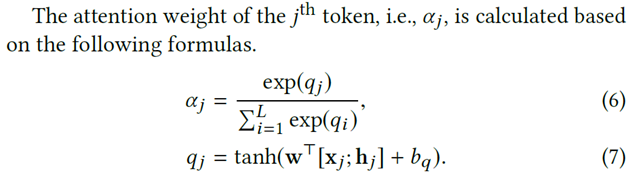
注意力机制由两部分组成,非线性部分
x = x.view(-1, words_dim) # 为了连接output进行view改变形状 attn_weights = F.softmax(self.attn(torch.cat((x, outputs), 1)), dim=0) # alpha = softmax(q) 这里的self.attn = nn.Sequential( nn.Linear(config.hidden_size * 2 + config.words_dim, config.hidden_size), # W'[x:h] + bq self.nonlinear, # q = tanh(W'[x:h] + bq) nn.Linear(config.hidden_size, 1) #变成1维输出为了softmax输入 )
和softmax分类部分
attn_applied = torch.bmm(torch.diag(attn_weights[:, 0]).unsqueeze(0), outputs.unsqueeze(0)) # alpha * h outputs = torch.cat((x, attn_applied.squeeze(0)), 1) # sj = [x:alpha * h]
分数最后由各个数据流经过注意力的均值预测谓语

scores = nn.functional.normalize(torch.mean(tags, dim=0), dim=1) # p^ = mean(r)
将预测值与实际嵌入谓语之间使用MSE损失函数criterion = nn.MSELoss()差值反向传播训练模型。
loss = criterion(model(batch), predicates_emb[batch.mid, :]) loss.backward() #反向传播 # clip the gradient:设置梯度阈值,防止梯度爆炸 torch.nn.utils.clip_grad_norm_(model.parameters(), args.clip_gradient) optimizer.step() # 梯度优化
经过训练多次模型的准确度不在提升,则此时为最好的模型:
# update model if curr_accu > best_accu: # 如果精确度提升 best_accu = curr_accu # 此时精确度为最好的精确度 best_loss = total_loss # 记录loss iters_not_improved = 0 # 模型不在提升的次数刷新为0 # save model, delete previous 'best_snapshot' files torch.save(model, os.path.join(args.output, args.best_prefix + '_best_model.pt')) else: #如果精确度没有提升 iters_not_improved += 1 # 模型不提升次数+1 if iters_not_improved > patience: # 如果不提升次数达到设置次数 early_stop = True # 停止训练模型 break

Head Entity Detection Model
由于 对应许多head entities,所以我们需要减少候选数量,这就是Head Entity Detection Model的作用。
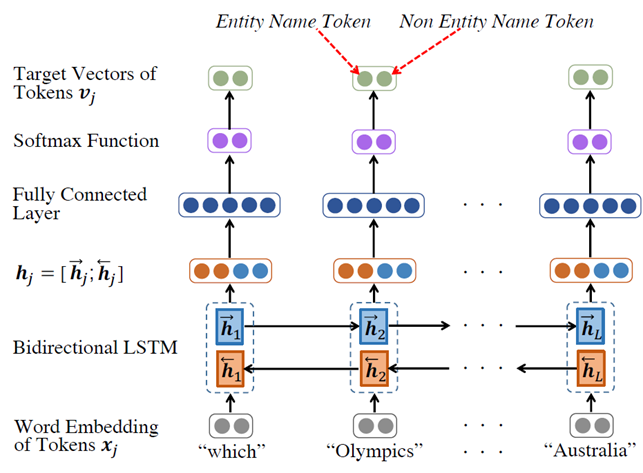
这是个简单的双向LSTM+softmax分类模型,这是模型是为了将所有的token(question 的分词)分为Entity Name Token (label = “I”)or Non Entity Name Token(label = “O”)即,该词是entity or non entity。
我们先介绍两个数据文件"annotated_fb_data_train" and 'names.trimmed.txt'。
"annotated_fb_data_train"是SimpleQuestions数据集中data含有的文件每行含有四部分
我们忽略其中的网址,它代表freebase数据集。
我们把这四部分分为item[0],item[1],item[2],item[3]
item[0] 是主语;item[1] 是谓语;item[2] 是宾语;item[3] 是问题
其中主语和宾语是由他们对应的编号代替,例如:drum的编号为m.0f9rv4n
'names.trimmed.txt'是经过处理的数据,每一行是实体和他们对应的实体编号, 例如第一行
m.0f8vjgd skyshaper
关于'names.trimmed.txt'经过怎样处理我们先不谈,现在只需要知道是处理SimpleQuestions 数据集中FB5M.names.txt文件得到。
首先将'names.trimmed.txt'读入到程序中,并且储存为字典格式,方便实体和实体编号之间的联系
names_map = [3] with open(os.path.join(args.output, 'names.trimmed.txt'), 'r') as f: for i, line in enumerate(f): items = line.strip().split(" ") entity = items[0] literal = items[1].strip() if names_map.get(entity) is None: # 如果entity在dict中还没有 names_map[entity] = [(literal)] # 创建字典[2] else: #如果已经存在,添加value ('m.0f9x06p', ['long , long journey']) names_map[entity].append(literal)
该行问题中主语对应的实体名称保存到 cand_entity_names
if names_map.get(subject) is None: cand_entity_names = None else: # if subject in names_map to can_entity_names = names cand_entity_names = names_map[subject] 该行问题中没有主语的情况,对应名称用'<UNK>'填充,并且label = O*num of tokens tokens = sent.split() # 将question分词 label = ["O"] * len(tokens) # 先标记全不是entity text_attention_indices = None # 判断question中是否有subject exact_match = False # 是否精确匹配 if text_candidate is None or len(text_candidate) == 0:# 如果该行没有主语,label全为O return '<UNK>', ' '.join(label), exact_match
如果该行问题中有主语,则将主语在该问题中对应位置label设置为“I”
text_attention_indices = get_indices(tokens, text.split()) # get_indices 返回text在tokens中的下标范围 if text_attention_indices != None: exact_match = True for i in text_attention_indices: label[i] = 'I'
如果该行问题中有主语,但是该主语在数据集中没有找到,则使用fuzzy找出最相似的一个主语代替,如果找不到,则对应名称用'<UNK>'填充,并且label = O*num of tokens
else: # if no match try: # process.extractOne 提取匹配度最大的结果 v, score = process.extractOne(sent, text_candidate, scorer=fuzz.partial_ratio) except: # if no find print("Extraction Error with FuzzyWuzzy : [2] || [2]".format(sent, text_candidate)) return '<UNK>', ' '.join(label), exact_match
这样完成了标签的标记。
为了消除噪音,删除不存在主语的问题,即删除掉全是O的question,并保存在dete_train.txt中
outfile = open(os.path.join(args.output, 'dete_train.txt'), 'w') for line in open(os.path.join(args.output, 'train.txt'), 'r'): items = line.strip().split(" ") tokens = items[6].split() #items[6] = train.label # 因为question首字母是疑问词(what how where等)一定不是entity if any(token != tokens[0] for token in tokens): # (False False False False True False) outfile.write("{} {} ".format(items[5], items[6])) outfile.close()
到这里就完成对数据集的处理。
此时的模型input是question,output是该问题中所有主语的位置为“I“,其他为”O“的Label。
Joint Search on Embedding Spaces
到目前为止,我们已经对一个问题进行了预测谓词,主语和question中分词的标签,即(,label)。我们的目标是找出最匹配的fact(一个回答由主语谓语宾语组成)。
我们把Label为“I“对应的主语叫做candidate head entities(候选主语),把含有候选主语的fact叫做candidate fact(候选语料)。由于主语和谓语相同的语料不一定只有一个,为了选择出最符合的一个fact。该论文中提出了Joint distance metric,利用知识图谱的特点:

前两项代表预测主语和谓语的偏差,第三项代表公式计算出与实际宾语的偏差,后两项表示Label是否正确标记了主语和非主语。可以看出该函数就是对上述三个模型的损失函数的最小值。也就是最符合的fact。
我们来看一下完成的算法流程:

前1-9行可以同时进行训练,以减少时间。10-12行对一个new dataset应用之前的模型进行训练,得到 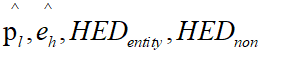
:
# load pred model model = torch.load(args.pred_model, map_location=lambda storage, loc: storage.cuda(args.gpu)) # 加载Pred_model到GPU scores = model(data_batch).cpu().data.numpy() # 预测并保存为numpy类型,为了进行计算 for i in range(batch_size): pred_emb[baseidx + i] = scores[i] # 保存到pred_emb baseidx = baseidx + batch_size # 下一次小批次 # load dete model model = torch.load(args.dete_model, map_location=lambda storage, loc: storage.cuda(args.gpu)) # load detemodel to GPU answer = torch.max(model(data_batch), 1)[1].view(data_batch.ed.size()) # 预测并转变成与torchtext处理后的数据集相同大小 answer = np.transpose(answer.cpu().data.numpy()) # 转置 dete_result.extend(answer) # 存放在dete_result列表 # load entity model model = torch.load(args.entity_model, map_location=lambda storage, loc: storage.cuda(args.gpu)) scores = model(data_batch).cpu().data.numpy() for i in range(batch_size): # 变成一行,每个元素是list(scores[i]) head_emb[baseidx + i] = scores[i] # 保存到head_emb baseidx = baseidx + batch_size # 下一次小批次
13-14行是HED模型结果上找出最优fact
1 beta1, beta2, beta3,bete4 = .39, .43, .003, .017 2 3 # head_mid_idx = {匹配的编号:name} + {不匹配编号:None} 4 5 for i, head_ids in enumerate(head_mid_idx): # 基于HEDmodel的结果寻找符合的fact集合C 6 7 if i % 1000 == 1: # 处理进度 8 9 print('progress: {}'.format(i / total_num), end=' ') 10 11 answers = [] 12 13 for (head_id, name) in head_ids: # dict遍历
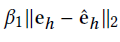
# 公式中的第二项
entity_score = np.sqrt(np.sum(np.power(entities_emb[mid_dic[head_id]] - head_emb[i], 2)))
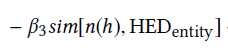
# 第四项
name_score = -beta3 * fuzz.ratio(name, dete_tokens_list[i]) # dete_tokens_list = 问题的文字形式 if (head_id, name) in tuple_topic: # 如果预测的主语是宾语,则减少分数 name_score -= .18 if reach_dic.get(head_id) is not None: # 排除掉HEDnon的主语 for pred_id in reach_dic[head_id]: # reach_dic[head_id] = pred_id

#最后一项 filter_q = 数据集中从问题中提取的谓语(真实值)由于pred_id 就是Entitynon部分
pred_names = fuzz.ratio(pre_num_dic[pred_id].replace('.', ' ').replace('_', ' '), filter_q[i]) # pre_num_dic = {pred_id:pred}
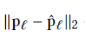
# 公式中的第一项
pred_score = np.sqrt(np.sum(np.power(predicates_emb[pred_id] - pred_emb[i], 2)))
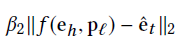
1 tai_score = np.sqrt(np.sum( # 第三项 2 3 np.power(predicates_emb[pred_id] + entities_emb[mid_dic[head_id]] - head_emb[i] - pred_emb[i], 2))) 4 5 joint_distance_metric = pred_score + beta1 * entity_score + beta2 * tai_score + name_score - bete4 *pred_names 6 7 answers.append((head_id, pred_id, joint_distance_metric )) 8 9 if answers: # 如果找到fact 10 11 answers.sort(key=lambda x: x[2]) # 以joint_distance_metric分数进行排序 12 13 learned_head[i] = answers[0][0] # 取分数最高的fact的主语 14 15 learned_pred[i] = answers[0][1] # 取分数最高的fact的谓语 16 17 learned_fact[' '.join([learned_head[i], pre_num_dic[learned_pred[i]]])] = i # 最合适的fact = head + pred
这里的head_mid_idx = {匹配的编号:name} + {不匹配编号:None}是由HED模型结果dete_result,处理得到,所以是Find the candidate fact set C from G, based on HEDentity;
[1] HUANG X, ZHANG J, LI D, 等. Knowledge Graph Embedding Based Question Answering[A]. Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining[C]. 2019. 105-113.
[2] 乔振浩. 基于知识图谱的问答系统研究与应用[D]. 哈尔滨工业大学, 2020.
[3] 霍布森·莱恩、科尔·霍华德、汉纳斯·马克斯·哈普克、史亮、鲁骁、唐可欣、王斌. 《自然语言处理实战》[J]. 中文信息学报, 2020, v.34(10): 117-117.