原文发表于百度空间,2011-04-05
==========================================================================
在分析ntfs的B+树时,不可避免地要进行文件名大小的比较,经过观察发现通常我们在资源管理器中看到的文件排序和ntfs中有很大不同。
比如,有下面一些文件,在资源管理器中排序如下: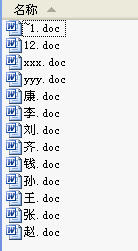
可以看到对汉字是按其汉语拼音排序的。
而在ntfs的目录索引中排序如下: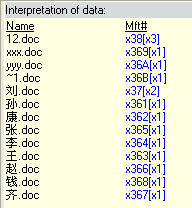
观察发现,由于ntfs存储的是Unicode文件名,所以比较时是按首字符的Unicode编码来比较的。实际分析如下:
在ntfs的INDX中的实际顺序(后面是第一个Unicode字符的编码):
12.doc 0x0031
xxx.doc 0x0078
yyy.doc 0x0079
~1.doc 0x007E
刘.doc 0x5218
孙.doc 0x5B59
康.doc 0x5EB7
张.doc 0x5F20
李.doc 0x674E
王.doc 0x738B
赵.doc 0x8D75
钱.doc 0x94B1
齐.doc 0x9F50
为了验证这个结果,我在ntfs的源代码中找到了答案:
FSRTL_COMPARISON_RESULT NtfsCollateNames ( IN PWCH UpcaseTable, IN ULONG UpcaseTableSize, IN PUNICODE_STRING Expression, IN PUNICODE_STRING Name, IN FSRTL_COMPARISON_RESULT WildIs, IN BOOLEAN IgnoreCase ) { WCHAR ConstantChar; WCHAR ExpressionChar; ULONG i; ULONG Length; if (Expression->Length < Name->Length) { Length = Expression->Length / sizeof(WCHAR); } else { Length = Name->Length / sizeof(WCHAR); } for (i = 0; i < Length; i += 1) { ConstantChar= Name->Buffer[i];//取原始字符 ExpressionChar= Expression->Buffer[i]; if ( IgnoreCase ) {//根据是否区分大小写进行判断,Windows的文件名不区分大小写,所以这里通常是TRUE //UpcaseTable可以直接读取ntfs根目录下的$Upcase得到 if (ConstantChar < UpcaseTableSize) { ConstantChar = UpcaseTable[(ULONG)ConstantChar];//取UpcaseTable中的对应字符 } if (ExpressionChar < UpcaseTableSize) { ExpressionChar = UpcaseTable[(ULONG)ExpressionChar];//取UpcaseTable中的对应字符 } } //判断字符是否无效 if ( FsRtlIsUnicodeCharacterWild(ExpressionChar) ) { DebugTrace( -1, Dbg, ("NtfsCollateNames -> %08lx (Wild) ", WildIs) ); return WildIs; } //进行比较 if ( ExpressionChar < ConstantChar ) { DebugTrace( -1, Dbg, ("NtfsCollateNames -> LessThan ") ); return LessThan; } if ( ExpressionChar > ConstantChar ) { DebugTrace( -1, Dbg, ("NtfsCollateNames -> GreaterThan ") ); return GreaterThan; } } ....//省略部分代码 DebugTrace( -1, Dbg, ("NtfsCollateNames -> EqualTo ") ); return EqualTo; }
这回对ntfs中文件名的排序和比较有个清楚的了解了,不过呢,这个结果看起来有一点怪怪的~~