网上搜了一下找了很多介绍hive的资料,不是官方翻译就是含糊描述,对于刚接触的很难直观认识
我从一本介绍hadoop的书里找到了一些hive的资料,没太多废话。可以看看
http://pan.baidu.com/s/1qW6txus
Hive是基于hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能,可以将SQL语句转换为MapReduce任务进行运行。
不熟悉MapReduce的人可以方便的使用SQL语言查询、汇总、分析数据。
MapReduce开发人员可以把自己写的Mapper和Reducer作为插件支持Hive做更复杂的数据分析。(我觉得这才是实际生产中用的最多的,属于高级部分吧,因为每个企业都有自己的业务的数据格式等等)
hive最适合应用在基于大量不可变数据的批处理作业。(这个好像和HBase刚好相反)
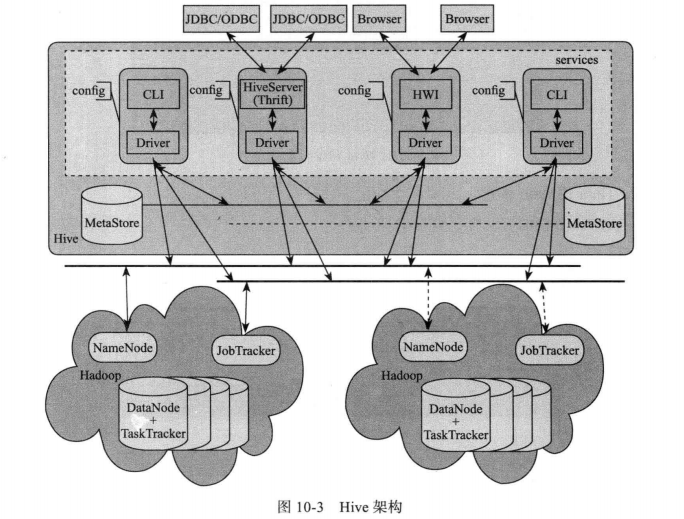
hive的入口是Driver,执行SQL语句首先提交到Driver驱动,然后调用Compiler解释驱动,最终解释成MapReduce任务执行,最后将结果返回。
Hive提供基本数据类型和复杂数据类型,复杂数据类型是Java语言不具有的
hive的执行大部分是通过hadoop的MapReduce实现的,类似select * from table1不需要MapReduce。(为什么?)
关于hive的执行延迟有两种原因(很多资料只说了一种):1.hive没有索引,查询数据要扫描整个表;2.使用MapReduce;
hive的用户接口有:CLI、Client和Web UI。
hive的元数据存储在如MySQL这样的数据库里
hive的缺点
1.Hive的HQL表达的能力有限,有些复杂运算用HQL不易表达;
2.Hive的效率较低
- Hive自动生成MapReduce作业,通常不够只能;
- HQL调优困难,粒度较粗;
- 可控性差。
Hive的运行架构

Hive的接口

Hive的数据存储

Hive的数据模型
1.基本数据类型
1.1数字类型
- tinyint
- smallint
- int
- bigint
- float
- double
- decimal
1.2时间类型
- timestamp
- date
1.3字符串类型
- string
- varchar
- char
1.4其他类型
- boolean
- binary
2.复杂数据类型
- arrays
- maps
- structs
- union