Scrapy+selenium爬取简书全站
环境
-
Ubuntu 18.04
-
Python 3.8
-
Scrapy 2.1
爬取内容
- 文字标题
- 作者
- 作者头像
- 发布日期
- 内容
- 文章连接
- 文章ID
思路
- 分析简书文章的url规则
- 使用selenium请求页面
- 使用xpath获取需要的数据
- 异步存储数据到MySQL(提高存储效率)
实现
前戏:
- 创建scrapy项目
- 建立crawlsipder爬虫文件
- 打开
pipelines和middleware
第一步:分析简书文章的url
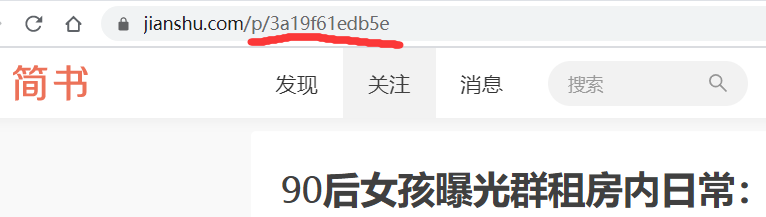
可以看到url规则为jianshu.com/p/文章ID,然后再crawlsipder中设置url规则
class JsSpider(CrawlSpider):
name = 'js'
allowed_domains = ['jianshu.com']
start_urls = ['http://jianshu.com/']
rules = (
Rule(LinkExtractor(allow=r'.+/p/[0-9a-z]{12}.*'), callback='parse_detail', follow=True),
)
第二步:使用selenium请求页面
设置下载器中间件
-
由于作者、发布日期等数据由Ajax加载,所以使用selenium来获取页面源码以方便xpath解析
-
有时候请求会卡在一个页面,一直未加载完成,所以需要设置超时时间
-
同理Ajax也可能未加载完成,所以需要显示等待加载完成
from selenium import webdriver
from scrapy.http.response.html import HtmlResponse
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.common.by import By
class SeleniumDownloadMiddleware(object):
def __init__(self):
self.driver = webdriver.Chrome()
def process_request(self, request, spider):
while True:
# 超时重新请求
try:
self.driver.set_page_load_timeout(1)
self.driver.get(request.url)
except:
pass
finally:
try:
# 等待ajax加载,超时了就重来
WebDriverWait(self.driver, 1).until(
expected_conditions((By.CLASS_NAME, 'rEsl9f'))
)
except:
continue
finally:
break
url = self.driver.current_url
source = self.driver.page_source
response = HtmlResponse(url=url, body=source, request=request, encoding='utf-8')
return response
注意提前将 chromedriver 放到/user/bin下,或者自行指定执行路径。windows下可以讲其添加到环境变量下。
第三步:使用xpath获取需要的数据
设置好item
import scrapy
class JianshuCrawlItem(scrapy.Item):
title = scrapy.Field()
content = scrapy.Field()
author = scrapy.Field()
avatar = scrapy.Field()
pub_time = scrapy.Field()
origin_url = scrapy.Field()
article_id = scrapy.Field()
分析所需数据的xpath路径,进行获取需要的数据,并交给pipelines处理
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from ..items import JianshuCrawlItem as Jitem
class JsSpider(CrawlSpider):
name = 'js'
allowed_domains = ['jianshu.com']
start_urls = ['http://jianshu.com/']
rules = (
Rule(LinkExtractor(allow=r'.+/p/[0-9a-z]{12}.*'), callback='parse_detail', follow=True),
)
def parse_detail(self, response):
# 使用xpath获取数据
title = response.xpath("//h1[@class='_2zeTMs']/text()").get()
author = response.xpath("//a[@class='_1OhGeD']/text()").get()
avatar = response.xpath("//img[@class='_13D2Eh']/@src").get()
pub_time = response.xpath("//div[@class='s-dsoj']/time/text()").get()
content = response.xpath("//article[@class='_2rhmJa']").get()
origin_url = response.url
article_id = origin_url.split("?")[0].split("/")[-1]
print(title) # 提示爬取的文章
item = Jitem(
title=title,
author=author,
avatar=avatar,
pub_time=pub_time,
origin_url=origin_url,
article_id=article_id,
content=content,
)
yield item
第四步:存储数据到数据库中
我这里用的数据库是MySQL,其他数据同理,操作数据的包是pymysql
提交数据有两种思路,顺序存储和异步存储
由于scrapy是异步爬取,所以顺序存储效率就会显得比较慢,推荐采用异步存储
顺序存储:实现简单、效率低
class JianshuCrawlPipeline(object):
def __init__(self):
dbparams = {
'host': '127.0.0.1',
'port': 3306,
'user': 'debian-sys-maint',
'password': 'lD3wteQ2BEPs5i2u',
'database': 'jianshu',
'charset': 'utf8mb4',
}
self.conn = pymysql.connect(**dbparams)
self.cursor = self.conn.cursor()
self._sql = None
def process_item(self, item, spider):
self.cursor.execute(self.sql, (item['title'], item['content'], item['author'],
item['avatar'], item['pub_time'],
item['origin_url'], item['article_id']))
self.conn.commit()
return item
@property
def sql(self):
if not self._sql:
self._sql = '''
insert into article(id,title,content,author,avatar,pub_time,origin_url,article_id)
values(null,%s,%s,%s,%s,%s,%s,%s)'''
return self._sql
异步存储:复杂、效率高
import pymysql
from twisted.enterprise import adbapi
class JinshuAsyncPipeline(object):
'''
异步储存爬取的数据
'''
def __init__(self):
# 连接本地mysql
dbparams = {
'host': '127.0.0.1',
'port': 3306,
'user': 'debian-sys-maint',
'password': 'lD3wteQ2BEPs5i2u',
'database': 'jianshu',
'charset': 'utf8mb4',
'cursorclass': pymysql.cursors.DictCursor
}
self.dbpool = adbapi.ConnectionPool('pymysql', **dbparams)
self._sql = None
@property
def sql(self):
# 初始化sql语句
if not self._sql:
self._sql = '''
insert into article(id,title,content,author,avatar,pub_time,origin_url,article_id)
values(null,%s,%s,%s,%s,%s,%s,%s)'''
return self._sql
def process_item(self, item, spider):
defer = self.dbpool.runInteraction(self.insert_item, item) # 提交数据
defer.addErrback(self.handle_error, item, spider) # 错误处理
def insert_item(self, cursor, item):
# 执行SQL语句
cursor.execute(self.sql, (item['title'], item['content'], item['author'],
item['avatar'],
item['pub_time'],
item['origin_url'], item['article_id']))
def handle_error(self, item, error, spider):
print('Error!')
总结
- 类似简书这种采用Ajax技术的网站可以使用selenium轻松爬取,不过效率相对解析接口的方式要低很多,但实现简单,如果所需数据量不大没必要费劲去分析接口。
- selenium方式访问页面时,会经常出现加载卡顿的情况,使用超时设置和显示等待避免浪费时间