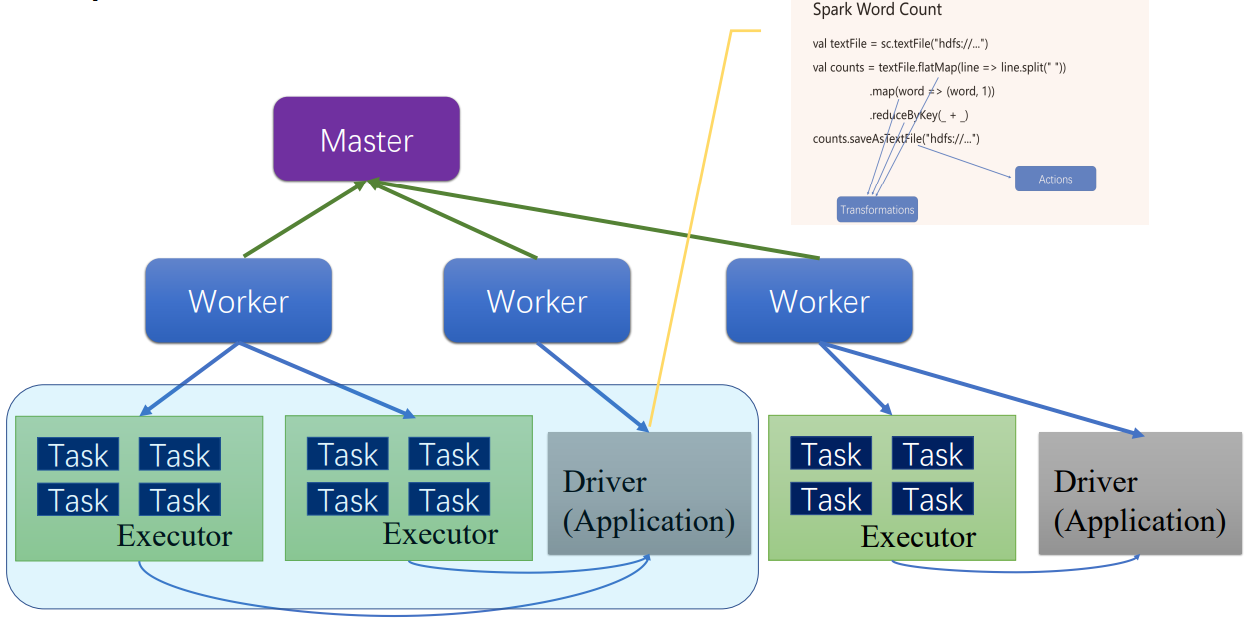
一、运行架构概览
Spark架构是主从模型,分为两层,一层管理集群资源,另一层管理具体的作业,两层是解耦的。第一层可以使用yarn等实现。
Master是管理者进程,Worker是被管理者进程,每个Worker节点启动一个Worker进程,了解每台机器的资源有多少,并将这些信息汇报各Master进程。
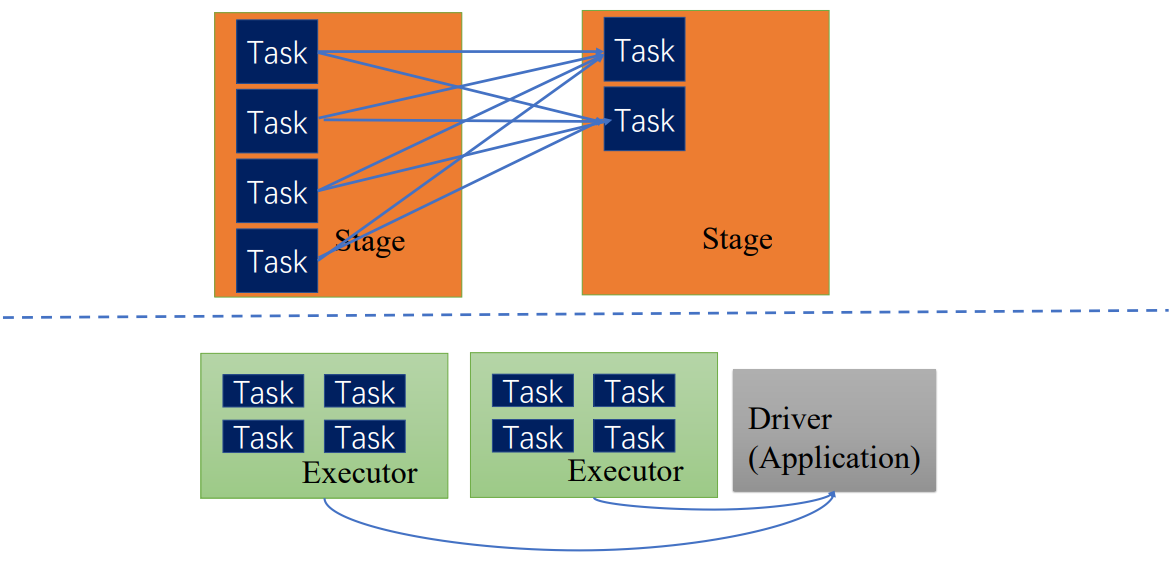
每个提交的作业程序对应一个Driver和多个Executor,每个Executor执行具体的任务。
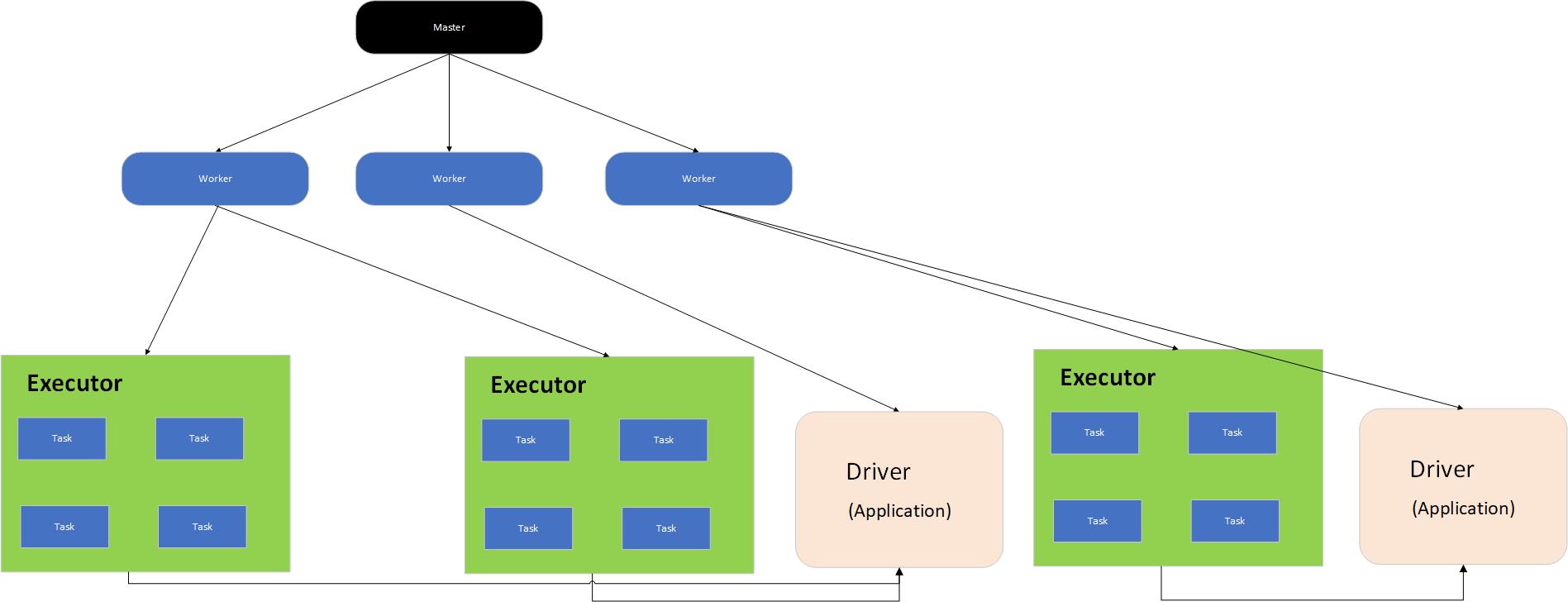
图 Spark基本运行架构
二、运行模式
- Local
- 伪分布式
- Standalone
- Yarn/K8S
三、作业执行流程
1.提交Spark应用到机器上
程序jar包提交到机器上,程序在服务器上叫Application
通过Spark-submit执行提交的Application
Application提交到公用的集群上,有两种资源分配方式:
- FIFO,先提交的先执行,后提交的等待
- FAIR,提交的作业都分配一些资源
2. 提交后会在本地客户端启动Driver进程
standalonde会通过反射的方式,创建和构造一个DriverActor进程出来
Driver进程会执行我们的Application应用程序,也就是我们编写的代码。
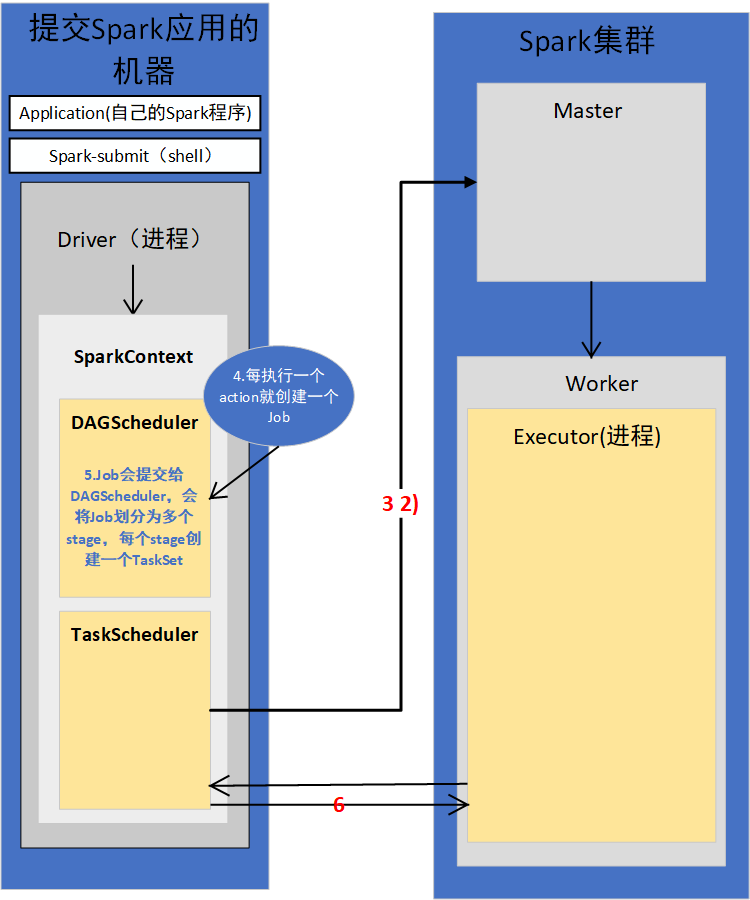
3.构造SparkContext
代码首先构造SparkConf,再构造SparkContext
1)SparkContext初始化
SpakrContext初始化时,最重要的两件事是构造出DAGSchedule和TaskSchedule。
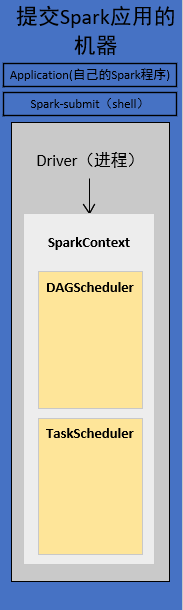
2)TaskScheduler会通过对应的后台进程去连接Master
TaskScheduler有自己的后台进程
会向Master注册Application
3)Master接收到Application的注册请求后,会使用自己的资源调度算法,在Spark集群的Worker上,为这个Application启动多个Executor
4)Worker会为Application启动Executor
5)Executor启动之后会自己反向注册到TaskScheduler上去
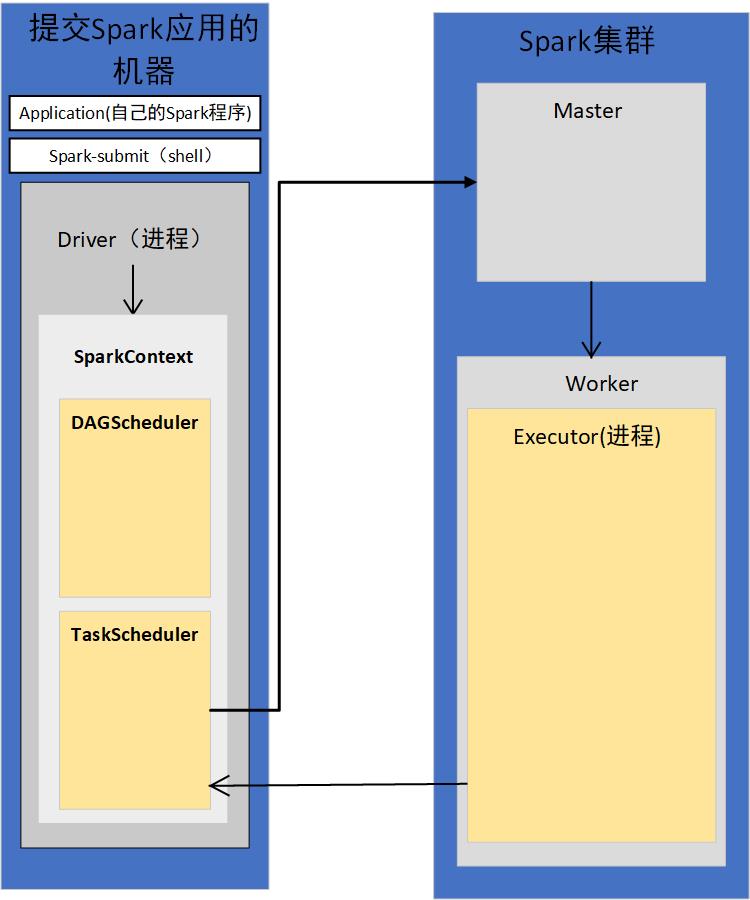
所有Executor都反向注册到Driver上之后,Driver结束Context初始化,会继续执行我们自己编写的代码。
4.每执行一个action就会创建一个Job,Job会提交给DAGScheduler
5.DAGScheduler会将Job划分为多个stage,然后每个stage创建TaskSet
stage划分算法非常重要
6.TaskScheduler会把TaskSet每一个task提交到Executor上执行
task分配算法非常重要
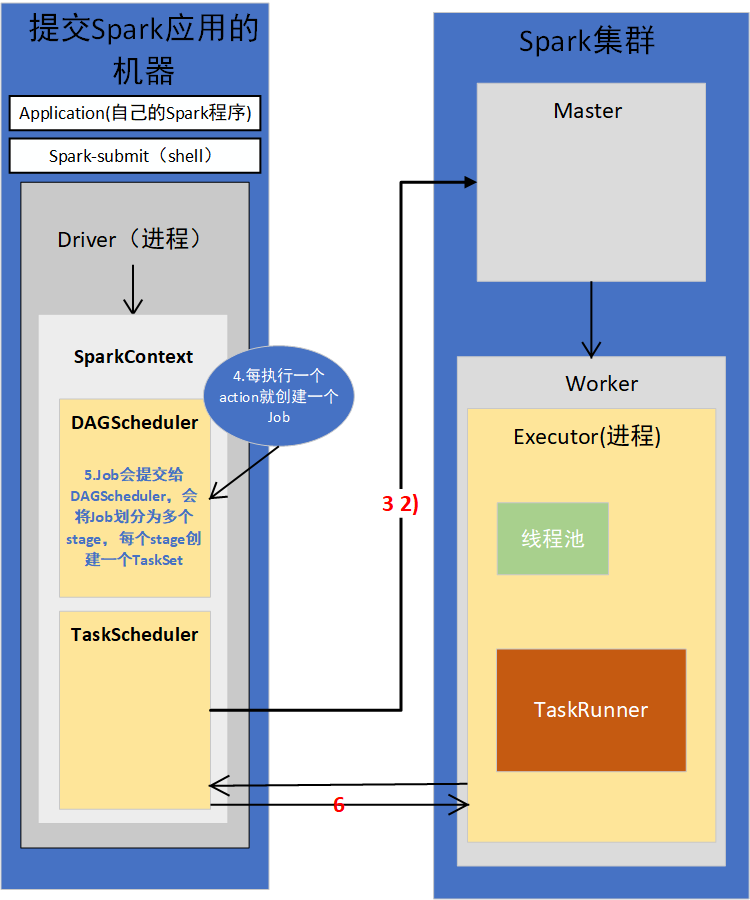
7.Executor每接收一个task,都会用TaskRunner来封装task,然后从线程池里取出一个线程,执行这个task
8.TaskRunner将我们编写的代码,也就是要执行的算子以及函数,拷贝,反序列化,然后执行Task
Task有两种,ShuffleMapTask和ResultTask,只有最后一个stage是ResultTask,之前的stage,都是ShuffleMapTask。
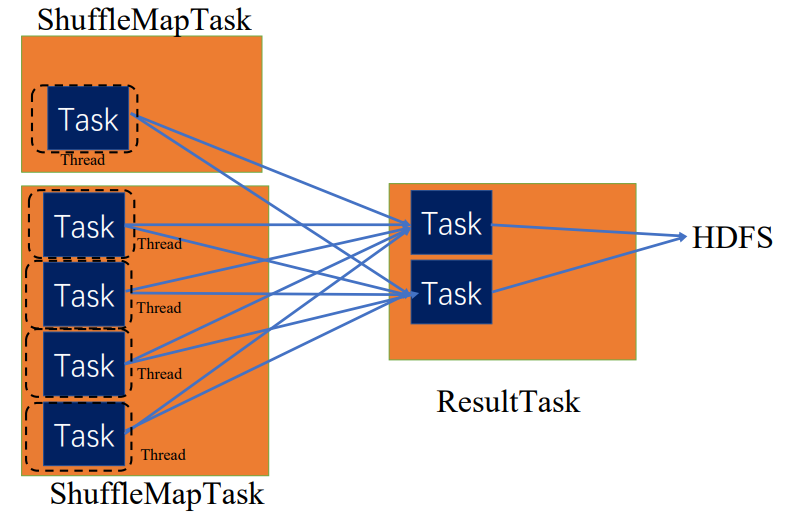
所以,最后整个Spark应用程序的执行,就是stage划分批次为TaskSet,提交到executor执行,每个task针对RDD的一个partition,执行我们定义的算子和函数。以此类推,直到所有操作都执行完为止。
四、作业流程再探讨
简单来说,是将spark程序翻译成spark core可执行的Task的过程
1.BSP(Bulk synchronous parallel)并行模型
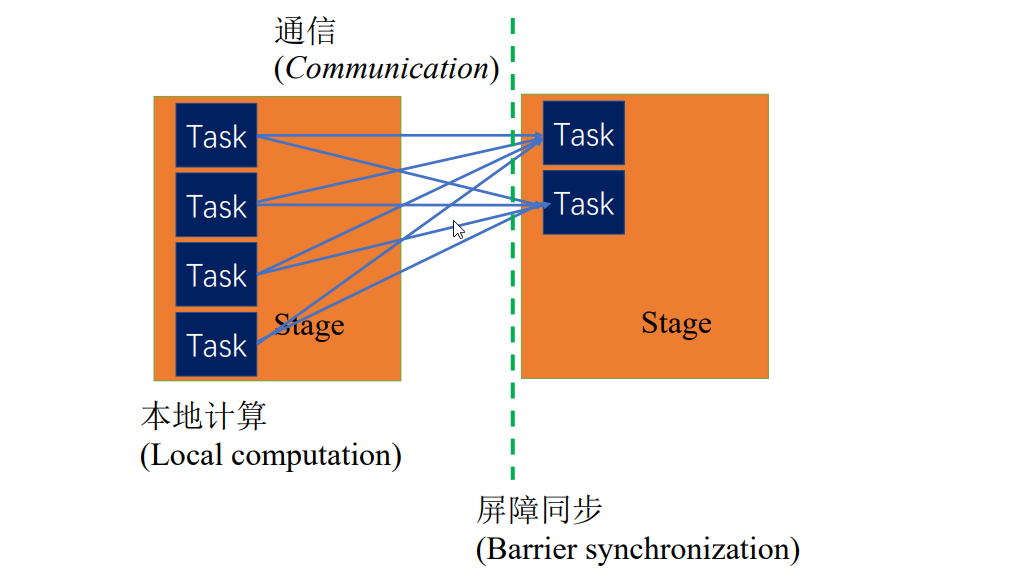
比如,wordcount程序,首先是并行的本地的过滤操作,将字符串转为单词,该过程可以拆成多个同质的Task,这些Task之间没有依赖
单词聚合的时候,就产生了依赖,会等待前一个阶段所有任务都执行完,屏障同步
分布式环境中,前后阶段可能在不同节点上,会产生通信
同步体现在上一阶段任务全执行完,下一阶段任务才可以执行
异步模型,上一阶段有些任务没执行完,有些任务执行完,下一阶段就可以启动
2.Word Count
提交作业后,作业会像master请求一些资源,master会帮忙启动driver进程和Executor进程,服务于word count程序,这个程序打包为jar包,分发到driver上,driver会启动二进制打好的包,包启动之后,会将作业编译解析成细粒度的Task。Task执行顺序,由driver决定,编译成一个个stage,每个stage有具体的Task,这样一步步按顺序并行执行,直到最后顺利完成job,将作业状态汇报给管理者,可以通过日志等查询。
创建逻辑查询计划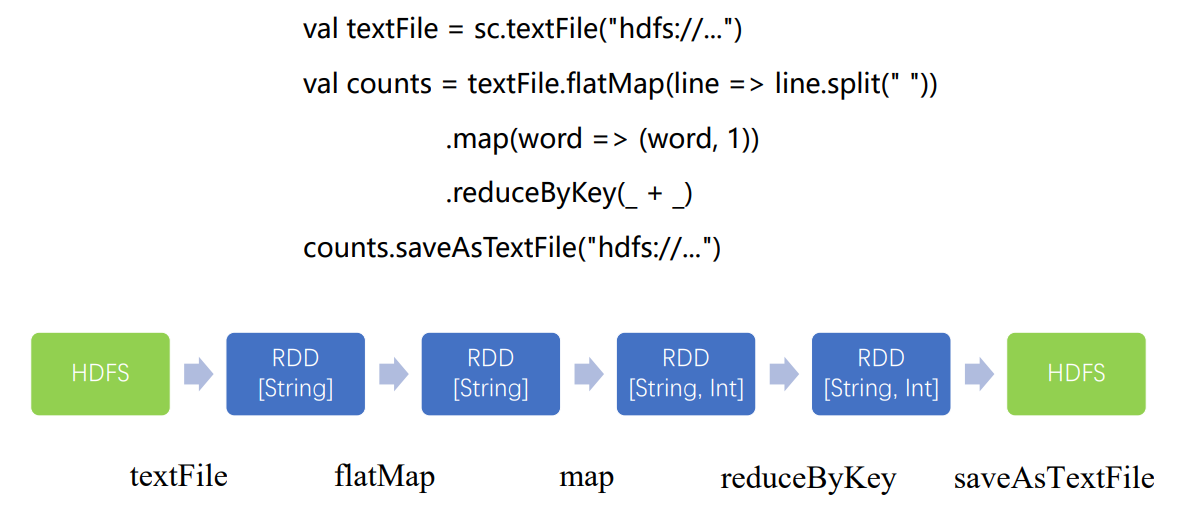
创建物理查询计划
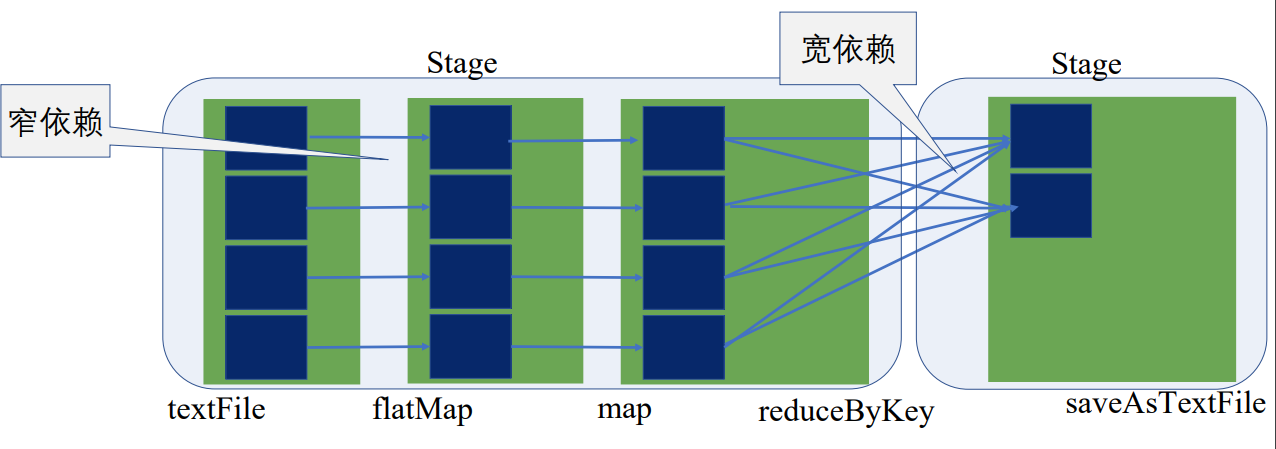
flatMap、map的操作只是将单条记录,将输入是一行的字符串转成了(String, int)类型,这一过程完全可以在本地运算,和集群上其他节点是没有关联的,可以通过操作符的合并将前三步合并为一个stage,不能合并的聚合操作成为了另一个stage
宽窄依赖是划分stage的依据
这就是创建物理查询计划,防止出现大量的RDD,减少任务的调度开销
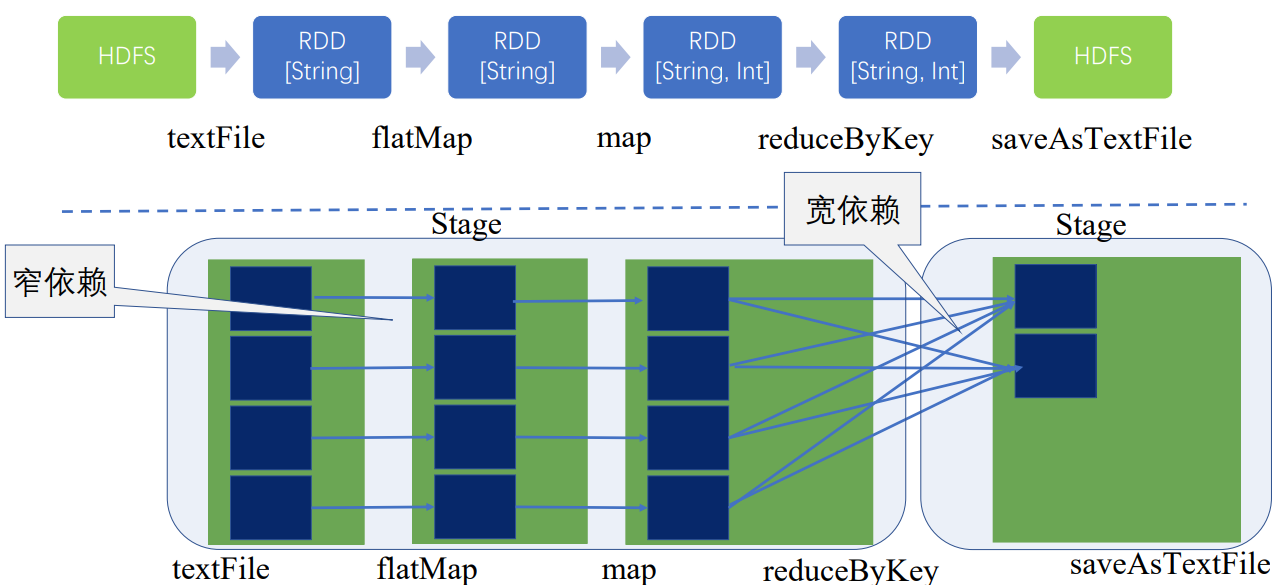
在同一个stage内,根据数据划分规则,或数据块的数量等拆分成多个并行的任务,下面拆分成了四个并行的任务,每个Task都按顺序执行了textFile、flatMap、map
因此,同一个stage是同质同样的Task的集合
只有当前一个stage所有任务完成后,下一个stage才执行
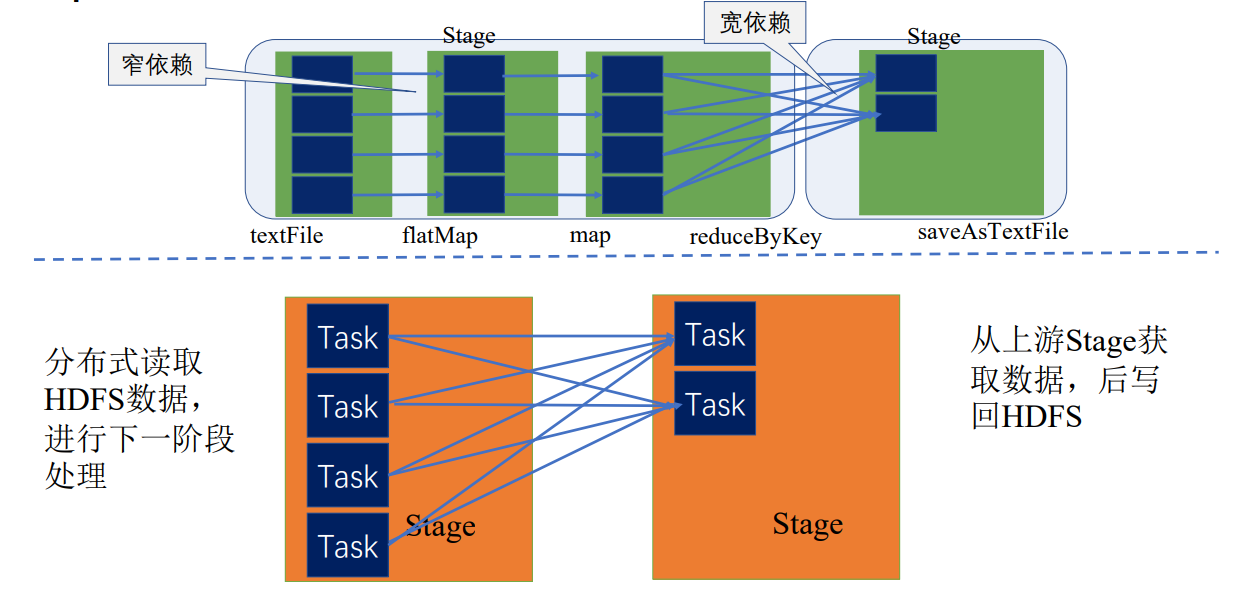
Driver中的TaskScheduler会调度Task,根据executor汇报的资源情况和stage中Task的执行情况,调度到executor上执行,executor会具体分配线程执行Task,执行完后会将Task执行正确完成状态分发返回给driver,driver再根据情况去调度,直到该stage所有Task执行完毕,才执行下一个stage的Task
DAGScheduler和TaskScheduler
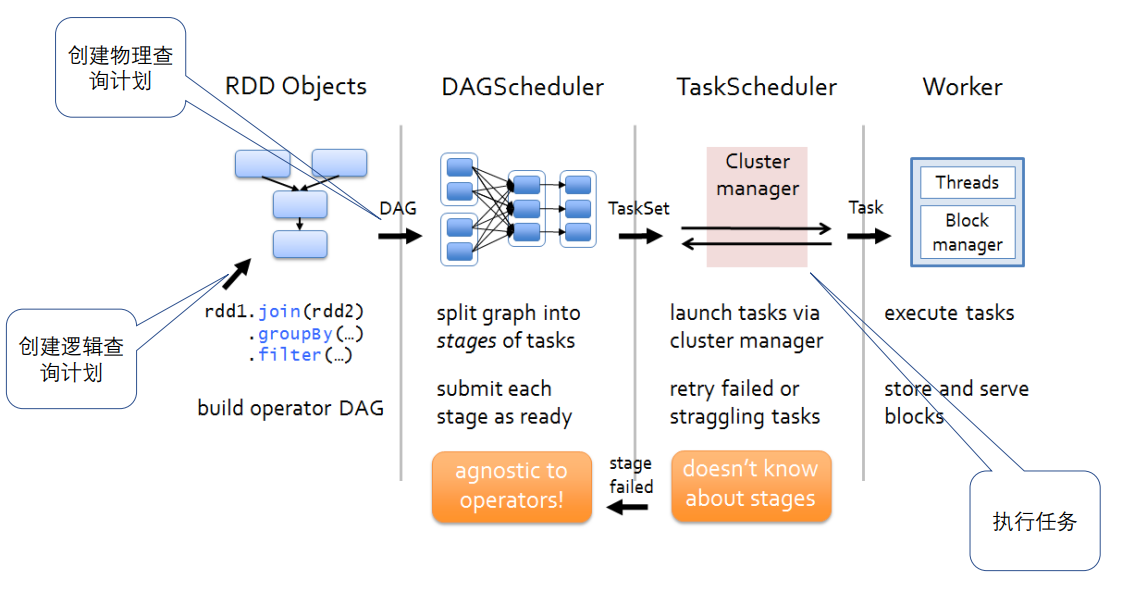
DAGScheduler将逻辑查询计划转为物理查询计划,切分为stage,stage内部会产生TaskSet
TaskScheduler调度TaskSet中具体的Task
Executor上由Block manager管理它能对应执行的数据块,即相应的partition,分配给Task,分配线程执行具体任务,执行过程组件会汇报状态给相应调度器
Spark作业层级
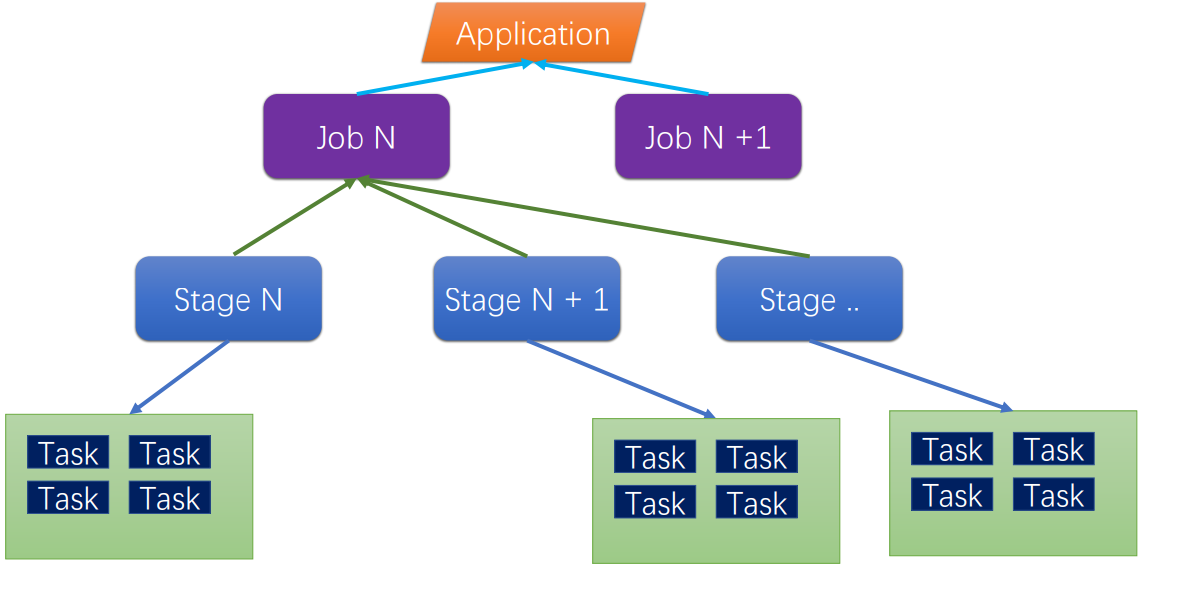
- job : A job is triggered by an action, like count() or saveAsTextFile(). Click on a job to see information about the stages of tasks inside it. 所谓一个 job,就是由一个 rdd 的 action 触发的动作,可以简单的理解为,当你需要执行一个 rdd 的 action 的时候,会生成一个 job。
- stage : stage 是一个 job 的组成单位,就是说,一个 job 会被切分成 1 个或 1 个以上的 stage,然后各个 stage 会按照执行顺序依次执行。
- task : A unit of work within a stage, corresponding to one RDD partition。即 stage 下的一个任务执行单元,一般来说,一个 rdd 有多少个 partition,就会有多少个 task,因为每一个 task 只是处理一个 partition 上的数据。
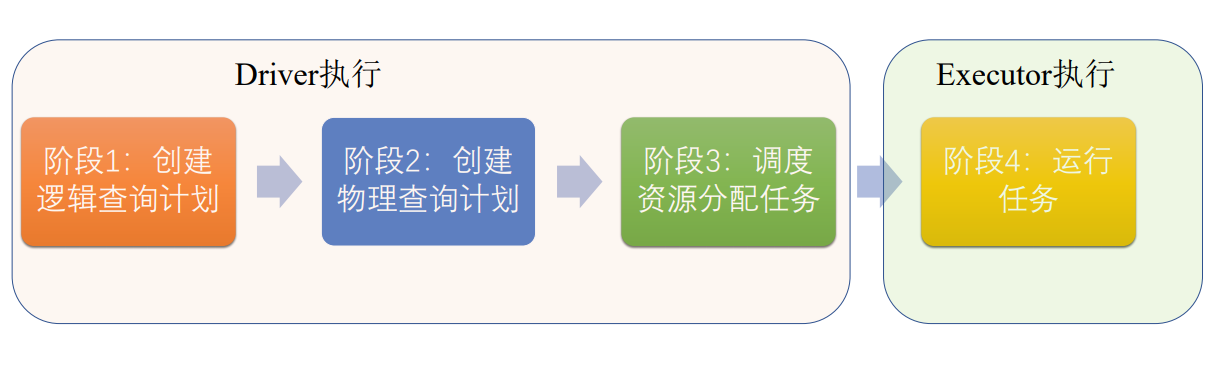
Driver阶段Spark作业翻译为可执行的任务
Executor会执行任务
阶段一: 创建逻辑查询计划,将程序翻译为一步步的RDD的操作
阶段二:根据宽窄依赖创建物理查询计划,切分出stage合并操作符
阶段三:将stage切分为同质的任务,变成可调度任务,将任务调度到空闲的资源上
阶段四:根据Executor空闲资源执行Task
五、Shuffle
根据宽窄依赖切分stage
stage和stage之间,宽依赖,由于两个stage的Task可能不在同一节点上,会在各节点间产生通信
节点间的拷贝需要Shuffle机制的支持
Spark的Shuffle经过了几次的演变
最原始的
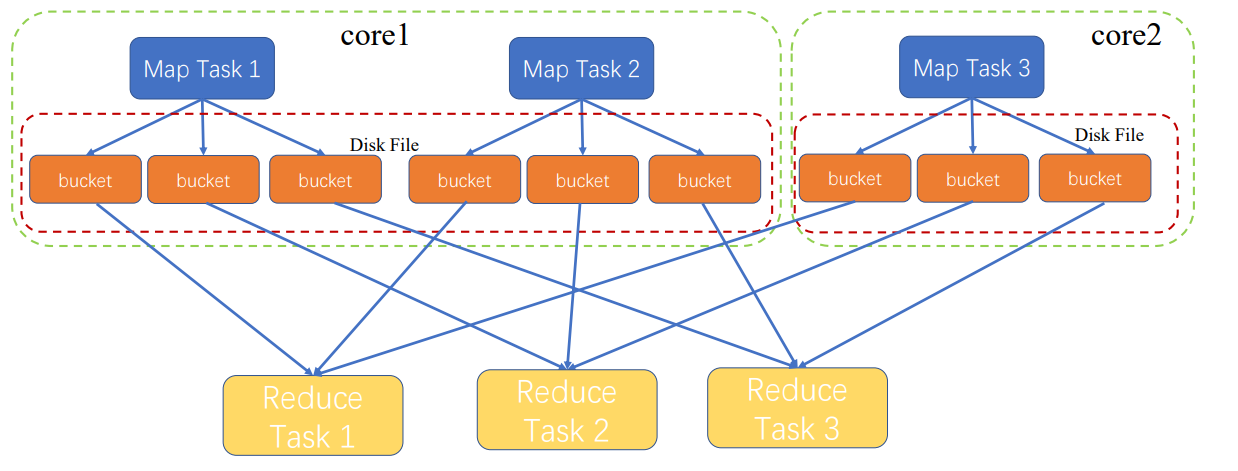
MapTask1执行之后,才执行MapTask2
蓝色Map是一个stage
黄色Reduce是另一stage
MapTask都会输出三个文件,因为有三个ReduceTask
文件保存到磁盘,因为中间文件太多,内存无法保存;保存到磁盘,出错也容易恢复
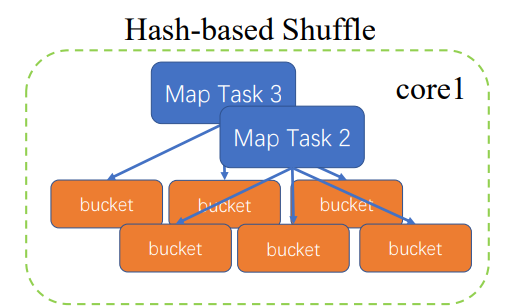
会产生MapTask数量*ReduceTask数量的文件,文件太多了
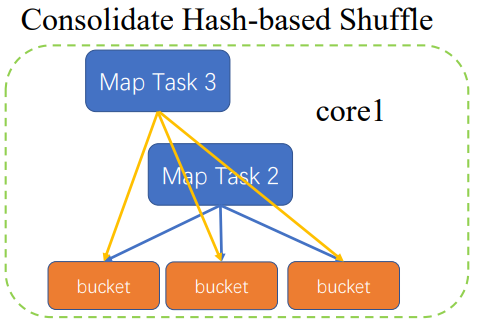
优化
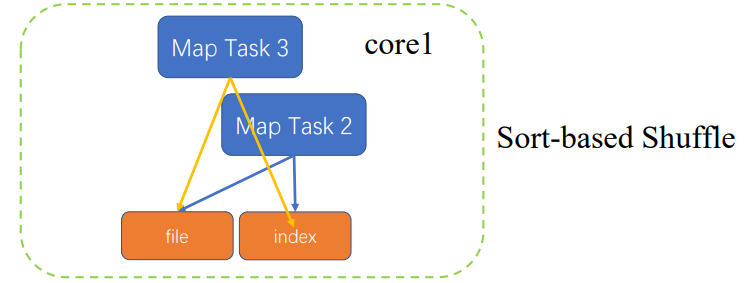
MapTask2执行完,再执行MapTask3
这是只要将MapTask3的执行结果追加到MapTask2
只要生成core数量*ReduceTask数量的文件
还是会随着ReduceTask增加而性性增加
再次优化
根据partitionkey做排序,属于哪个ReduceTask,排序好之后,生成相应的文件,并根据partitionkey对文件生成索引,MapTask3也会缓存相应结果,进行排序之后,会和之前MapTask2生成的文件做mergesort,合并成一个文件,更新索引
只产生两个文件
计算开销加大了些