缓存雪崩
缓存雪崩指的是,大量的应用无法在 Redis 缓存中处理,然后大量请求发送到了数据库,导致数据库的压力激增,甚至可能导致数据库崩溃,从而导致整个系统崩溃,引发雪崩一样的连锁效应。
而引起缓存雪崩的原因,一般如下:
1、缓存中大量 key 同时过期
2、Redis 实例挂掉了,无法处理请求
对于原因 1,在实际应用中应当避免大量 key 同时过期的场景。如果确实有这种业务场景,可以微调这批 key 过期的时间,使其能有一定的相差间隔。
对于原因2,之前提到的Redis 主从集群其实可以比较好地实现主 Redis 实例挂掉后,能有其他从库快速切换为主库,继续提供服务。
当然,以上都是预防的措施,如果已经发生了 缓存雪崩,为了防止数据库被大量的请求搞崩溃,可以采用 服务熔断 或者 请求限流。
服务熔断就是暂停对业务提供 Redis 服务,直到 Redis 恢复正常,再向外提供服务。 当然,这种情况下,业务也会整个停摆了。 另外一种比较温和的办法就是请求限流。请求限流顾名思义,就是限制请求的流量,随机丢弃一部分的请求,以保证不会同时有太多请求压入数据库。
缓存击穿
缓存击穿是指,针对某个热点数据,突然在缓存中失效,然后这些请求到热点数据的请求会都请求到数据库。
缓存击穿一般是热点 key 在 Redis 中过期了导致的。 最直接的方法就是,对于热点 key ,就不设置过期时间。
缓存穿透
缓存穿透指的是,数据既不在 Redis 中,也不在数据库中。每次请求 Redis 发现没有对应的 key之后,再去请求数据库,发现数据库也没有。 那么这时, Redis 就相当于一个摆设,没有具体的作用了。如果有人恶意攻击系统,故意使用空值或者其他不存在的值进行频繁请求,那么也会对数据库造成比较大的压力。
为了避免缓存穿透,我们可以:
1、缓存空值或缺省值
2、采用布隆过滤器,提前判断是否有此数据。
布隆过滤器实际上就是把 key 通过三次不同的哈希,计算出三个哈希值,然后在哈希表中把对应哈希值位置置为1。当有新的请求过来时,先判断这个 key 经过N次哈希后,对应的哈希值位置是否为1,只要有一个不为1,就说明此 key 之前没有缓存过。
实际上,布隆过滤器也是有缺陷的,它不能完全保证请求过来的 key ,通过布隆过滤器的校验,就一定有这个数据。 但是,只要没有通过布隆过滤器的校验,那么这个 key 就一定不存在。 其实这样就已经可以过滤掉大部分不存在的 key 请求了。
正如以上提到的布隆过滤器缺陷,如果布隆过滤器的哈希槽过短,很有可能导致大部分的位置都为 1 ,那么此时,布隆过滤器就失去了它的意义。 所以,当我们发现布隆过滤器大部分位置都为1了,应该要扩宽哈希槽。
3、在实际业务中,我们对于请求的参数应该要先进行校验,请求的参数应该要在规定范围内。实际上,在工程应用中,主要也是依赖于参数的校验,过滤掉很多无效请求。
数据不一致性
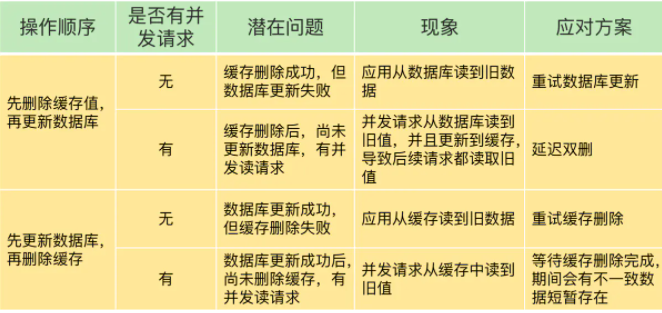
当使用 Redis 作为数据库缓存时,可能会存在数据不一致的问题。
当需要修改一份数据时,需要同时修改数据库和缓存,那么这里就要区分:先修改数据库还是修改缓存;对于缓存,是直接修改数据还是删除数据?