一、并行复制的背景
首先,为什么会有并行复制这个概念呢?
1. DBA都应该知道,MySQL的复制是基于binlog的。
2. MySQL复制包括两部分,IO线程 和 SQL线程。
3. IO线程主要是用于拉取接收Master传递过来的binlog,并将其写入到relay log
4. SQL线程主要负责解析relay log,并应用到slave中
5. 不管怎么说,IO和SQL线程都是单线程的,然后master却是多线程的,所以难免会有延迟,为了解决这个问题,多线程应运而生了。
6. IO多线程?
6.1 IO没必要多线程,因为IO线程并不是瓶颈啊
7. SQL多线程?
7.1 没错,目前最新的5.6,5.7,8.0 都是在SQL线程上实现了多线程,来提升slave的并发度
二、重点
是否能够并行,关键在于多事务之间是否有锁冲突,这是关键。 下面的并行复制原理就是在看如何让避免锁冲突
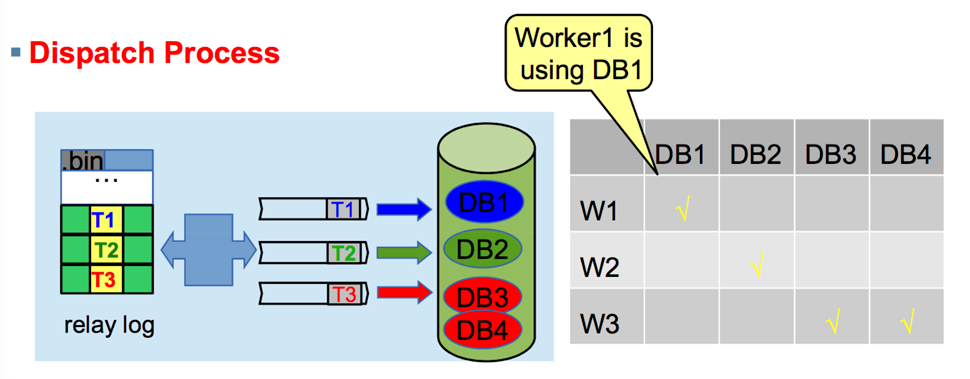
三、MySQL5.6 基于schema的并行复制
slave-parallel-type=DATABASE(不同库的事务,没有锁冲突)
之前说过,并行复制的目的就是要让slave尽可能的多线程跑起来,当然基于库级别的多线程也是一种方式(不同库的事务,没有锁冲突)
先说说优点: 实现相对来说简单,对用户来说使用起来也简单
再说说缺点: 由于是基于库的,那么并行的粒度非常粗,现在很多公司的架构是一库一实例,针对这样的架构,5.6的并行复制无能为力。当然还有就是主从事务的先后顺序,对于5.6也是个大问题
话不多说,来张图好了
四、MySQL5.7 基于group commit的并行复制
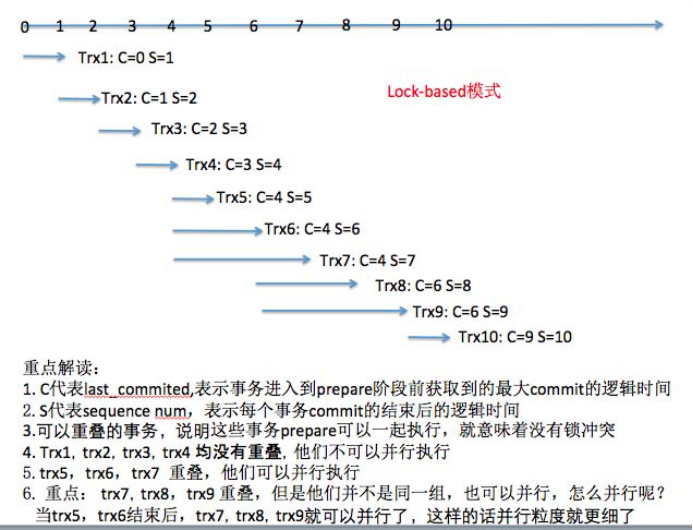
slave-parallel-type=LOGICAL_CLOCK : Commit-Parent-Based模式(同一组的事务[last-commit相同],没有锁冲突. 同一组,肯定没有冲突,否则没办法成为同一组)
slave-parallel-type=LOGICAL_CLOCK : Lock-Based模式(即便不是同一组的事务,只要事务之间没有锁冲突[prepare阶段],就可以并发。 不在同一组,只要N个事务prepare阶段可以重叠,说明没有锁冲突)
group commit,之前的文章有详细描述,这里不多解释。MySQL5.7在组提交的时候,还为每一组的事务打上了标记,现在想想就是为了方便进行MTS吧。
我们先看一组binlog
last_committed=0 sequence_number=1
last_committed=1 sequence_number=2last_committed=2 sequence_number=3last_committed=3 sequence_number=4last_committed=4 sequence_number=5last_committed=4 sequence_number=6last_committed=4 sequence_number=7last_committed=6 sequence_number=8last_committed=6 sequence_number=9last_committed=9 sequence_number=104.1 Commit-Parent-Based模式

4.2 Lock-Based模式
五、MySQL8.0 基于write-set的并行复制
基于主键的冲突检测(binlog_transaction_depandency_tracking = COMMIT_ORDERE|WRITESET|WRITESET_SESSION, 修改的row的主键或非空唯一键没有冲突,即可并行)
5.7.22 也支持了 write-set 机制
事务依赖关系:binlog_transaction_depandency_tracking = COMMIT_ORDERE|WRITESET|WRITESET_SESSION
COMMIT_ORDERE: 继续基于组提交方式
WRITESET: 基于写集合决定事务依赖
WRITESET_SESSION: 基于写集合,但是同一个session中的事务不会有相同的last_committed
事务检测算法:transaction_write_set_extraction = OFF| XXHASH64 | MURMUR32
MySQL会有一个变量来存储已经提交的事务HASH值,所有已经提交的事务所修改的主键(或唯一键)的值经过hash后都会与那个变量的集合进行对比,来判断改行是否与其冲突,并以此来确定依赖关系
这里说的变量,可以通过这个设置大小: binlog_transaction_dependency_history_size
这样的粒度,就到了 row级别了,此时并行的粒度更加精细,并行的速度会更快,某些情况下,说slave的并行度超越master也不为过(master是单线程的写,slave也可以并行回放)
六、如何让slave的并行复制和master的事务执行的顺序一致呢
5.7.19 之后,可以通过设置 slave_preserve_commit_order = 1
官方解释: slave_preserve_commit_order = 1
For multithreaded slaves, enabling this variable ensures that transactions are externalized on the slave in the same order as they appear in the slave's relay log.Setting this variable has no effect on slaves for which multithreading is not enabled.
All replication threads (for all replication channels if you are using multiple replication channels) must be stopped before changing this variable.
--log-bin and --log-slave-updates must be enabled on the slave.
In addition --slave-parallel-type must be set to LOGICAL_CLOCK.
Once a multithreaded slave has been started, transactions can begin to execute in parallel.
With slave_preserve_commit_order enabled, the executing thread waits until all previous transactions are committed before committing.
While the slave thread is waiting for other workers to commit their transactions it reports its status as Waiting for preceding transaction to commit.
大致实现原理就是:excecution阶段可以并行执行,binlog flush的时候,按顺序进行。 引擎层提交的时候,根据binlog_order_commit也是排队顺序完成
换句话说,如果设置了这个参数,master是怎么并行的,slave就怎么办并行
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,如果有疑问大家可以留言交流,谢谢大家对脚本之家的支持。
5.6开启并行复制
mysql> stop slave;
mysql> set global slave_parallel_workers=4;
mysql> start slave;
核心思想是:不同schema下的表并发提交时的数据不会相互影响,即slave节点可以用对relay log中不同的schema各分配一个类似SQL功能的线程,
来重放relay log中主库已经提交的事务,保持数据与主库一致。
5.7开启并行复制
mysql> stop slave;
mysql> set global slave_parallel_workers=4;
mysql> set global slave_parallel_type='LOGICAL_CLOCK';
mysql> start slave;
在MySQL 5.7中,引入了基于组提交的并行复制(Enhanced Multi-threaded Slaves),设置参数slave_parallel_workers>0并且global.slave_parallel_type='LOGICAL_CLOCK',
即可支持一个schema下,slave_parallel_workers个的worker线程并发执行relay log中主库提交的事务。
核心思想:一个组提交的事务都是可以并行回放(配合binary log group commit);
slave机器的relay log中last_committed相同的事务(sequence_num不同)可以并发执行。
其中,变量slave-parallel-type可以有两个值:DATABASE默认值,基于库的并行复制方式;LOGICAL_CLOCK:基于组提交的并行复制方式