目录
一、总览
1.1 参考论文
引领大数据前进的三驾马车分别是:
1.2 生态组件
Components of the Hadoop Ecosystem
| num | item | img |
|---|---|---|
| 1 | HDFS |  |
| 2 | MapReduce |  |
| 3 | YARN |  |
| 4 | HBase |  |
| 5 | Pig |  |
| 6 | Hive |  |
| 7 | Sqoop |  |
| 8 | Flume |  |
| 9 | Kafka |  |
| 10 | Zookeeper |  |
| 11 | Spark |  |
总体框架图:
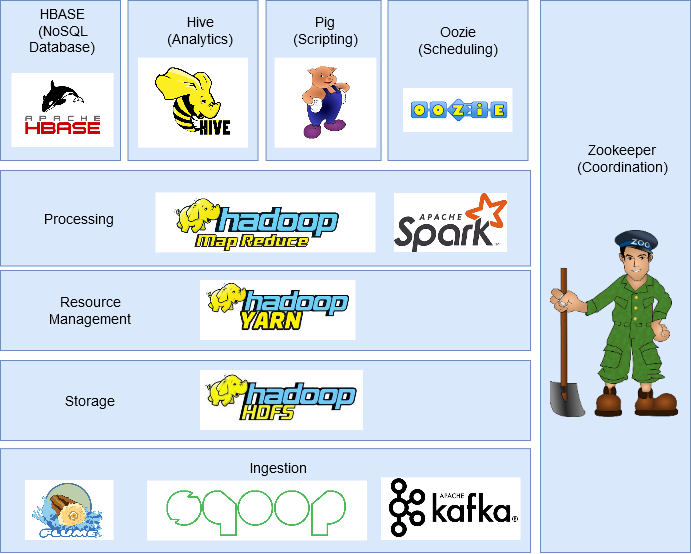
2. 各个框架
1.1 HDFS (Hadoop Distributed File System)
| item | content |
|---|---|
| 主页 | http://hadoop.apache.org/ |
| 文档 | https://hadoop.apache.org/docs/current/ |
| 介绍 | The Apache™ Hadoop® project develops open-source software for reliable, scalable, distributed computing. The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures. |
1.2 MapReduce
| item | content |
|---|---|
| 1 | 2 |
1.3 YARN
| item | content |
|---|---|
| 主页 | https://classic.yarnpkg.com/lang/en/docs/ |
| 介绍 | Yarn is a package manager for your code. It allows you to use and share (e.g. JavaScript) code with other developers from around the world. Yarn does this quickly, securely, and reliably so you don’t ever have to worry. Yarn allows you to use other developers’ solutions to different problems, making it easier for you to develop your software. If you have problems, you can report issues or contribute back, and when the problem is fixed, you can use Yarn to keep it all up to date. Code is shared through something called a package (sometimes referred to as a module). A package contains all the code being shared as well as a package.json file which describes the package. |
1.4 HBase
| item | content |
|---|---|
| 官网 | http://hbase.apache.org/ |
| 介绍 | Apache HBase™ is the Hadoop database, a distributed, scalable, big data store.Use Apache HBase™ when you need random, realtime read/write access to your Big Data. This project's goal is the hosting of very large tables -- billions of rows X millions of columns -- atop clusters of commodity hardware. Apache HBase is an open-source, distributed, versioned, non-relational database modeled after Google's Bigtable: A Distributed Storage System for Structured Data by Chang et al. Just as Bigtable leverages the distributed data storage provided by the Google File System, Apache HBase provides Bigtable-like capabilities on top of Hadoop and HDFS. |
1.5 Pig
...
1.6 Hive
...
1.7 Sqoop
...
1.8 Flume
...
1.9 Kafka
...
1.10 Zookeeper
| item | content |
|---|---|
| 主页 | http://zookeeper.apache.org/ |
| 介绍 | Apache ZooKeeper is an effort to develop and maintain an open-source server which enables highly reliable distributed coordination. What is ZooKeeper? ZooKeeper is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services. All of these kinds of services are used in some form or another by distributed applications. Each time they are implemented there is a lot of work that goes into fixing the bugs and race conditions that are inevitable. Because of the difficulty of implementing these kinds of services, applications initially usually skimp on them, which make them brittle in the presence of change and difficult to manage. Even when done correctly, different implementations of these services lead to management complexity when the applications are deployed.Learn more about ZooKeeper on the ZooKeeper Wiki. |
1.11 Spark
| item | content |
|---|---|
| 主页 | http://spark.apache.org/ |
| 文档 | http://spark.apache.org/docs/latest/ |
| 介绍 | Apache Spark™ is a multi-language engine for executing data engineering, data science, and machine learning on single-node machines or cluster |