零、摘要及背景介绍
本文是对Bidirectional LSTM-CRF Models for Sequence Tagging的总结,原文作者提出了基于LSTM(Long Short Term Memory)的一系列网络来用于序列标注。
其网络有单向LSTM、双向LSTM(BILSTM)及单向LSTM+CRF(Conditional Random Field条件随机场)和BILSTM + CRF。实验结果表明:在词性标注(part-of-speech tagging)、组块分析(chunking)和命名实体识别(Named Entity Recognition NER)三个子领域中,BILSTM+CRF模型效果最好,同时该模型还有较好的鲁棒性及对word embedding有更小依赖。
- 注:本文出现的LSTM、BILSTM都只有一层。
一、模型介绍
本部分介绍5种模型:分别是LSTM、BILSTM、CRF、LSTM+CRF 和 BILSTM+CRF.
1.1 LSTM
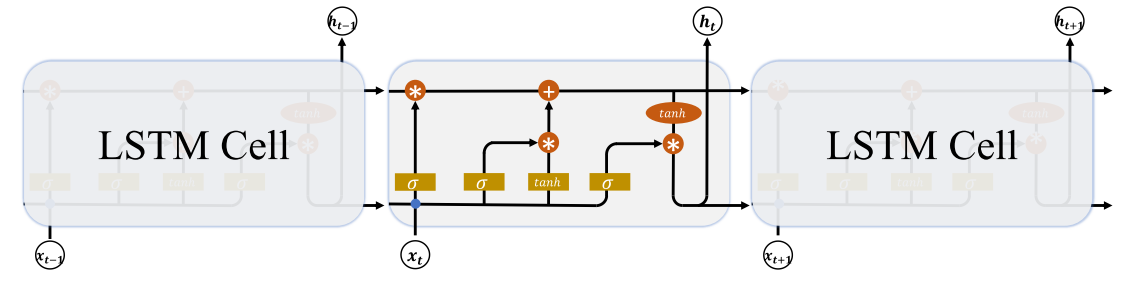
LSTM的出现是为了避免RNN在训练过程中由于梯度弥撒或梯度爆炸而导致训练无法收敛的问题。RNN的设计理论上虽说可以学习到一句话的语义信息,但RNN对长句子的语义信息捕获效果是很差的,在实际中因存在状态向量(W_h)多次累成(累成次数依赖于一个句子的单词数)而难以训练。LSTM从结构上做了改进,并提出了三道门:遗忘门(或作记忆门)、输入门和输出门,有效将(W_h)多次累成转换成有限的乘法、加法操作,使模型训练成为可能。LSTM的网络结构图如下图:
2.2 BILSTM
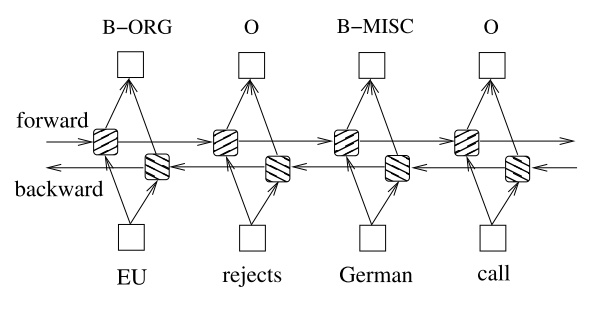
LSTM可以学习一个句子的语义信息,但它假设每个单词的语义信息只和该句之前单词语义信息有关,与之后单词意思无关。在实际场景中未必能满足这种假设,因此提出了BILSTM(双向LSTM),该模型以词embedding作为输入,分别从正向forward和反向backword两个方向学习句子的语义信息,并将学习到的结果做concat拼接,使得BILSTM所学到的语义信息满足单词既依赖于该句之前单词意思也依赖于该句之后单词意思。其网络架构图如下图:
2.3 CRF网络
CRF网络是HMM(隐马尔可夫模型)的推广,HMM假设每个隐状态只依赖于前一个隐状态,而CRF则假设任意某个隐状态可以依赖于隐变量序列中的任意隐状态。CRF和之前提到的LSTM及BILSTM不同,没有采用存储语义信息的组件,而是直接将输入和输出相连接,CRF网络结构图下图:

- 至于LSTM后为什么要加个CRF, 有人表示:
1. CRF层可以为最后预测的标签添加一些约束来保证预测的标签是合法的。在训练数据训练过程中,这些约束可以通过CRF层自动学习到的
2. CRF中有转移特征,即它会考虑输出标签之间的顺序性,也会学习一些约束规则
2.4 LSTM+CRF
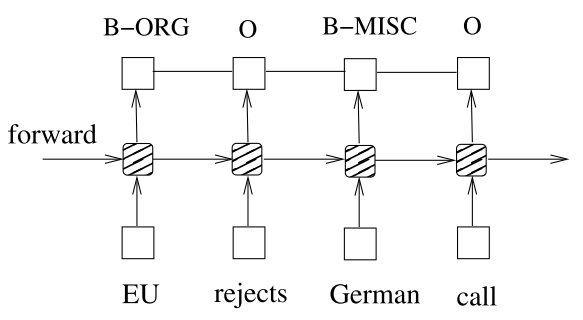
在LSTM后接入了CRF网络,其中LSTM可以有效利用已输入单词的语义特征,而CRF层可有效利用句子级标注信息,同时待训练参数中增加了CRF层的状态转移矩阵,使得模型可有效利用前后单词的标签信息来预测当前单词的标签信息。网络架构图如下:
2.5 BILSTM+CRF
本节较2.4节只把单向LSTM换成了BILSTM,为了加快训练时的收敛速度,在BILSTM+CRF中,增加将单词的embedding特征直接连接于CRF层输入,可在训练加速的情况下获得相当的准确性,2种网络架构图如下图:


二、模型训练
- 论文中的模型训练过程均使用了随机梯度下降算法(SGD)来计算前向传播和反向传播。
- 论文中的batch_size取100, 句子的最大单词数取100
- 参数定义:
- 网络的输出:(f_ heta (left [ x ight ]^T_1)), 简写为(left [ x ight ]^T_1)
- 对句子$ left [ x ight ]^T_1(的第i个标签用矩阵表示:) left [ f_ heta ight ]_{i,t}$
- i时刻到j时刻的状态转移概率:$ left [ A ight ]_{i,j}$
- 由于转移矩阵相对于词位置独立,因此定义新的网络参数:(widetilde{ heta} = hetacup left { left [ A ight ]_{i,j} forall i,j ight })
- 句子$ left [ x
ight ]^T_1$ 经分词并标注后的转移值求和如下式:
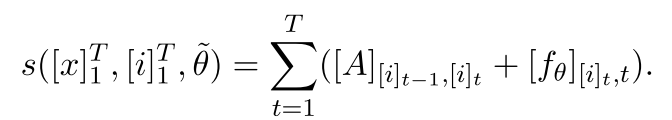
对于每个批次(batch), BILSTM+CRF训练过程如下:
1. 前向传播计算LSTM正向状态,前向传播计算LSTM反向状态
2. 计算CRF的正向和反向传播 (因为是监督学习,CRF层最后输出可计算梯度,并反向传播计算每一过程的误差)
3. 反向传播计算LSTM正向状态, 反向传播计算LSTM逆向状态
4. 更新模型参数
BILSTM+CRF的训练过程如下图所示:

三、实验及结果
-
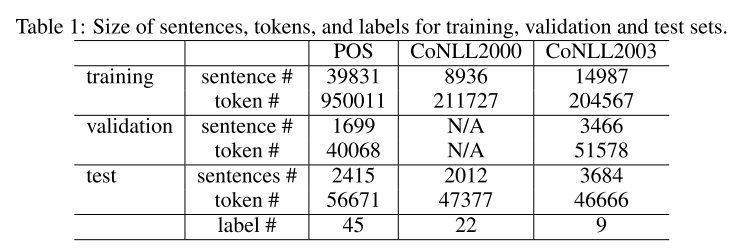
测试了第一章中5种模型的序列标注任务,分别使用Penn TreeBank(PTB)做词性标注, CoNLL 2000做组块分析, CoNLL 2003 做命名实体识别,其数据量及训练、验证、测试集情况如下图:
-
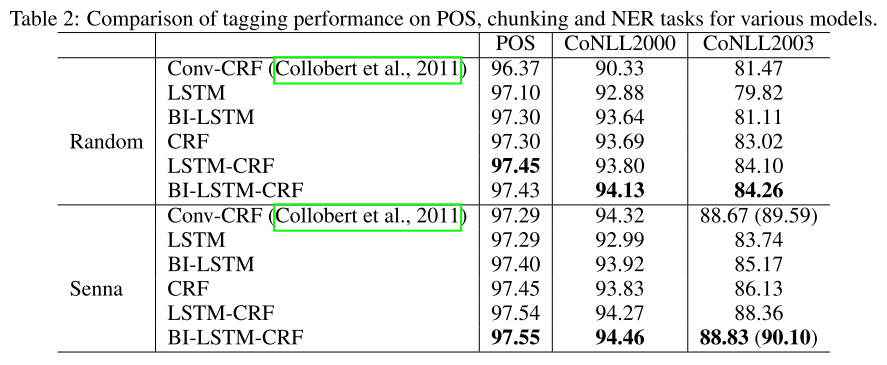
实验结果整体BILSTM+CRF最好,优于目前最好的Conv+CRF,实验结果如下图:
四、个人总结
- 论文首次提出将LSTM和CRF结合来用于序列标注任务,对比了之前最好的Conv-CRF 得出BILSTM+CRF有最好的表现结果。
- BILSTM+CRF 对word embedding有较低依赖,同时鲁棒性也最好。
- 虽未严格证明,但论文提到了两种网络结构结合的原因: 使用BILSTM可以学习并记忆句子中前后单词的语义信息,而CRF可以学习到句子间不同标签间的映射关系。
五、参考资料
- [1] TensorFlow2深度学习
- [2] BiLSTM-CRF模型:CRF层的作用