Fine-Grained Head Pose Estimation Without Keypoints
简介
head pose estimation 经典论文,使用CNN预测三个角度值,pitch,yaw,roll,本文提出一种combined classification and regression方法,并且用了HopeNet,在BIWI、300W-LP和AFLW2000数据集上训练和测试,比使用landmark方法得到了提升,模型大小也不是特别大,能够实时。
网络结构
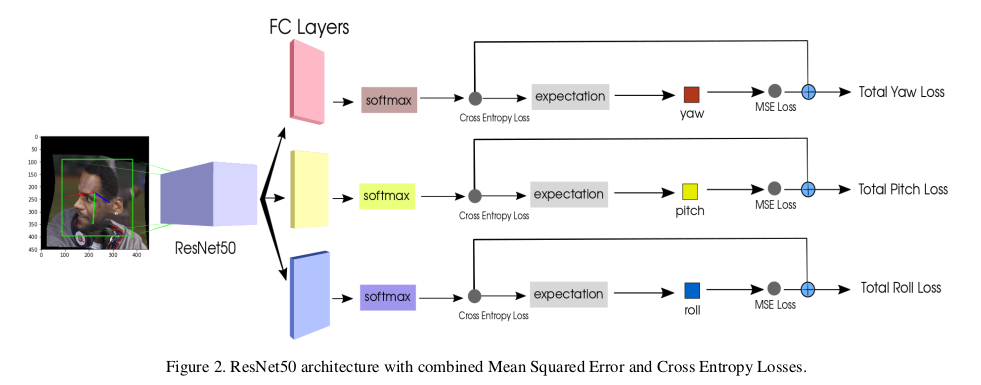
使用resnet作为backbone,分别全连接三个fc层,每个层单独预测。其中,fc层的全连接数是bin数,也就是将全部-99到+99一共199个数值每三个数分为一组,fc连接数就是66(实际上数据在超过这个范围的都剔除了,等于的剔除)。这个想法是借鉴了年龄识别的网络模型,先做分类,然后将分类的结果map到一个范围,这样精度会有大的提升。而且是multi-loss,分类的loss占比会影响梯度方向,从而会起到一个导向作用,引导回归往一个合适的方向,这是梯度方向上的引导。
对fc的结果做softmax,就把fc的值映射成了概率值,所有类别数据相加为1,映射成了概率就很方便能求出期望了,所以网络的输出又被映射到[0,99]这个区间范围内,然后乘以3减去99,这个区间范围就被映射到了[-99,+99]这个区间范围,也就是我们需要的回归。然后就是计算回归的loss,用的是mse loss。
与前面分类的loss(BCE LOSS) 按照一定权重加权求和,然后对最终的loss梯度反向,就完成了整个过程。
他这个网络两个好处,一来是利用multi-loss来引导回归,而是利用分类的结果去映射到一个可以回归的区间范围,这样就把原本是回归问题的问题转化为了分类 + 回归的问题,后来也看了其他几篇文章,基本都是转化为分类 + 回归问题来解决的,感觉这篇算是鼻祖了吧。解决思路很有效果。
数据集和实验
数据集用的是BIWI和AFLW2000,300W-LP作者只探究了高低分辨率对结果的影响。
在BIWI数据集上,划分了训练集和测试集,使用MAE作为评估标准,对比了自己的方法、FAN和直接Dlib,以及3DFFA,自己的方法在不适用深度信息的使用是SOTA的,然后去AFLW2000数据集上划分训练集和测试集去评估,只跟Gu et al.使用了CNN和RNN训练的结果做了对比,也是SOTA。
我个人感觉这个结果说服力不是很强,我自己实验的时候发现其实很难训练,想要收敛很难,网络总是会朝着局部极小值点去逼近,很难训练到一个全局极小值,即网络总是输出一个类似均值值,使得局部最小。后面也试了很多方法,训练感觉都是挺难的。网络和方法看起来很简单,但是其实挺难拟合的。