Attentional Pooling for Action Recognition
简介
这是一篇NIPS的文章,文章亮点是对池化进行矩阵表示,使用二阶池的矩阵表示,并将权重矩阵进行低秩分解,从而使分解后的结果能够自底向上和自顶向下的解释,并巧用attention机制来解释,我感觉学到了很多东西,特别是张量分解等矩阵论的知识点。
基础概念
低秩分解
目的:去除冗余并减少模型的权值参数
方法:使用两个K*1的卷积核代替掉一个K*K的卷积核
原理:权值向量主要分布在一些低秩子空间,使用少量的基就可以恢复权值矩阵
数学公式(本文):
这样就用两个1*f的矩阵去表示原来的f*f的矩阵,本文中是将矩阵做 rank-1分解,也就是分解后的矩阵a和b的秩为1,当然也需要做多组实验确定分解的秩为多少最合适。
普通池化
普通池化可以用下面的公式来表示(n = 16*16 = 256,是特征宽高乘积,f为特征通道数):
可以理解为先对特征进行在空间维度上进行全局求和,得到f个结果,然后再对这些结果利用权值矩阵加权求和就得到最终的pooling结果,pooling的结果为一个scalar。
一般avgpooling可以将该式特殊化,也就是X为n*1的张量,对每个通道执行同样的操作,1和w矩阵都是常值。maxpooling的1矩阵不为全1,最大值对应的那个位置为1.
二阶池
本文提出了二阶池的方法,具体如下:
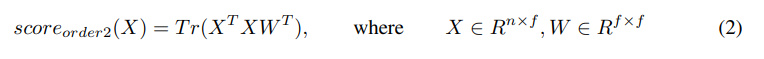
这里我直接从论文中拷出来了,没有自己手打。
这里文章说到二阶池对fine-grained classification的结果有帮助,然后把W做低秩分解,公式就变成了:

其中利用到了矩阵Tr的特点就不解释了。
那么这样分解有什么好处呢? 我觉得这就是本文的一个精髓,可以自顶向下和自底向上来解释公式,公式的可解释性为本文加分很多。
自底向上解释
我们看到公式(6)里先算的是Xb,这里得到的结果是一个n*1的矩阵,这个矩阵刚好可以看成一个attention map,那么作者对他的解释就是由底层特征到高层特征映射过程中生成的attention map,用于评估位置特征。并且,这里的b是针对每个类别都一样的,所以可以自底向上解释,而a是每个类别要学习一个特定的a,所以a的解释是自顶向下的。
自顶向下解释
如上所说,自顶向下解释主要是对a的解释,从上面的公式其实已经可以自底向上解释了,但是作者又做了一步化简:
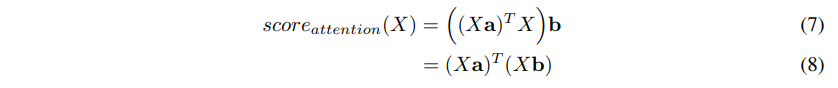
这里我们看到公式被化成了(8)式,这样其实更加直观,Xa得到的是自顶向下与类别相关的结果,而Xb得到的则是自底向上的与类别无关的结果,两者做矩阵乘,得到最终的结果。这种分解方法我感觉很奇妙,而且解释性非常好。
拓展-张量分解
详见博客:http://www.xiongfuli.com/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0/2016-06/tensor-decomposition-cp.html
CP分解
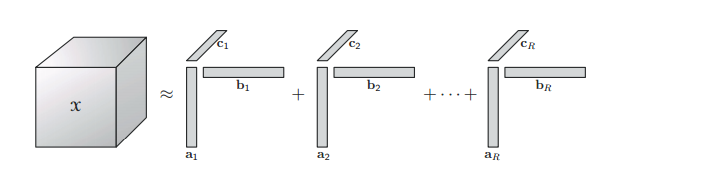
可以对张量做低秩近似,所以这里也可以做很多工作。
Tucker分解

也是一样的。上面那篇博客讲的很详细。也是可以做低秩近似。
所以这个方向是个很神奇的方向,我觉得后面可以做很多东西。需要深厚的数学功底。
网络结构
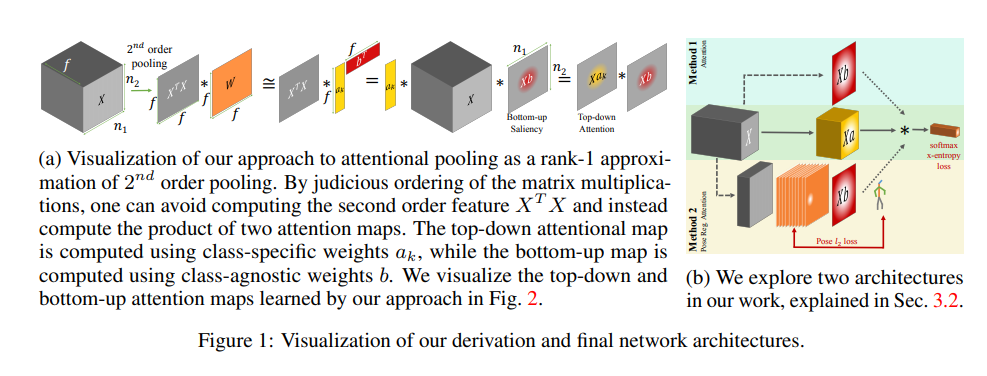
一张图带过吧。因为本位是做human pose的,所以网络结构是针对pose的。结构非常简单,用了两种方法,我们看一下method 2吧。
直接映射到17个channel的特征层,前十六个是pose map,用于预测关键点的,最后一个是attention map,这里的attention map是pose map的by-product,也就是说利用pose map去帮助分类,所以attention map再与Xa作用,最终的结果做分类,这样的一个思路。
后面实验就不看了,我也不是做这个的。。
结论
二阶池对局部特征的描述更加丰富。
低秩分解可以用来做attention。
Coding
自己实现一下文章中的method 2吧。
'''
@Descripttion: This is Aoru Xue's demo, which is only for reference.
@version:
@Author: Aoru Xue
@Date: 2019-10-27 13:11:23
@LastEditors: Aoru Xue
@LastEditTime: 2019-10-27 13:18:40
'''
import torch
import torch.nn as nn
from torchsummary import summary
from torch.autograd import Variable
class AttentionalPolling(nn.Module):
def __init__(self):
super(AttentionalPolling, self).__init__()
self.conv = nn.Conv2d(128,16,kernel_size = 1)
self.a = Variable(torch.randn(1,10,128,1))
self.b = Variable(torch.randn(1,128,1))
def forward(self,x):
feat = self.conv(x)
# (64*64,128) @ (128,1) -> (64*64,1)
#print(x.permute(0,2,3,1).view(-1,64*64,128).size())
xb = x.permute(0,2,3,1).contiguous().view(-1,64*64,128) @ self.b
#print(xb.size())
xa = x.permute(0,2,3,1).contiguous().view(-1,1,64*64,128) @ self.a
xa = xa.permute(0,1,3,2).contiguous().view(-1,10,1,4096)
xb = xb.view(-1,1,4096,1)
output = xa @ xb
print(output.size())
return output.view(-1,10)
if __name__ == "__main__":
net = AttentionalPolling()
summary(net,(128,64,64),device = "cpu") # feature X
'''
torch.Size([2, 10, 1, 1])
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 16, 64, 64] 2,064
================================================================
Total params: 2,064
Trainable params: 2,064
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 2.00
Forward/backward pass size (MB): 0.50
Params size (MB): 0.01
Estimated Total Size (MB): 2.51
----------------------------------------------------------------
'''