摘要:
1.概述
2.激活函数与导数
3.激活函数对比
4.参考链接
内容:
1.概述
深度学习的基本原理是基于人工神经网络,信号从一个神经元进入,经过非线性的activation function,传入到下一层神经元;再经过该层神经元的activate,继续往下传递,如此循环往复,直到输出层。正是由于这些非线性函数的反复叠加,才使得神经网络有足够的capacity来抓取复杂的pattern,选择怎样的activation function的标准之一是其优化整个深度神经网络的效果。
2.激活函数与导数
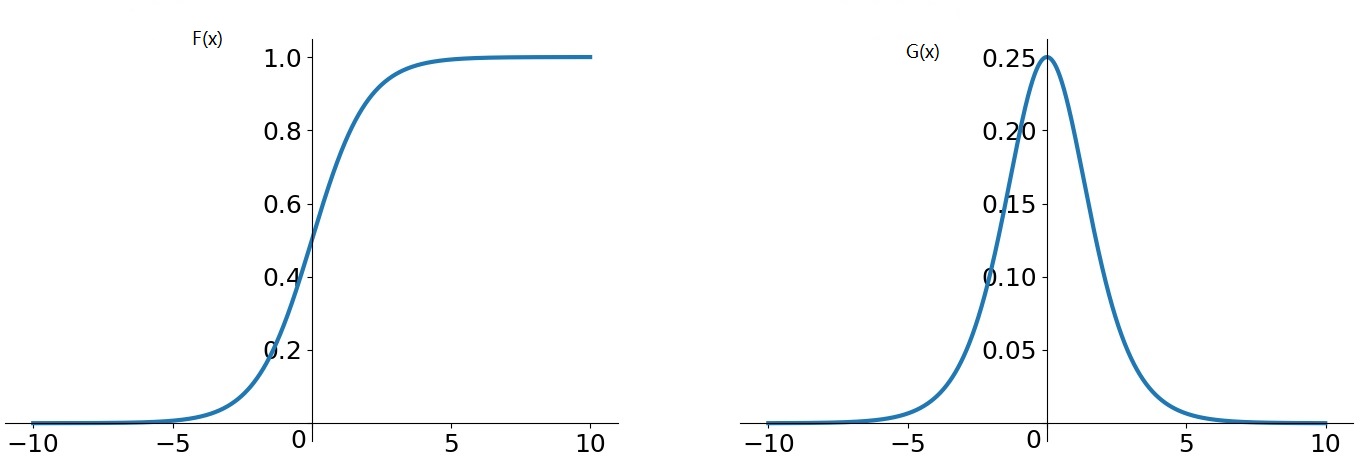
2.1 sigmoid 函数
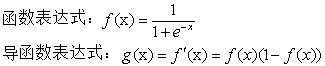
2.2 tanh函数
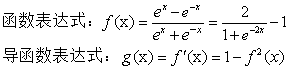

2.3ReLU函数
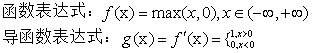
2.4ReLU的其他变种
Leaky ReLU函数,ELU (Exponential Linear Units) 函数
3.激活函数对比
3.1Sigmoid函数的优点:
1.它是便于求导的平滑函数
Sigmoid函数的缺点:
1.容易出现gradient vanishing(梯度消失),原因在于sigmoid最大梯度是0.24,两端绝对值大的点梯度为0,根据链式法则,反向传过来的梯度至少会缩小到原来的1/4,层数越多梯度越接近0.
2.函数输出并不是zero-centered, 原因在于sigmoid函数的输出是大于等于0的
3.幂运算相对来讲比较耗时
3.2tanh函数的优点:
1.解决了输出zero-centered问题,因为tanh函数输出介于区间【-1,+1】
tanh函数的缺点:
1.存在梯度消失问题
2.幂运算计算耗时
3.3ReLU函数的优点:
1.在正区间解决了梯度消失问题
2.计算速度非常快,只需要判断输入是否大于0
3.收敛速度远快于sigmoid和tanh
ReLU函数的缺点:
1.ReLU的输出不是zero-centered
2.Dead ReLU Problem(某些神经元可能永远不会被激活,导致相应的参数永远不能被更新)有两个主要原因可能导致这种情况产生: (1) 非常不幸的参数初始化,这种情况比较少见 (2) learning rate太高导致在训练过程中参数更新太大,不幸使网络进入这种状态。解决方法是可以采用Xavier初始化方法,以及避免将learning rate设置太大或使用adagrad等自动调节learning rate的算法。
4.参考链接