RDD.Action触发SparkContext.run,这里举最简单的例子rdd.count()
/** * Return the number of elements in the RDD. */ def count(): Long = sc.runJob(this, Utils.getIteratorSize _).sum
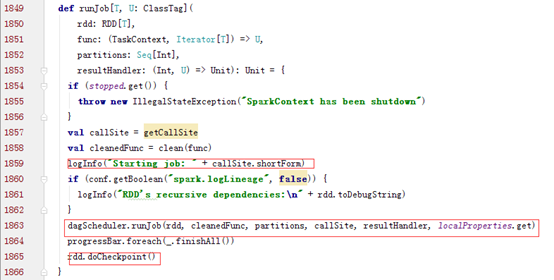
Spark Action会触发SparkContext类的runJob,而runJob会继续调用DAGSchduler类的runJob

DAGSchduler类的runJob方法调用submitJob方法,并根据返回的completionFulture的value判断Job是否完成。
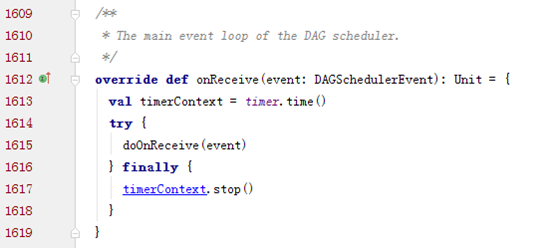
onReceive用于DAGScheduler不断循环的处理事件,其中submitJob()会产生JobSubmitted事件,进而触发handleJobSubmitted方法。

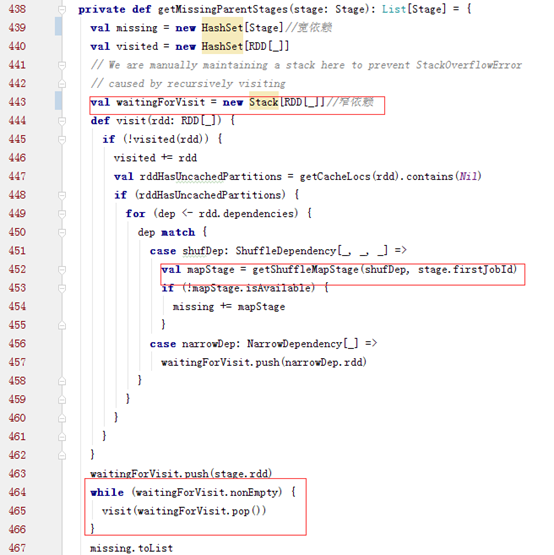
正常情况下会根据finalStage创建一个ActiveJob。而finalStage就是由spark action对应的finalRDD生成的,而该stage要确认所有依赖的stage都执行完,才可以执行。也就是通过getMessingParentStages方法判断的。

这个方法用一个栈来实现递归的切分stage,然后返回一个宽依赖的HashSet,如果是宽依赖类型就会调用
之后提交stage,根据missingStage执行各个stage。划分DAG结束

submitStage会依次执行这个DAG中的stage,如果有父stage就先执行父stage,否则就提交这个stage,加入watingstages中。

示例:
scala> sc.makeRDD(Seq(1,2,3)).count
16/10/28 17:54:59 [INFO] [org.apache.spark.SparkContext:59] - Starting job: count at <console>:13
16/10/28 17:54:59 [INFO] [org.apache.spark.scheduler.DAGScheduler:59] - Got job 0 (count at <console>:13) with 22 output partitions (allowLocal=false)
16/10/28 17:54:59 [INFO] [org.apache.spark.scheduler.DAGScheduler:59] - Final stage: Stage 0(count at <console>:13)
16/10/28 17:54:59 [INFO] [org.apache.spark.scheduler.DAGScheduler:59] - Parents of final stage: List()
16/10/28 17:54:59 [INFO] [org.apache.spark.scheduler.DAGScheduler:59] - Missing parents: List()
16/10/28 17:54:59 [INFO] [org.apache.spark.scheduler.DAGScheduler:59] - Submitting Stage 0 (ParallelCollectionRDD[0] at makeRDD at <console>:13), which has no missing parents
scala> sc.makeRDD(Seq(1,2,3)).map(l =>(l,1)).reduceByKey((v1,v2) => v1+v2).collect
16/10/28 18:00:07 [INFO] [org.apache.spark.SparkContext:59] - Starting job: collect at <console>:13
16/10/28 18:00:07 [INFO] [org.apache.spark.scheduler.DAGScheduler:59] - Registering RDD 2 (map at <console>:13)
16/10/28 18:00:07 [INFO] [org.apache.spark.scheduler.DAGScheduler:59] - Got job 1 (collect at <console>:13) with 22 output partitions (allowLocal=false)
16/10/28 18:00:07 [INFO] [org.apache.spark.scheduler.DAGScheduler:59] - Final stage: Stage 2(collect at <console>:13)
16/10/28 18:00:07 [INFO] [org.apache.spark.scheduler.DAGScheduler:59] - Parents of final stage: List(Stage 1)
16/10/28 18:00:07 [INFO] [org.apache.spark.scheduler.DAGScheduler:59] - Missing parents: List(Stage 1)
16/10/28 18:00:07 [INFO] [org.apache.spark.scheduler.DAGScheduler:59] - Submitting Stage 1 (MappedRDD[2] at map at <console>:13), which has no missing parents
collect依赖于reduceByKey,reduceByKey依赖于map,而reduceByKey是一个Shuffle操作,故会先提交map (Stage 1 (MappedRDD[2] at map at <console>:13))