使用pytorch。
一、定义模型结构
model.py
import torch.nn as nn import torch.nn.functional as F """ 定义一个类,这个类继承于nn.Module,实现两个方法:初始化函数和正向传播 实例化这个类之后,将参数传入这个类中,进行正向传播 """ """ If running on Windows and you get a BrokenPipeError, try setting the num_worker of torch.utils.data.DataLoader() to 0. """ class LeNet(nn.Module): def __init__(self):#1.初始化函数 # super解决在多重继承中调用父类可能出现的问题 super(LeNet, self).__init__() self.conv1 = nn.Conv2d(3, 16, 5) self.pool1 = nn.MaxPool2d(2, 2) self.conv2 = nn.Conv2d(16, 32, 5) self.pool2 = nn.MaxPool2d(2, 2) self.fc1 = nn.Linear(32*5*5, 120) # 全连接层输入的是一维向量,第一层节点个数120是根据Pytorch官网demo设定 self.fc2 = nn.Linear(120, 84) self.fc3 = nn.Linear(84, 10) # 10因为使用的是cifar10,分为10类 def forward(self, x):#2.正向传播 x = F.relu(self.conv1(x)) # input (3,32,32) output(16, 32-5+1=28, 32-5+1=28) x = self.pool1(x) # output(16, 28/2=14, 28/2=14) x = F.relu((self.conv2(x))) # output(32, 14-5+1=10, 14-5+1=10) x = self.pool2(x) # output(32, 10/2=5, 10/2=5) x = x.view(-1, 32*5*5) # output(32*5*5) x = F.relu(self.fc1(x)) # output(120) x = F.relu(self.fc2(x)) # output(84) x = F.relu(self.fc3(x)) # output(10) return x
二、开始训练
train.py: 包括对数据、batch、损失函数、优化器、测试环节计算准确率、迭代训练设置、模型保存等的处理和定义。
import torch import torchvision import torch.nn as nn from model import LeNet import matplotlib as plt import torchvision.transforms as transforms from torch import optim import numpy as np batch_size = 36 learning_rate = 1e-3 transform = transforms.Compose( [transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))] # 标准化 output = (input- 0.5)/0.5 ) # 50000张训练图片 trainset = torchvision.datasets.CIFAR10(root="./data", train=True, download=True, transform=transform) # 当前目录的data文件夹下.如果cifar10数据集已经下载到本地对应文件夹,令download=False。 trainloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size, shuffle=True, num_workers=0) # 在windows下,num_workers只能设置为0 # 10000张测试图片 testset = torchvision.datasets.CIFAR10(root="./data", train=True, download=True, transform=transform) # 当前目录的data文件夹下 testloader = torch.utils.data.DataLoader(testset, batch_size=10000, shuffle=True, num_workers=0) # 在windows下,num_workers只能设置为0 test_data_iter = iter(testloader) # 将testloader转换为迭代器 test_img, test_label = test_data_iter.next() # 通过next()获得一批数据 classes = ("plane", "car", "bird", "cat", "deer", "dog", "frog", "horse", "ship", "truck") # def imshow(img): # img = img / 2 + 0.5 # unnormalize反标准化过程input = output*0.5 + 0.5 # npimg = img.numpy() # 转换为numpy format # plt.imshow(np.transpose(npimg, (1, 2, 0))) # Pytorch内Tensor顺序[batch, channel, height, width],由于输入没有batch,故channel对应0,height对应1,width对应2 # # 此处要还原为载入图像时基础的shape,所以应把顺序变为[height, width, channel],所以需要np.transpose(npimg, (1, 2, 0)) # plt.show() # 打印几张图片看看 # print labels # print(''.join('%5s' % classes[test_label[j]] for j in range(4))) 此处应将testloader内的batch_size改为4即可,没必要显示10000张 # show images # imshow(torchvision.utils.make_grid(test_img)) # 实例化 Mynet = LeNet() loss_fn = nn.CrossEntropyLoss() #使用交叉熵损失函数 optimizer = optim.Adam(Mynet.parameters(), lr=learning_rate)#使用adam优化器 for epoch in range(10): # loop over the dataset multiple times, 训练十个epoch停止 running_loss = 0. for step, data in enumerate(trainloader, start=0): # enumerate返回每一批数据和对应的index # get the inputs: data is a list of [inputs, labels] inputs, labels = data # zero the parameter optimizer.zero_grad() # forward + backward + optimize outputs = Mynet(inputs) #前向传播输出 loss = loss_fn(outputs, labels) #利用交叉熵损失函数求实际输出和真实结果之间的损失 loss.backward() #反向传播 optimizer.step() #优化器更新(优化)权重参数 # print statistics running_loss += loss.item() if step % 500 == 499: # print every 500 mini-batches with torch.no_grad(): # with是一个上下文管理器 outputs = Mynet(test_img) # [batch, 10] y_pred = torch.max(outputs, dim=1)[1] # 找到最大值,即最有可能的类别,第0个维度对应batch,所以dim=1,第一个维度对应类别,[1]代表只需要index即可,即位置 accuracy = (y_pred == test_label).sum().item() / test_label.size(0) # 整个预测是在tensor变量中计算的,所以要用.item()转为数值, test_label.size(0)为测试样本的数目 print('[%d, %5d] train_loss: %.3f test_accuracy: %.3f' % (epoch + 1, step + 1, running_loss / 500, accuracy)) # 500次的平均train_loss running_loss = 0. # 清零,进行下一个500次的计算 print("Training finished") save_path = './Lenet.pth' torch.save(Mynet.state_dict(), save_path) #迭代完毕 保存模型 用于后续测试
三、测试模型
test.py
import torch import torchvision.transforms as transforms from PIL import Image from model import LeNet #数据增强 transform = transforms.Compose( [transforms.Resize((32, 32)), transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))] # 标准化 output = (input- 0.5)/0.5 ) classes = ("plane", "car", "bird", "cat", "deer", "dog", "frog", "horse", "ship", "truck") net = LeNet() net.load_state_dict(torch.load('Lenet.pth')) # 载入权重文件 im = Image.open('bird.jpg') im = transform(im) # [C, H, W] 转成Pytorch的Tensor格式 im = torch.unsqueeze(im, dim=0) # [N, C, H, W] 对数据增加一个新维度 with torch.no_grad(): outputs = net(im) predict = torch.max(outputs, dim=1)[1].data.numpy() print(classes[int(predict)])
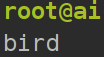
输入测试图片bird.jpg, 预测结果为bird.

python3 test.py=====>
迭代次数比较少,数据量也不大。要求准确率的可以首先在这两方面优化增强。