背景介绍:
Nginx为app打点数据,打点日志每小时滚动一次。目录结构如下
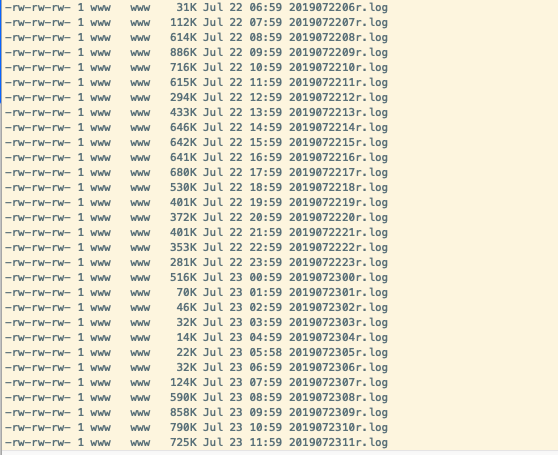
文件中的数据如下( cat -A 2019072414r.log 后的结果,-A为显示隐形的符号,下方^A为指定的分隔符。$为行尾结束符,换行的时候会自带,不用关注。)
61.140.204.111^A20190724145548^A1563951348^A^A8671a9d406bd8733bf42d9644a009660^AJYH^Awin7^A2^Ahc_GC5H6A^A^A3^A1.0^ALSEARCH^AOTHER^A1563951348^A$
123.147.250.151^A20190724145552^A1563951352^A^A8a0fc9239dd100880053b1e1d0678a37^AYEAR^Awin10^A2^Ahc_GC5H6A^A^A3^A1.0^AOPENSINPUT^AOTHER^A1563951352^A$
182.142.98.33^A20190724145553^A1563951350^Aac74b3d92fdfea6249a8188556de2215^A380b0e9844c5aa4905a952908dc7ddf9^ALZQ^Awin7^A2^Ahc_GC5H6A^A^A3^A1.0^AOPENSINPUT^AOTHER^A1563949711^A$
182.142.98.33^A20190724145553^A1563951350^Aac74b3d92fdfea6249a8188556de2215^A380b0e9844c5aa4905a952908dc7ddf9^ALZQ^Awin7^A2^Ahc_GC5H6A^A^A3^A1.0^AOPENSINPUT^AOTHER^A1563951350^A$
^A分隔的15列数据依次对应如下列。
ip,date,upload_time,uid,uuid,pbv,opv,av,ch,mac,sc,st,event_type,pg,action_time
现在需要将这部分数据收集到hive中,以供后续分析计算使用。
实施步骤一.配置flume将数据存到HDFS
1.配置flume
flume需要在nginx所在服务器上
###source a2.sources = s2#ngxlog source a2.sources.s2.type = TAILDIR a2.sources.s2.channels = c3 a2.sources.s2.filegroups = f2 a2.sources.s2.filegroups.f2 = /data/logs/nginx/event_log/.*log a2.sources.s2.positionFile=/data/logs/nginx/event_log/taildir_position.json a2.sources.s2.fileHeader = true a2.sources.s2.fileHeader=true a2.sources.s2.fileHeaderKey=file a2.sources.s2.interceptors = i3 a2.sources.s2.interceptors.i3.type = regex_extractor a2.sources.s2.interceptors.i3.regex =(\d\d\d\d\d\d\d\d\d\d\d\d\d\d) a2.sources.s2.interceptors.i3.serializers = s2 a2.sources.s2.interceptors.i3.serializers.s2.type = org.apache.flume.interceptor.RegexExtractorInterceptorMillisSerializer a2.sources.s2.interceptors.i3.serializers.s2.name = timestamp a2.sources.s2.interceptors.i3.serializers.s2.pattern = yyyyMMddHHmmss ###channel a2.channels = c3 #huochai ngxlog channel a2.channels.c3.type = memory a2.channels.c3.capacity = 50000 a2.channels.c3.transactionCapacity = 10000 a2.channels.c3.byteCapacityBufferPercentage = 20 a2.channels.c3.byteCapacity = 134217728 ###sinks a2.sinks = k3 #k3-huochai ngxlog sink a2.sinks.k3.type = hdfs a2.sinks.k3.channel = c3 a2.sinks.k3.hdfs.path = /user/flume/huochai-events/day=%Y%m%d a2.sinks.k3.hdfs.filePrefix =%Y%m%d%H a2.sinks.k3.hdfs.rollInterval = 0 a2.sinks.k3.hdfs.batchSize=1000 a2.sinks.k3.hdfs.idleTimeout=300 a2.sinks.k3.hdfs.threadsPoolSize=10 a2.sinks.k3.hdfs.rollSize = 134217728 a2.sinks.k3.hdfs.rollCount=0 ##fileType SequenceFile DataStream CompressedStream a2.sinks.k3.hdfs.fileType= SequenceFile a2.sinks.k3.hdfs.codeC= snappy
2.对flume配置的一些说明
1) source类型为TAILDIR,这个类型是flume1.7.0才出来的,不过在CDH中1.6.0版本的flume就有这个功能了,具体说明见
http://flume.apache.org/releases/content/1.7.0/FlumeUserGuide.html#taildir-source
2) positionFile配置的文件,如果不存在会自动生成,并且如果不存在,会从头读所有文件的。
3) regex_extractor这个拦截器的作用是把每条log中 20190724145548 这个格式的时间 改为 timestamp的时间,放到flume的Event消息的Header中。
意即使用regex_extractor后Header中会产生一个key-value对为(timestamp:1563951348000)
4) a2.sinks.k3.hdfs.path = /user/flume/huochai-events/day=%Y%m%d
%Y%m%d 会取timestamp中的时间,转成20190724这个格式,也就是说,一条log最终会放入到哪个路径下,是由这条log中的时间决定的。
总体流程就是: log中20190724145548 被通过 regex_extractor提取成key-value对(timestamp:1563951348000),再由sinks.k3中配置的(%Y%m%d)解析出来,获得最终的路径。
3.刷新flume配置/重启flume,查看HDFS中的结果
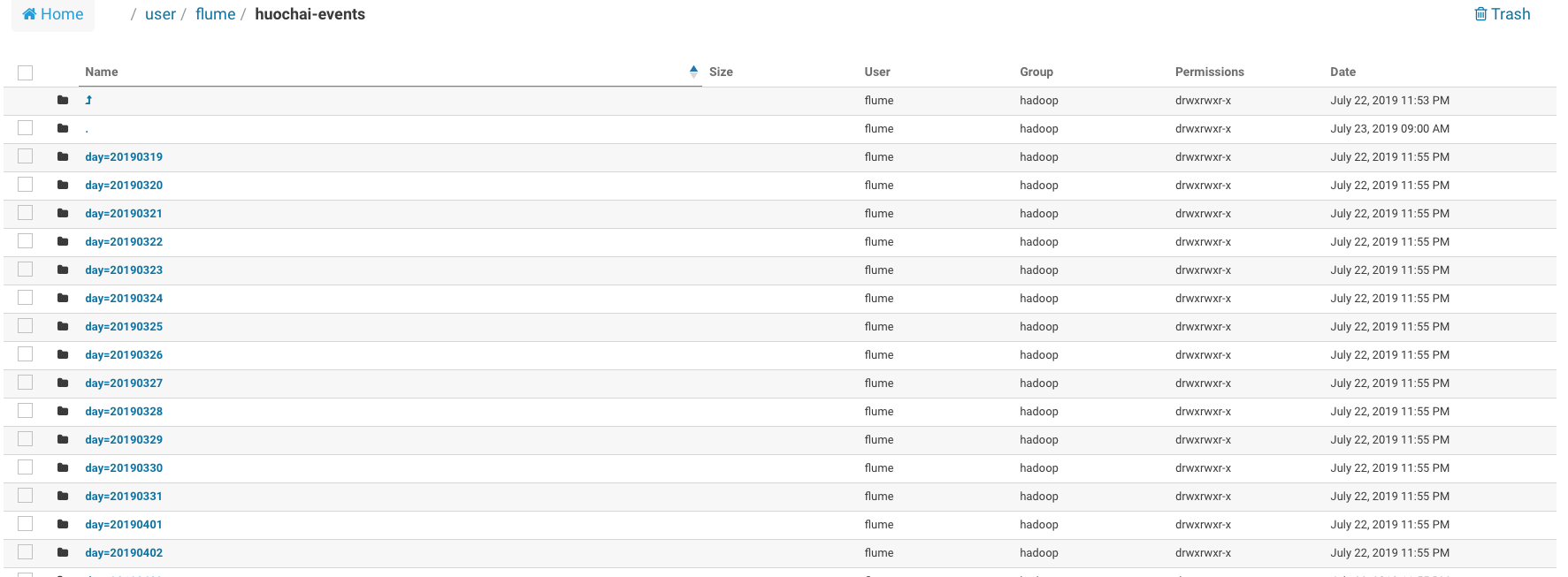
路径正常按照日期生成
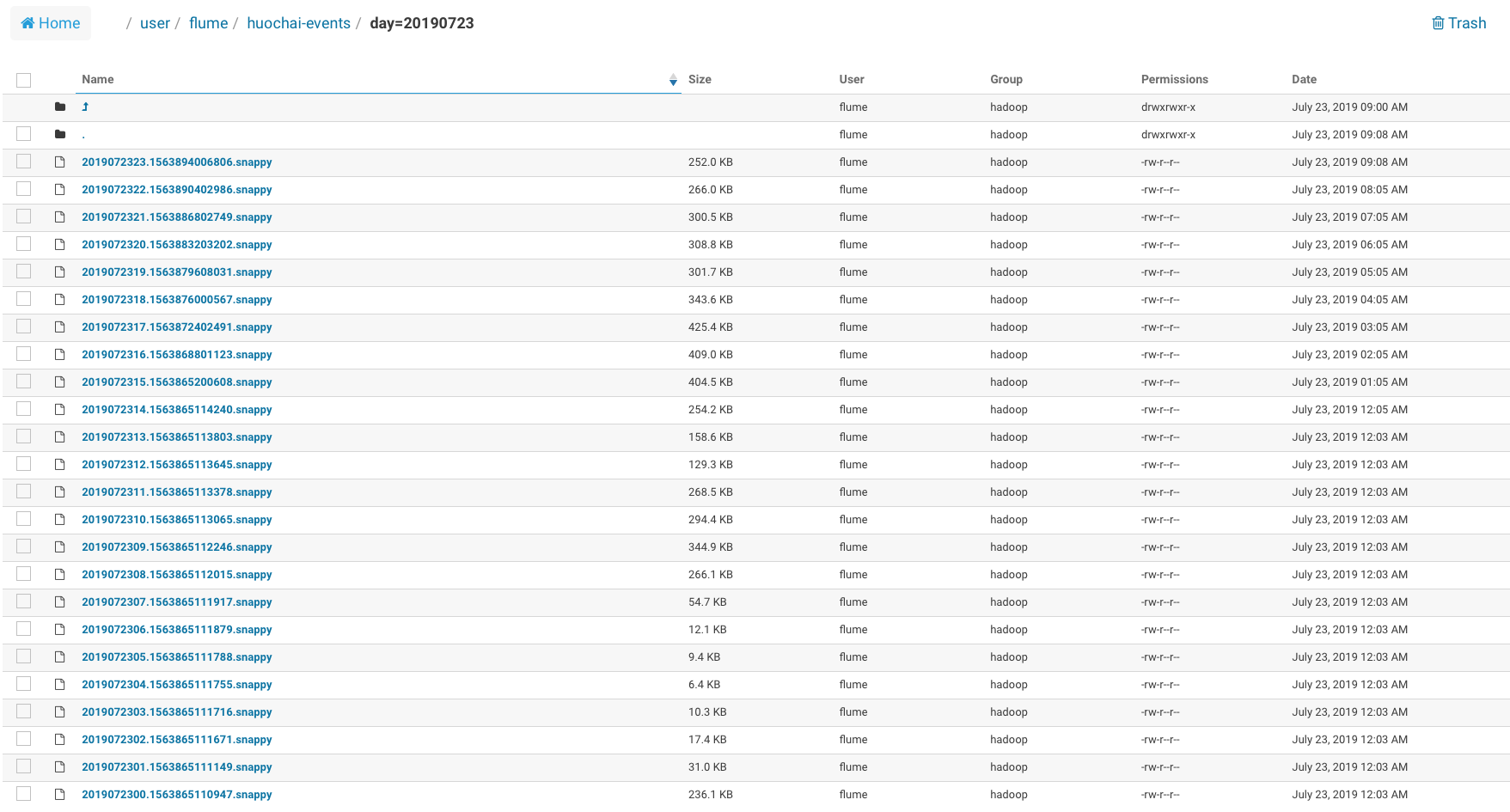
每个日期下每个小时会生成一个文件。
注解:为什么要每个小时生成一次文件
因为正在写入的文件后缀为tmp,tmp后缀的文件在hive的外部表中是没有办法读到数据的。每小时生成一次,可以保证数据最多只延迟一个小时。
实施步骤二.根据HDFS路径创建hive外部表
1.在shell客户端中连接hive。
beeline !connect jdbc:hive2://bigdata.node2:10000 hadoop 回车
2.创建外部表
CREATE EXTERNAL TABLE huochai_events ( ip STRING, date STRING, upload_time bigint, uid string, uuid string, pbv string, opv string, av string, ch string, mac string, sc string, st string, event_type string, pg string, action_time bigint ) PARTITIONED BY (day STRING) row format delimited fields terminated by 'u0001' STORED AS SequenceFile LOCATION 'hdfs:///user/flume/huochai-events';
3.关于外部表的一些说明
1) 一个目录一个分区:PARTITIONED BY (day STRING) 对应的是HDFS目录中的 /user/flume/huochai_evetns/day=20190723
2) 'u0001' 就是^A的unicode码。row format delimited fields terminated by 'u0001'
3) STORED AS SequenceFile。Snappy+SequenceFile Hive的一种比较流行的压缩存储组合。日志是csv类型的,因此用这种组合。
4) 建议不要用json数据格式,否则你会遇到很多问题。比如Hive找不到JsonSerDe,或者Hive能用了Spark On Hive有问题,又或者前两者都能用了,但Spark2 On Hive找不到。
如果执意要用是可以通过配置来解决的,但是配置步骤比较繁琐,这里不单独讲。
4.修复分区
此时外部表已经创建完成了,但如果你select一下这个表,会发现没有记录。
原因是外部表下新增的分区是无法自动被发现的,需要在beeline中执行下面语句。
msck repair table huochai_events;
之后再select,便能查到数据了。
需要注意的是,明天生成新的目录之后,你需要重新再执行一次这条命令。
你可以将这句话写在离线任务中。
比如在spark应用代码中加上如下一句:
sql("msck repair table huochai_events").show
注意引号中的sql语句结尾没有分号。
总结
每个实际业务中可能有不同的实践场景,数据格式也不尽相同,处理方式也有很多选择(你可能还想用hive-stream),但是目前这种处理方式应该是flume-hive的最佳实践了。
另外数据格式方面,最好使用扁平的csv类型格式的数据,hive可以处理json/数组/struct这类的数据,但并不代表它擅长处理这些。