一种安全的云存储方案设计(未完整理中)
一篇老文了,现在看看错漏颇多,提到的一些技术已经跟不上了。仅对部分内容重新做了一些修正,增加了一些机器学习的内容,然并卵。
这几年来,云产品层出不穷,但其安全性一直饱受诟病。这篇博文以数据隐私安全为核心,从用户需求着手,讨论云存储的安全实现问题。
因为设计问题较多,我将内容拆分为两篇,最终会得到一套较为安全且高效易用的云存储加密系统的完整设计,该系统具有以下特征:1 使用机器学习的技术进行图片内容标注和文本分类,最终实现图文混合检索功能;2 所有文档数据对云服务平台透明,加密解密过程在本地完成,全程保证用户数据安全;3 用户数据可以在不泄露明文和整体加密策略的前提下分享给其他用户;4 可以对云端的图片和数据在密文进行模糊查询;5 系统通过多次迭代返回,不断调整参数,优化搜索结果准确度。
系统设计总览
考虑到云服务商本身可能并不可信,同时防止黑客攻破云服务系统后数据泄露,数据明文不能静态存储于云端。系统在上传用户文件前将本地加密数据。因此用户将云端数据下载到本地时,最初得到的是密文数据。用户间进行数据分享时,直接分享云端存储的加密数据。
为实现加密数据的查询功能,系统设计了搜索操作模块。其核心是一个密文索引库。同样,出于安全考虑明文检索的操作放在本地完成。索引会在关键字加密后上传至云端,与云端索引完成合并。而在用户搜索时,系统采用密文对密文的查询,放在云端完成。系统支持模糊查询功能,搜索操作模块根据相似度排名返回加密后的相关文件信息,用户解密后选择下载。
系统检索前将对文档进行预处理,之后会使用机器学习的技术进行图片内容标注和文本分类,支持混合检索。在一些应用场景下,用户的待检索资料可能是手机拍摄的图文混合文档,本系统将使用 FastR-CNN 算法先对图片进行分割和标注,对其中的文字部分调用 OCR 接口文字识别,然后再进行图文混合检索。但是 OCR 识别的文字往往不够准确,这也就使得系统所支持的模糊查询功能更加重要。
虽然经过不同调试,系统的模糊查询结果已经较为优异,但是在密文基础上模糊查询效果远不如明文。本模型会在云端密文模糊查询的基础上,将匹配结果列表和对应文件的检索摘要下载本地,解密后进行本地的二次明文模糊查询得到最终结果。同时系统还将通过对比二次查询的差异,对首次密文模糊查询系统的参数进行反馈,其中包括削弱部分常见词根的权值。通过多次迭代学习最终达到提高模糊匹配精度的结果。
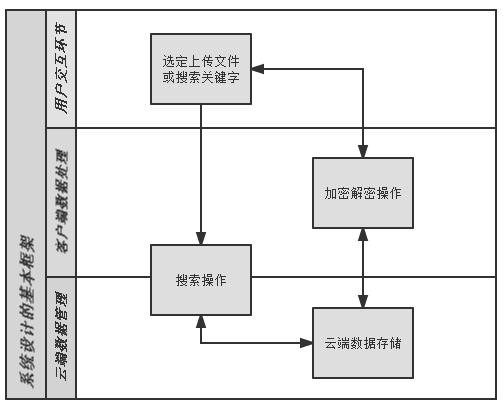
安全云存储加密管理框架设计
一种安全云存储方案设计(上)——基于二次加密的存储策略与加密图文混合检索
基于机器学习的图片标注和文本分类
一种安全云存储方案设计(上)——基于二次加密的存储策略与加密图文混合检索
密文索引上的的模糊查询
在文件上传前本地加密用户文件的云存储策略极大提升了用户数据安全性,但也丧失了大部分搜索特性。为了实现密文基础上的搜索功能,系统建立了一个索引系统。索引系统的设计兼顾数据的安全隐私和云系统的高效便捷。用户的本地客户端在加密上传文件的同时分析本地未加密的数据明文,筛选索引关键字加密后写入索引,并上传与云端索引合并。索引采用倒排结构。用户搜索下载文件时,客户端加密用户关键字,上传至云端索引系统,进行密文对密文的搜索。同时,系统通过使用 N-gram 分词技术,实现了模糊查询功能。
使用多个分析器分级检索文档信息
为了保证用户搜索时能命中欲获取文件,同时尽量减少索引数量以节约空间,系统采取了分级分析检索。为其加入不同分析器,对文档不同属性的内容使用不同的分析策略。对于文章的标题和摘要,力求完整保存原始内容,用户搜索其中包含的任意一个单词(甚至是单词的部分拼写),都能在搜索结果中找到想要的文件。但对于文章的正文,会过滤掉停用词等无实意内容,并按需要进行大小写一致化和动词时态统一等操作。对于文件的存储地址或是加密“盐”等信息,不进行分析检索操作。
模糊查询功能设计
模糊查询是指在输入不准确关键字的情况下依然能进行智能匹配。模糊的情况包括拼写不完整,如
单词 about 仅仅输入了 abou 或 bout;还包括拼写错误,如单词 search 错误拼成 saerch、serch、searlch。
模糊查询的经典算法是使用测量最短编辑距离的方法进行模糊度判断。但这需要在明文的基础上进行匹配才有意义,明文编辑距离为 1 的字符串加密后往往完全不同。
本系统使用 N-gram 分词机制进行模糊查询。N-gram 分词把字符串切分成多个连续的 N 个字母组成的子字符串,例如 abstract 的 3-gram 集合{abs,bst,str,tra,rac,act}。引入这种机制后,创建索引时将把索引再次拆分成 N-gram 后分别加密。搜索时,关键字使用同样的方法拆分后加密上传,进行多次密文对密文的匹配。
索引创建
整个索引功能基于 Lucene 实现,使用 JAVA 语言二次开发。本地创建索引的过程:首先,对上传的文件进行处理,格式化其中的文档,以供检索程序分析。创建索引库 Directory 对
象,选择适当分析器。接着,以 Directory、Analyzer 对象为参数,创建 IndexWriter 对象。然后,为每个预上传文件创建 Document 实例,并抽象格式化的文档的各类属性作为 Field 实例添加进 Document,其中包括数据的云端存储地址信息和二次加密时用到的“盐”。将 Document 实例添加进 Directory。最后启动 IndexWriter 实例,完成本地检索工作,上传云端合并索引。
Lucene 自带的分析器并不支持索引值加密。因此自建 SafeNGramAnalyzer,在分此前引入一些特殊符号,将提高最后的模糊搜索效果。如 excited 分词前将处理为 d*excited#e 再 NGram 分词。另外词性为数字、邮件地址缩写等词不进行分词处理。
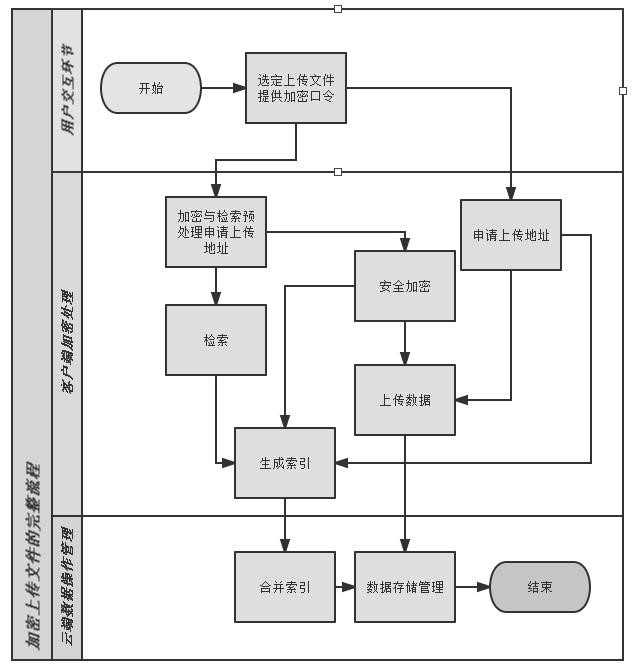
加密上传文件的完整流程
1)首先用户登陆客户端,确认上传一批文件。
2)按需分割文件为数据块,在本地进行安全加密,并向云服务器申请云端存储地址。
3)分级检索文件明文,关键字进行分词加密后作为索引值。索引对象为加密后的数据块,索引信息包含其云端存储地址和二次加密使用的“盐”。
4)上传加密后的数据和索引。
5)在云端进行索引的合并操作。
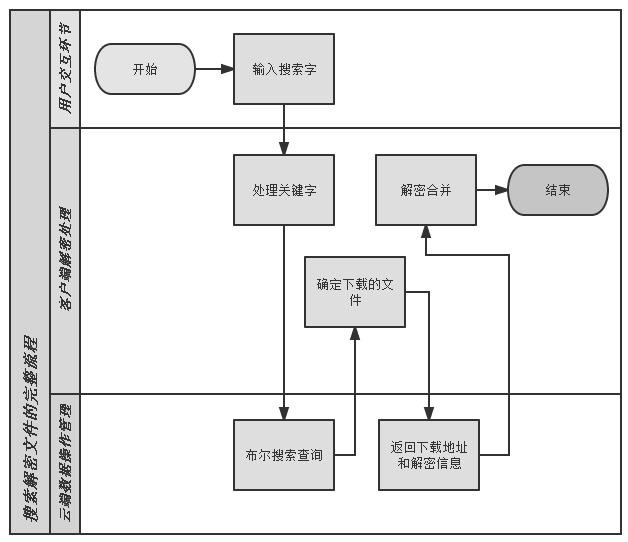
搜索解密文件的完整流程
1)首先用户在客户端输入关键字,分词加密后上传至云端,由云服务器索引进行多组密文匹配。
2)服务器依照相似度返回搜索结果,客户端解密部分索引内容,用户确认需要的文件。
3)从索引结果中获得该文件下载地址和“盐”。客户端下载密文数据。
4)用新获取的“盐”和用户的数据加密口令,从以 PBKDF2 算法为核心的密钥生成程序中导出二次加密时使用的密钥,解密下载数据,获取初次加密信息。
5)根据初次加密的信息,解密获得最终文件,并按需合并。
模糊搜索测试
系统实现了对密文索引值的模糊查询。被模糊匹配到的文件能根据相似度排序。多次测试,实验效
果理想。

测试使用拼写错误的关键字“Addriss”搜索约 200 份上传文件,获得 4 个相似匹配结果,其中三个
为包含正确拼写“address”的文档,若使用传统编辑距离算法获得的的编辑距离是 1(越小越相似),
本系统相似评分约为 0.226(越大越相似)。另外获得一个包含关键字“iAd”的结果,编辑距离为 6,
本系统相似评分 0.003,可按需过滤掉。
各种模糊匹配算法比较
| 算法名称 | 传统编辑距离算法 | 加入通配符的改进编辑距离算法 | 本 系 统 采 用 的N-gram 改进算法 |
|---|---|---|---|
| 密文匹配支持 | 不支持 | 支持 | 支持 |
| 匹配复杂度 | 最低 | 一般 | 一般 |
| 单位关键字所需索引数量 | (NULL) | 依设定的相似度阈值增加,超过阈值结果无法获取 | 依据期望的搜索结果和排序的准确度而增加 |
| 单个索引利用率 | (NULL) | 较低 | 较高 |
| 模糊匹配体验 | 最好 | 较差 | 一般 |
排序参数的迭代学习与伪相关反馈
通过合理的参数设置,特别是对评分排序参数的权值的设置,系统的模糊查询体验较为良好,但是在密文基础上模糊查询效果远不如基于明文的模糊搜索。由上表也可以看出,如果可以拿到索引明文,直接计算编辑适量距离的方法以及它的一系列改进衍生算法能够又好又快地实现模糊匹配。由此,本模型会在云端密文模糊查询的基础上,将匹配结果列表和对应文件的检索摘要下载本地,解密后进行本地的二次明文模糊查询得到最终结果。由于二次明文检索的仅仅是需要重新检索的摘要信息(Document 对象的部分 Field 域,非文档本身),下载的数据量是可控的,且算法效率较高。二次建索引以及搜索的时间也是几乎可以忽略的。
同时系统还将通过对比二次查询的差异,对首次密文模糊查询系统的参数进行反馈。不同于用户对结果进行标注的反馈方式,本系统的反馈方式是自动完成的,直接比较两次搜索结果的差异。在第一次模糊查询中得分较高,而明文查询时排名靠后的文档,所包含的第一次索引关键字将被降权。通过多次迭代学习最终达到提高模糊匹配精度的结果。
转载请注明 作者 Arthur_Qin(禾众) 及文章地址 http://www.cnblogs.com/arthurqin/p/6307153.html