对 t1 进行调优应该要找到热点 ( 即最耗时的代码片段 ),再看看是否能够提高热点代码的效率。
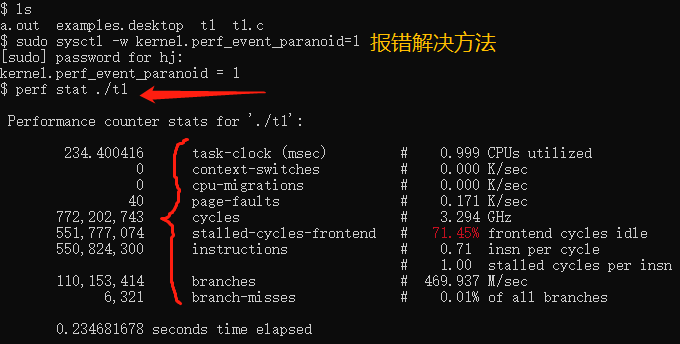
缺省情况下,除了 task-clock-msecs 之外,perf stat 还给出了其他几个最常用的统计信息
Task-clock-msecs:CPU 利用率,该值高,说明程序的多数时间花费在 CPU 计算上而非 IO。
Context-switches:进程切换次数,记录了程序运行过程中发生了多少次进程切换,频繁的进程切换是应该避免的
Cache-misses:程序运行过程中总体的 cache 利用情况,如果该值过高,说明程序的 cache 利用不好
CPU-migrations:表示进程 t1 运行过程中发生了多少次 CPU 迁移,即被调度器从一个 CPU 转移到另外一个 CPU 上运行。
Cycles:处理器时钟,一条机器指令可能需要多个 cycles,
stalled-cycles-frontend:每个周期递增RAT向RS发出的Uop数量。 设置Cmask = 1,Inv = 1,Any = 1,以计算该内核的停顿周期。(与微架构相关
Instructions: 机器指令数目
branches:Counts when the last uop of a branch instruction retires.计算分支指令的最后一次退出时的计数。
branch-misses:Counts when the last uop of a branch instruction retires which corrected misprediction of the branch prediction hardware at execution time:计算分支指令的最后一次退出时的计数,在该时间内在执行时纠正了分支预测硬件的错误预测。
IPC:是 Instructions/Cycles 的比值,该值越大越好,说明程序充分利用了处理器的特性
Cache-references: cache 命中的次数
**Cache-misses: **cache 失效的次数。
通过指定 -e 选项,您可以改变 perf stat 的缺省事件。假如您已经有很多的调优经验,可能会使用 -e 选项来查看您所感兴趣的特殊的事件。
举例:perf stat -e cycles,instructions,L1-dcache-loads,L1-dcache-load-misses,LLC-loads,LLC-load-misses,dTLB-loads,dTLB-load-misses -p 316 sleep 10