初期只出画的图,等有时间了可能会补全设计说明。
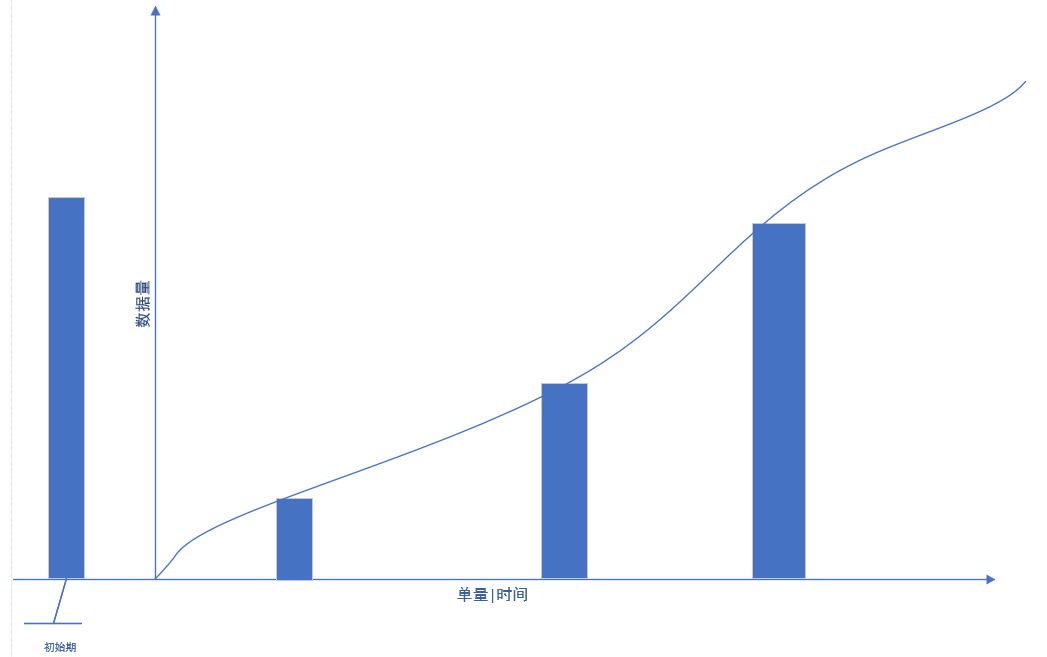
1.核心问题: 数据会随着单量与完结时间两个变量的增长而增长。
2. 各个阶段的不同方案 图上是加原始的方式一共5种,第六种最终方案并未画出。是对最后两总的结合妥协。等我有时间了写个详细的。前三种只是适用于业务探索期到成长期之间从缩减数据量的角度出发的方案,后两种是为高可用与多数据源和无限拓展的角度出发的。是成长期到成熟期阶段。 不同阶段适用于不通的方案,成本永远是需要对应的收益做回报的。
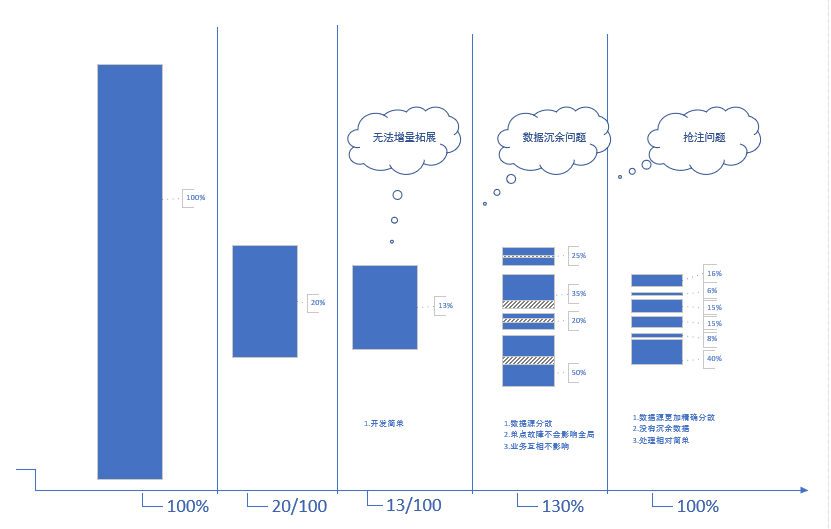
图片可以右键查看看原图放大
方案一: 02-1图 第三节
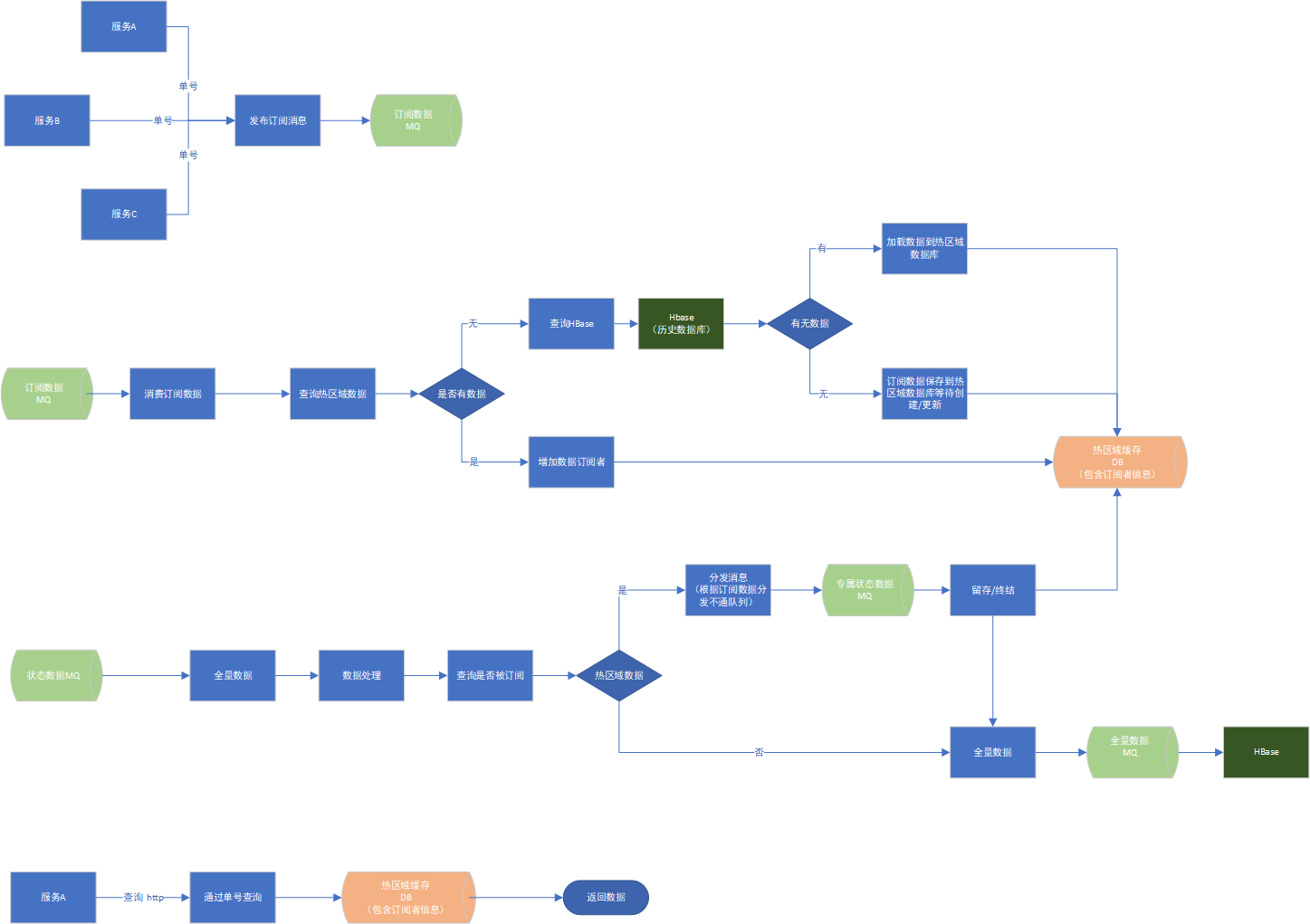
方案二:02-1图 第四节
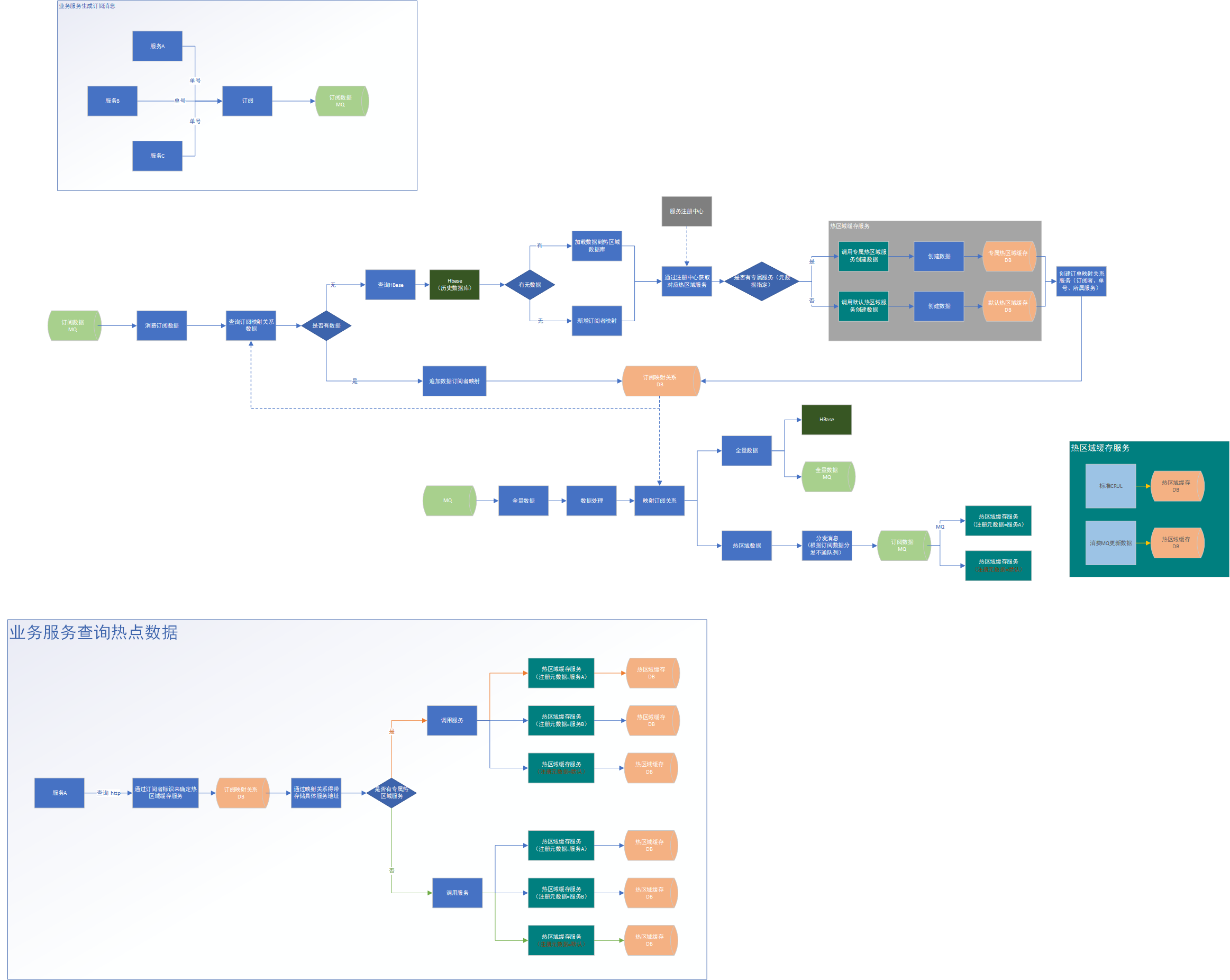
方案三:02-1图 第五节
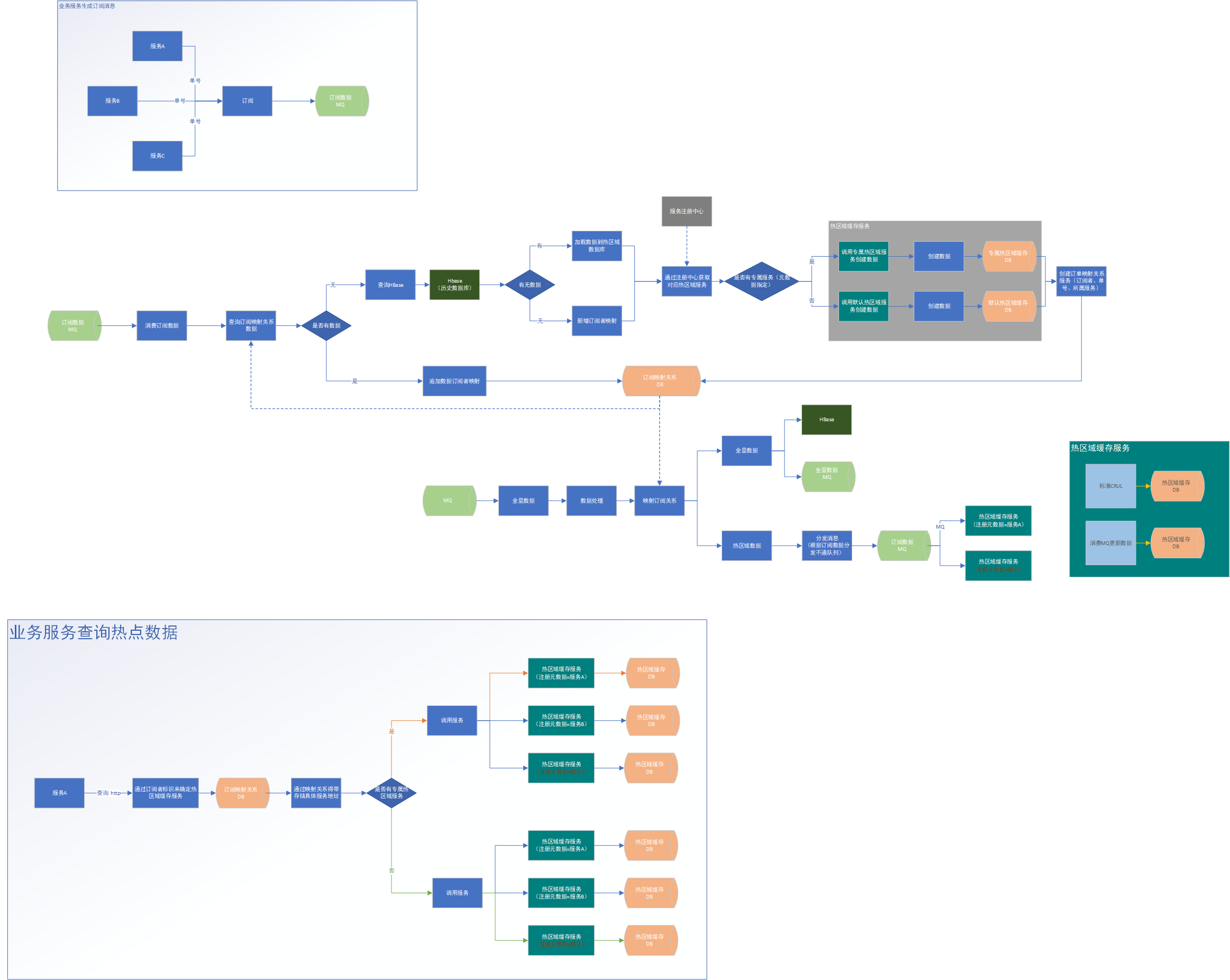
最终数据流程图:
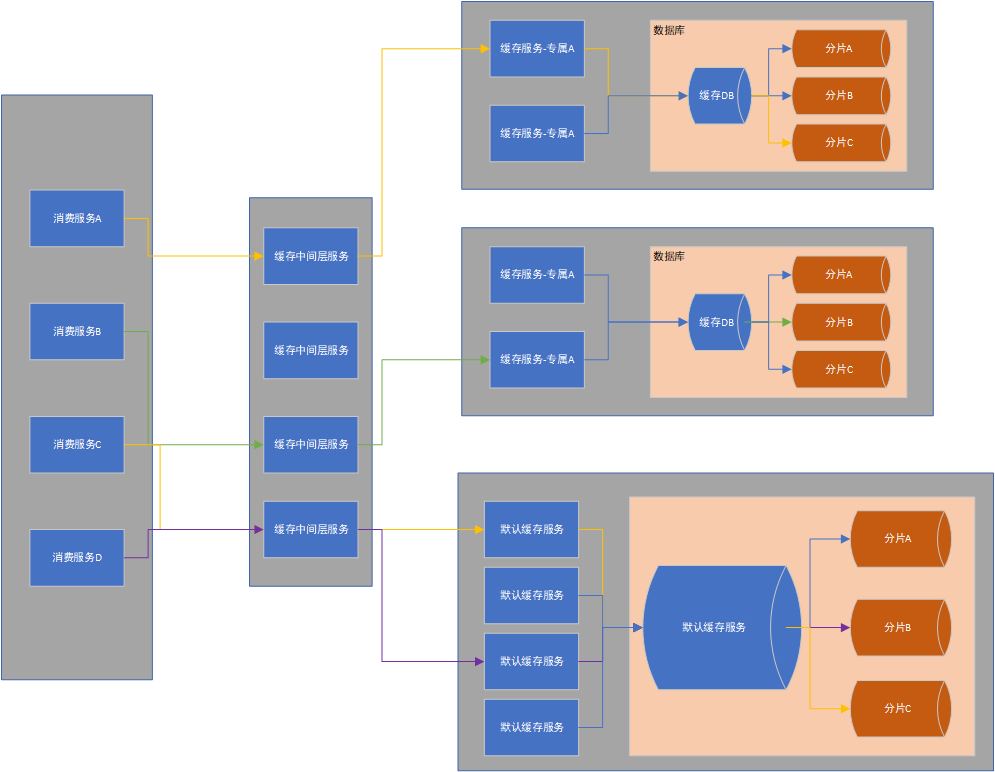
除去默认缓存服务不可随意拓展其他的都可以无限拓展,其实也可以继续优化 默认缓存也是可以无限拓展的。
PS
总之,你会发现感觉特别像是在数据库层面的分库分表又抽象出一个程序服务上的分库分表。之所以这样是因为分配给DB 的资源是有限的。在DB方便投入不合算的情况下的。如果你的DB服务器性能相当高。在缩减数据量上就可以解决问题,不需要后续的抽象程序了。
其次,你会疑惑怎么并不智能啊?自动感知热点数据如何做?这个需要大数据技术的支持,收集各个服务的性能指标与数据指标实时计算出来。然后通过一定条件触发加载。归根还是需要给出条件后才能加载到缓存区域,只是一个是通知类主动触发另外一个是计算后被动触发。一个有感一个无感。在没有想过条件下,不进行问题扩大化是一个原则。优先满足“当下业务”场景需要才是最正确的。