1.爬虫的定义
网络爬虫(又称网络蜘蛛)模拟客户端发送网络请求,接收请求响应,自动的进行抓取网络数据的程度。
注意: 网络爬虫在进行抓取数据的时候并不能进行辨别信息真伪(比如某直播平台直播房间显示在线观看人数100w,在这个数量上会有一些是运营商加上去的数据,比如真正在线人数80w运营商再加上去20w,网络爬虫抓取的就是100w和用户在浏览器中看到的一样)网络爬虫仅仅是可以爬到用户在浏览器可以看到的。
2.爬虫的目的
1.建立网站 进行数据展示 (某新闻网)
某新闻网,并不是做新闻的公司,用户点击新闻会跳转到其他真正的新闻网站,那么该网站就是通过抓取其他网站上的信息进行在自己的网站上进行展示。
2.建立音乐播放器(主要为了推送广告)
如果我们后续想要做一个和网易云音乐类似的音乐网站会先在免费的网站上(如:You Tube等)通过抓取音乐信息或者视频信息(只提取音乐部分)放在自己的播放器上进行播放,然后通过投放广告赚取商业利润。
3.进行数据分析 (为大数据和人工智能做准备)
通过在网上抓取海量数据,进行数据分析,挖掘出想得到的特定的目的。
3.爬虫的分类
网站排名影响因素:PageRank算法、点击量、相关度、引用量(像文献的影响因子)
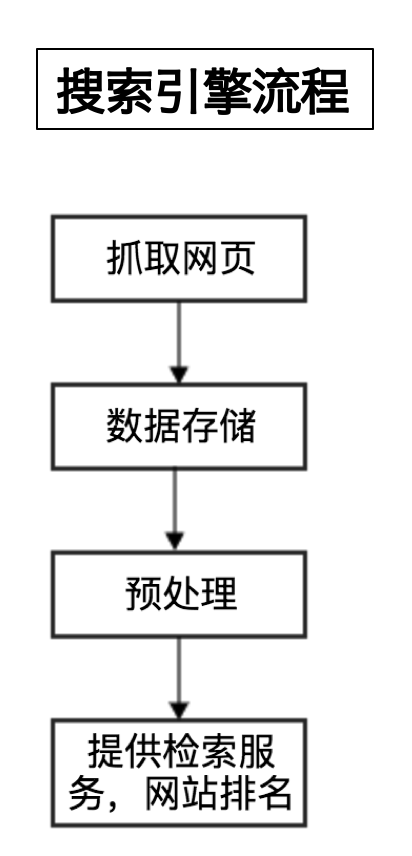
通用爬虫(流程)
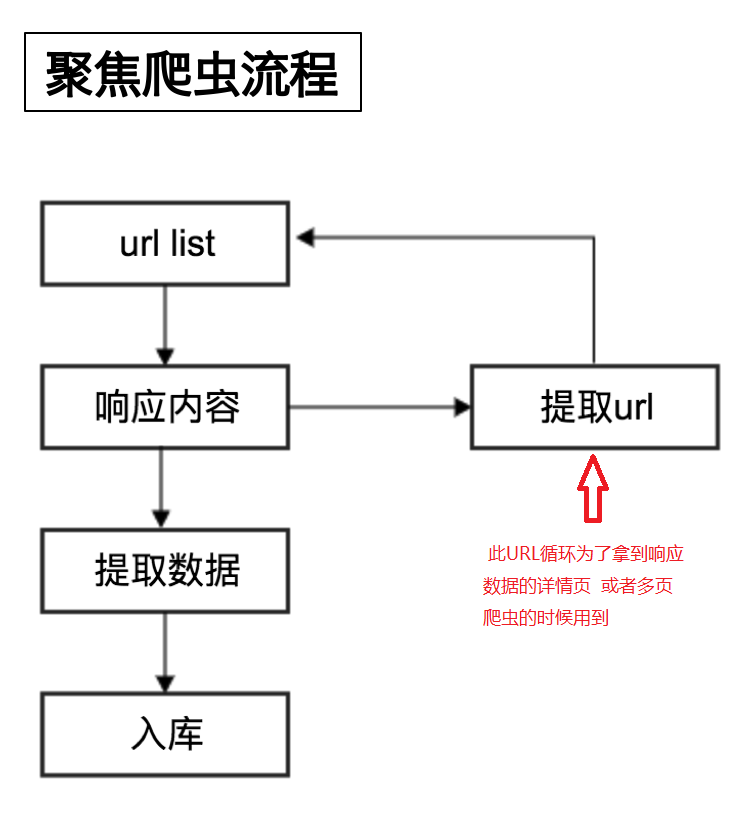
聚焦爬虫(流程)
URL循环为了拿到响应数据的详情页 或者多页爬虫的时候
4.爬虫的内容
URL地址请求的响应 (不包括HTML、 js、 css、 图片等)
5.Robots协议
Robots协议:网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取,但它仅仅是道德层面上的约束。
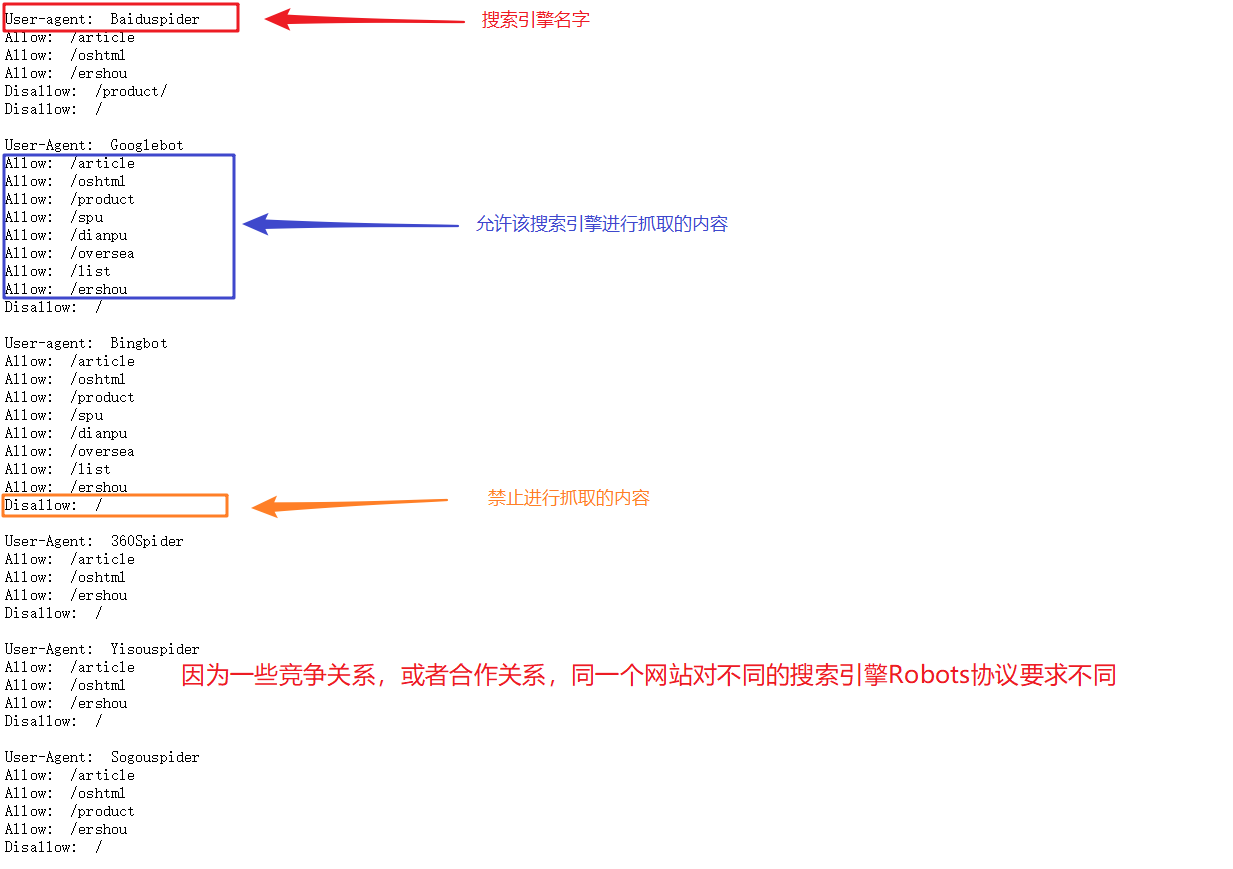
上图是一个网站的robots协议,道德层面的协议,同一个网站对不同的搜索引擎具有不同的协议要求(竞争力、准备进入相关市场)。