一、导入mysql数据前期设置
1.建库和表统一编码设置为UTF8,根据数据中的编码来修改(也可以将数据全部转换为utf-8格式,小文件可用notepad来修改编码,大文件可用 LogViewPro 来修改编码)

2.对MySql数据库进行优化配置
my.ini优化配置: [mysql] default-character-set=utf8 [mysqld] port=3306 basedir=F:/phpstudy_pro/Extensions/MySQL5.7.26/ datadir=F:/phpstudy_pro/Extensions/MySQL5.7.26/data/ character-set-server=utf8 #默认的数据库编码 default-storage-engine=MyIsam #数据库引擎,myisam适合于查询 max_connections=1000 #客户端和服务器最大连接数,默认为1000 collation-server=utf8_unicode_ci init_connect='SET NAMES utf8' innodb_buffer_pool_size=4096M #一般设置 buffer pool 大小为总内存的 3/4 至 4/5 innodb_flush_log_at_trx_commit=2 #当设置为2,该模式速度较快,也比0安全,只有在操作系统崩溃或者系统断电的情况下,上一秒钟所有事务数据才可能丢失。 innodb_lock_wait_timeout=120 #默认参数:innodb_lock_wait_timeout设置锁等待的时间是120s,一旦数据库锁超过这个时间就会报错。 innodb_log_buffer_size=16M #建议取值16M-64MB,自己内存为8G innodb_log_file_size=256M #一般取256M可以兼顾性能和recovery的速度,不可取大也不可取小 interactive_timeout=120 #服务器关闭交互式连接前等待活动的秒数 join_buffer_size=16M #联合查询操作所能使用的缓冲区大小,如果有100个线程连接,则占用为16M*100 key_buffer_size=512M #索引缓冲区,一般情况下对于内存在 4GB 左右的服务器该参数可设置为256M 或384M log_error_verbosity=2 #错误日志记录内容 max_allowed_packet=128M #限制Server接受的数据包大小,默认是128M max_heap_table_size=64M #设置默认值 myisam_max_sort_file_size=64G ## mysql重建索引时允许使用的临时文件最大大小,默认值即可 myisam_sort_buffer_size=150M #MyISAM表发生变化时重新排序所需的缓冲 read_buffer_size=512kb #缓存连续扫描的块,这个缓存是跨存储引擎的,不只是MyISAM表,8G内存,建议是512KB read_rnd_buffer_size=4M #MySql的随机读缓冲区大小建议末日使者 server_id=1 skip-external-locking=on #跳过外部锁定 sort_buffer_size=256kb #排序缓冲 table_open_cache=3000 thread_cache_size=16 tmp_table_size=64M wait_timeout=120 secure-file-priv='' #可在任意目录下导入 log-error="F:/phpstudy_pro/Extensions/MySQL5.7.26/data" [client] port=3306 default-character-set=utf8
二、各种数据导入mysql方法
导入的数据类型有:.sql数据,txt文本数据,cvs(xls)数据,以及access和mssql数据格式的数据
1.txt文本格式数据导入
(1).txt体积不超过400M,超过的一律进行将其分割等分
(2)、合并txt文件,针对多个小文件的txt
合并txt文件的命令:
type *.txt > all.txt(windows)
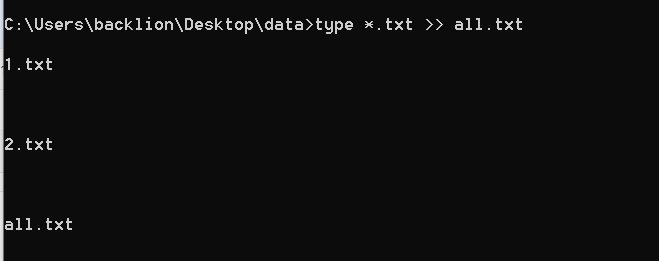
cat * > 1.txt(linux)
(3)、txt文件(使用tab间隔分割,回车换行)命令快速导入方式:
mysql -u root -p use test; load data infile 'J:/data/weibo/weibo/weibo_1.txt' into table weibo_info1 FIELDS TERMINATED BY ' ' lines terminated by ' ' (tel,uid);
注意:这里导入的txt文件路径为相对物理路径, 表示字段之间的分割符号为tab(空格),
表示在windows系统下的数据的每行的换行符号
(4)、txt文件(使用----间隔分割,回车换行)命令快速导入方式:
load data infile 'E:/test.txt' into table test FIELDS TERMINATED BY '----' lines terminated by ' ' (tel,qq);
(5)、txt文件(使用,字符间隔分割,回车换行)命令快速导入方式:
load data infile 'E:/test.txt' into table test FIELDS TERMINATED BY ',' lines terminated by ' ' (tel,qq);
(6)、txt文本字段中含有双引号字符的字段,会导致意外终止,这里使用enclosed by命令来去掉双引号
load data infile 'E:/test.txt' into table test FIELDS TERMINATED BY ',' enclosed by '"' lines terminated by ' ' (tel,qq);
(7)load data infile导入参数说明
fields terminated by ',' #表示字段数据之间用逗号分隔。 fields terminated by ' ' #表示每行数据之间的分隔符为换行符号(linux) lines terminated by ' ' #表示每行数据之间的分隔符为换行符号(windows) escaped by '' #表示对字段值中含有转义字符的进行删除 enclosed by '"' #表示去掉字段值中的双引号 (tel,qq) #表对应的字段名称,这个需要和test.txt文件里面的数据字段名称对应
(8)、小txt文件(非tab的规律间隔符),可以使用操作简单的Navicat导入数据
需要注意分割符合以及目标栏目中的数据对应导入的数据字段

(9)导入多个txt文件到mysql
想要批量导入txt文件,可以将通过批处理文件执行多条导入语句完成。
制作sql语句文件,可采用多种编程语言获取要导入的txt文件名称制成sql命令。
这里采用python完成,建立python文件create_sql.py,示例代码:(下面数据格式为----为间隔的数据)
import glob writeFile = open('C:/Users/backlion/Desktop/data/user_sql.txt','w') writeFile.write('use test; ') for filename in glob.glob(r'C:/Users/backlion/Desktop/data/*.txt'): writeFile.write('load data local infile '+'"'+filename.replace('\','/')+'"'+' into table user fields terminated by' + '"' + '----' + '"' + ' lines terminated by' + '"' + r' ' + '"' + '; ') writeFile.close()
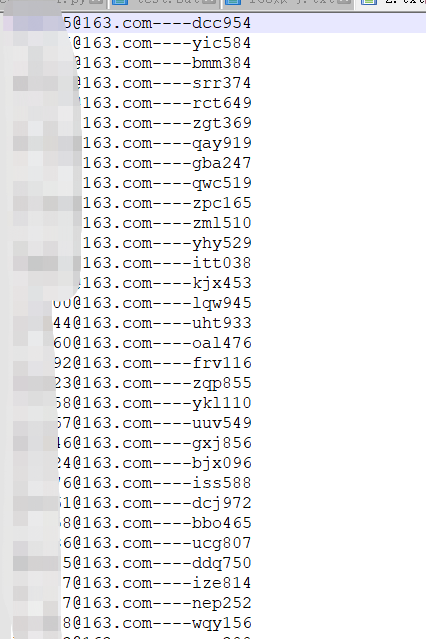
这样就将data文件夹下的所有要导入的txt文件名称制作成sql语句放在user_sql.txt中,内容大致如下:

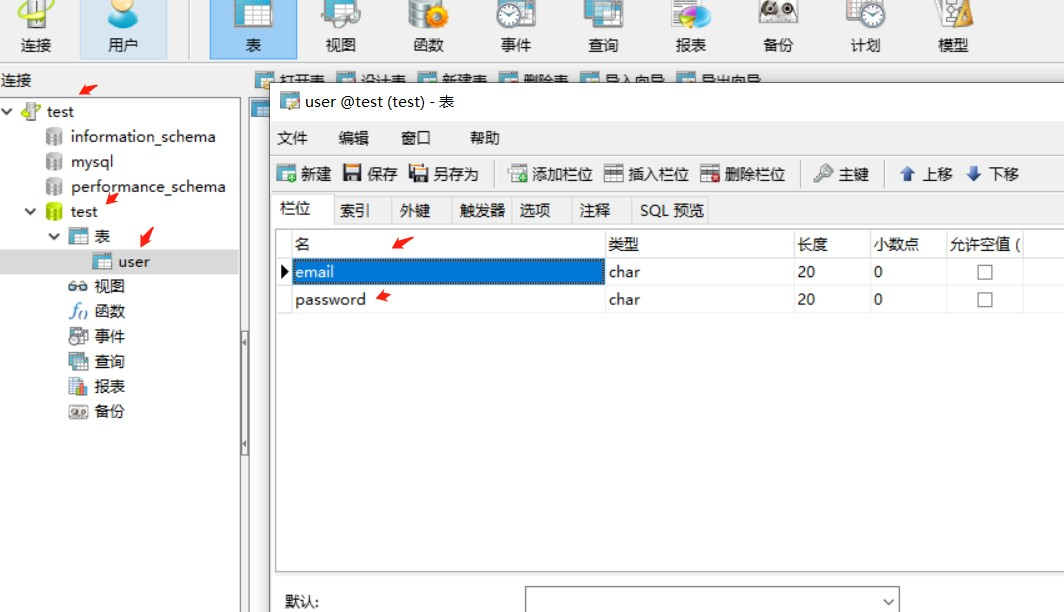
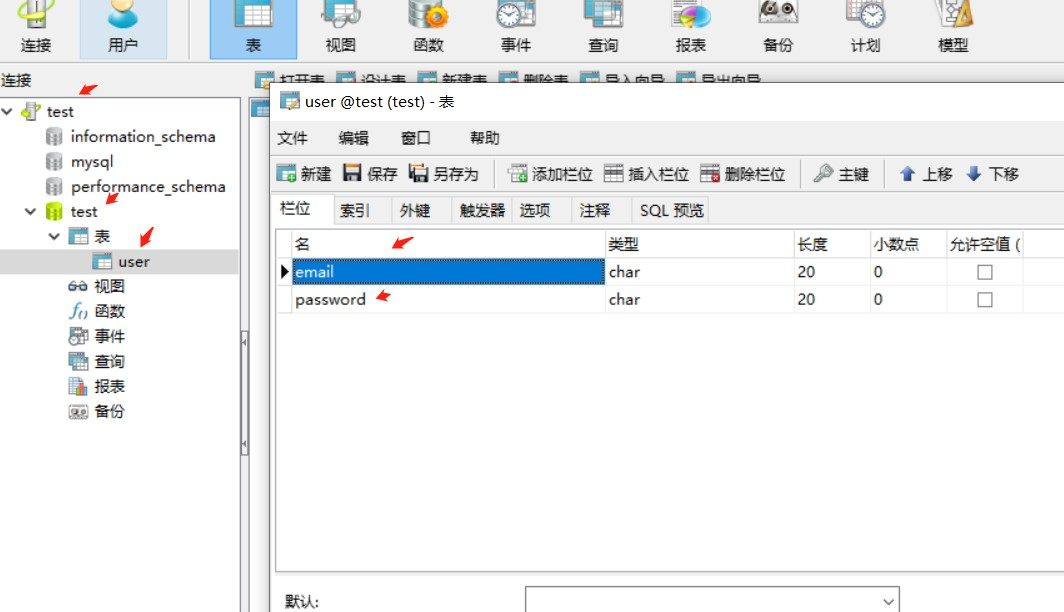
创建数据库为test,表名为user,字段名称为email和password。
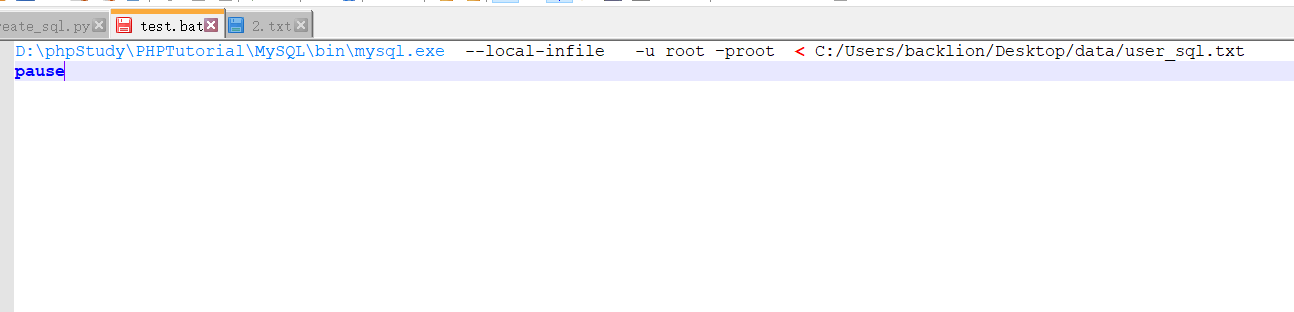
制作.bat批处理文件执行(1)生成的sql命令文件
D:phpStudyPHPTutorialMySQLinmysql.exe --local-infile -u root –proot < C:/Users/backlion/Desktop/data/user_sql.txt
pause
2、csv文件导入到mysql
(1).单个cvs导入mysql,快速命令
mysql -u root -p use test; load data local infile "C:/Users/backlion/Desktop/data/use1.csv" into table user fields terminated by"," lines terminated by" " (email,password);
(2)、多个cvs批量导入到mysql
想要批量导入txt文件,可以将通过批处理文件执行多条导入语句完成。
csv文件以','逗号作为分割符,需要用双引号或者单引号括起来.
制作sql语句文件,可采用多种编程语言获取要导入的txt文件名称制成sql命令。
这里采用python完成,建立python文件create_sql.py,示例代码:(下面数据格式csv文件)
import glob writeFile = open('C:/Users/backlion/Desktop/data/user_sql.txt','w') writeFile.write('use test; ') for filename in glob.glob(r'C:/Users/backlion/Desktop/data/*.csv'): writeFile.write('load data local infile '+'"'+filename.replace('\','/')+'"'+' into table user fields terminated by' + '"' + ',' + '"' + ' lines terminated by' + '"' + r' ' + '"' + '; ') writeFile.close()
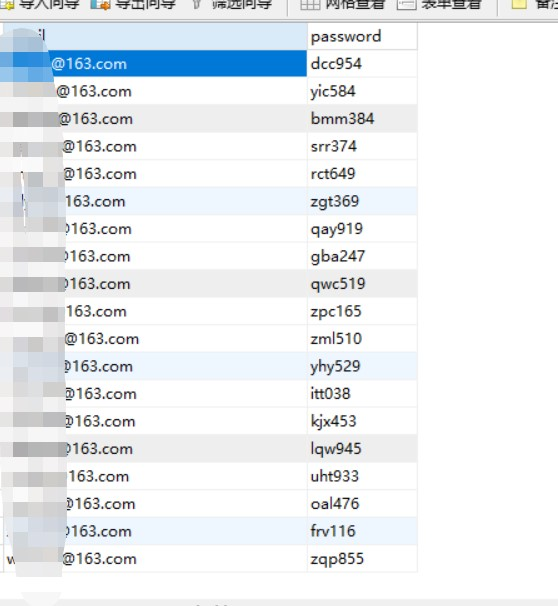
这样就将data文件夹下的所有要导入的txt文件名称制作成sql语句放在user_sql.txt中,内容大致如下:
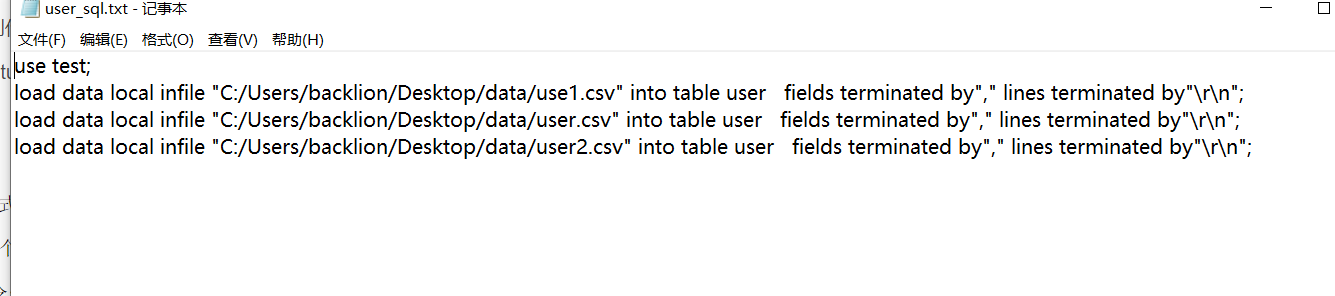
创建数据库为test,表名为user,字段名称为email和password
制作.bat批处理文件执行(1)生成的sql命令文件
D:phpStudyPHPTutorialMySQLinmysql.exe --local-infile -u root –proot < C:/Users/backlion/Desktop/data/user_sql.txt
pause
(3)多个csv文件合并
copy *.CSV all.csv
(3)、通过navicat导入cvs格式文件
2.sql格式导入mysql
(1)、单个sql格式的文件导入,不用考虑编码问题,入库后直接使用navicat编辑数据库属性转UTF8编码即可,然后再创建索引
使用命令:

mysql -u root -p
use test;
source D: est.sql;
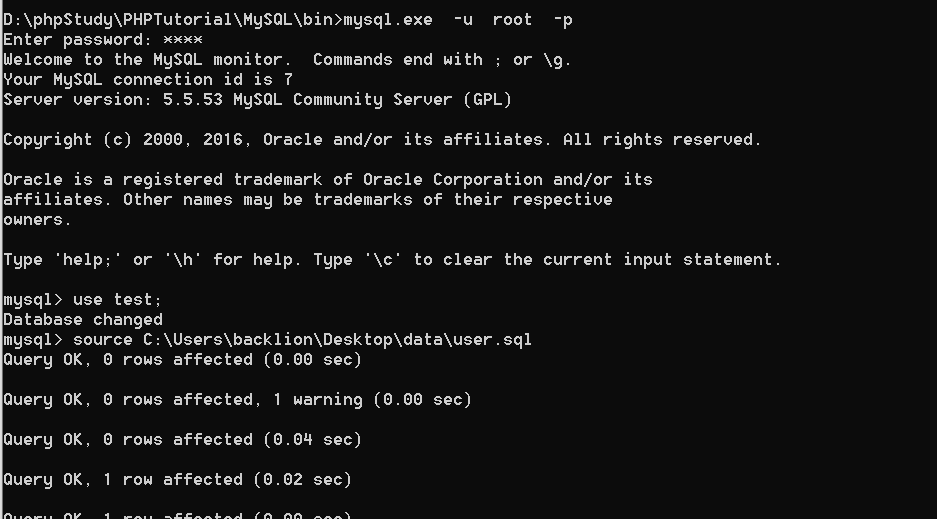
(2)、批量导入多个sql文件新建一个all.sql:vim all.sql
在里面写入:
source 1.sql source 2.sql ...... source 53.sql source 54.sql
然后执行:
mysql> source all.sql
(3)、多个sql文件合并
copy *.sql all.sql
(4)、通过navicat导入sql格式文件
三、导入技巧
1.统计MYSQL数据重复数量
mysql>select email, count(email) as count from user group by email having mysql>count(email) > 1;

或者
SELECT * FROM user WHERE email IN (SELECT email FROM user GROUP BY email HAVING COUNT(email ) > 1);

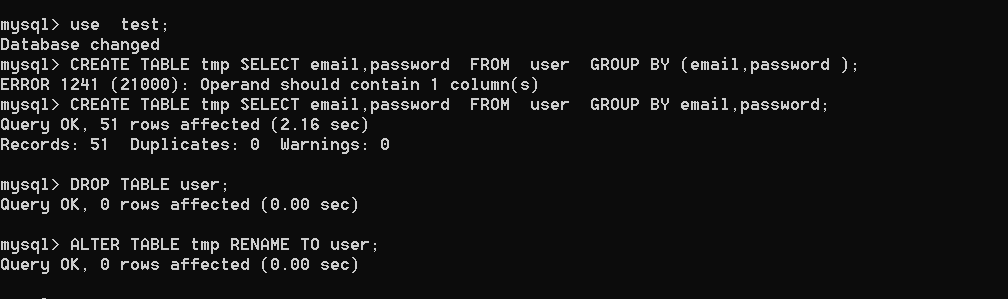
2、数据去重
mysql> CREATE TABLE tmp SELECT email,password FROM user GROUP BY email,password ;
或者
mysql> CREATE TABLE tmp SELECT email FROM user GROUP BY email; mysql> DROP TABLE user; mysql> ALTER TABLE tmp RENAME TO user;
或者
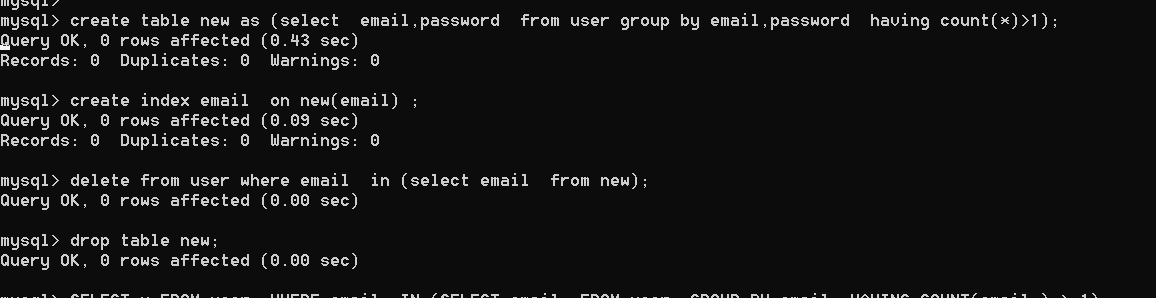
1)选择已选择的字段或者主键值重复项中的记录
create table new as (select email,password from user group by email,password having count(*)>1);
2)创建索引(仅需在第一次时执行)
create index email on new(email) ;
3)删除重复项中字段或者主键值的记录
delete from user where email in (select email from new);
4)删除临时表
drop table new;
3、添加索引,并查询优化
给常用查询字段添加索引,模糊类用BTREE存储类型,精确类用HASH存储类型。推荐使用Navicat 选择表打开表讯息,选择DDL选项卡,可以清楚看到该表的sql,有无索引一目了然,然后右击数据库名选择它的console功能,来快速添加索引。

4、导入特殊字符如表情或者每字符四个字节支持补充字符,可将数据库和表的字符集设为utf8mb4
5、xls和cvs等excle格式的文件,建议直接使用navicat编辑数据库属性转UTF8编码即可,然后再创建索引
6、先通过navicat创建数据库和表和字段等数据库结构后,然后创建索引,最后导入数据(这个是针对数据量很大的数据,如果先导入很大的数据,最后再来创建索引,会直接卡死,并且卡很久)
7.mssql导入到mysql数据库中,通过navicat的导入功能中的mssql数据库源导入