学习过程:
第二章信息的表示和处理
一、数字表示
1、 无符号数:编码基于传统的二进制表示法表示大于或等于零的数字。
2、 补码:编码是表示有符号整数的最常见方法,可以是正或者是负的数字。
3、 浮点数:编码是表示实数的科学计数法的以二位基数的版本。
- 三种数字:无符号数、有符号数(2进制补码)、浮点数
- 溢出:计算机的表示法是用有限数量的位来对一个数字编码,当结果太大以至不能表示时,会溢出
- 整数运算:编码的数值范围较小,精确;浮点运算:数值范围较大,近似,不可结合
§1 信息存储
- 最小的可寻址的存储器单位:字节(8位)
- 虚拟存储器、地址、虚拟地址空间(p22)
进制转换
十六进制表示法
十六进制中一个字节的值域为00H~FFH
用0x或0X开头表示十六进制数字常量
快捷算法:要表示的数字常量为x=2^n,n=i+4j,且0≤i≤3时,开头的十六进制数字为1(i=0)、2(i=1)、4(i=2)、8(i=3),后面跟随着j个十六进制的0。这里的j是代表着每四位二进制位对应的十六进制位,而i的范围是因为十六进制中每一位的范围是0-F
二、字
字长:指明整数和指针数据的标称大小。决定虚拟地址空间的最大大小
字长为w,虚拟地址范围为0~2^w-1,程序最多访问2^w个字节,cpu一次处理w位数据
三、数据大小
在不同字长的计算机中,相同的数据类型所占用的字节数不同
在64位机上生成32位代码:gcc -m32
32位与64位机器中的数据大小
|
C声明 |
32位机器 |
64位机器 |
|
char |
1 |
1 |
|
short int |
2 |
2 |
|
int |
4 |
4 |
|
long int |
4 |
8 |
|
long long int |
8 |
8 |
|
char * |
4 |
8 |
|
float |
4 |
4 |
|
double |
8 |
8 |
四、寻址和字节顺序
多字节对象倍存储为连续的字节序列,对象的地址为所使用字节中最小的地址
字节顺序是网络编程的基础
1.两个通用规则(w为整数,位表示为[Xw-1,Xw-2,……,X1,X0],其中Xw-1是最高有效位,X0是最低有效位):
- 小端法:最低有效字节在最前面(大多数Intel兼容机)
- 大端法:最高有效字节在最前面(大多数IBM和Sun Microsystems机器)
- 一些新的微处理器使用双端法
字节内部的顺序不变
反汇编器:确定可执行程序文件所表示的指令序列的工具;将可执行程序文件转换回可读性更好的ASCII码形式的程度
2.强制类型转换

表示字符串
c语言中字符串被编码成为一个以null(值为0)字符结尾的字符数组
命令man ascii:得到ASCII字符码表
表示代码
二进制代码在不同的操作系统上有不同的编码规则。所以二进制代码是不兼容的
布尔代数
1.最简单布尔代数:与& 或| 非~ 异或^(结果为0或1)
2.扩展的布尔运算:位向量的运算(结果仍是位向量)
位向量的应用:表示有限集合,对集合编码
位级运算
1.将位向量按位进行逻辑运算,结果仍是位向量
2.掩码运算
掩码:用来选择性的屏蔽信号,是一个位模式,表示从一个字中选出的位的集合。
用位向量给集合编码,通过指定掩码来有选择的屏蔽或者不屏蔽一些信号,某一位位置上为1时,表明信号i是有效的;0表示该信号被屏蔽。这个掩码就表示有效信号的集合。
0xFF:屏蔽除最低有效字节之外的所有字节。
~0:生成全1的掩码
逻辑运算
1.逻辑运算符:与&& 或|| 非!
2.计算方法:所有非零参数都代表TRUE,0参数代表FALSE。1代表TRUE,0代表FALSE
- 只有当参数被限制为0或1时,逻辑运算才与按位运算有相同的行为。
- 如果对第一个参数求值就能确定表达式的结果,逻辑运算符就不会对后面的参数求值。
移位运算
C语言还提供了一组移位运算,以便向左或向右移动位模式。移位运算可以从左向右结合的,所以x<<j<<k等价于(x<<j)<<k。
一般而言,机器支持两种形式的右移:逻辑右移和算数右移。逻辑右移在最左端补k个0,算数右移在最左端补k各最高有效位的值。
C语言标准没有明确定义应该使用哪种类型的右移。对于无符号数据,右移必须是逻辑的。对于有符号数据,算数的或者逻辑的右移都可以。
C语言中有符号数和无符号数的转换
位向量不变,只是上下文的读取方式不同,所以根据不同的读取规则,最终的读取结果也不同。这就是所谓的信息就是位+上下文。
注:c语言中要创建一个无符号常量,必须加上后缀字符'U'或者'u'。
转换的原则是底层的位表示保持不变。
怎么让负数等于正数
将有符号负数转化为无符号正数,变的只是上下文的读取方式,但二进制位级表示是一样的。
零扩展和符号扩展
零扩展:将一个无符号数转换为一个更大的数据类型,我们只需要简单地在开头添加0。
号扩展:将一个补码数字转换为一个更大的数据类型,规则是在表示中添加最高有效位的值的副本。
无符号数与有符号数容易造成的错误
例:以下一段代码
float sum_elements(float a[],unsigned length){
int i;
float result=0;
for(i=0;i<=length-1;i++)
result+=a[i];
return result;
}
因为参数length是无符号的,计算0-1将进行无符号运算,这等价于模数加法。结果得到UMax。<=比较进行同样使用无符号数比较,而因为任何数都是小于或者等于UMax的,所以这个比较总是为真!因此,代码将试图访问数组a的非法元素。
改正方法:1.将length声明为int类型。
2.或将for循环的测试条件改为i<length。
整数溢出
整数溢出:指完整的整数结果不能放到数据类型限制的字长中去。
避免整数溢出:当两个整数进行运算时,其结果用更大的数据类型进行存储。比如两个int类型的整数相乘的结果用long long数据类型的变量来存储。
关于整数运算的思考
计算机执行的"整数"运算实际上是一种模运算形式。表示数字的有限字长限制了可能的值的取值范围,结果运算可能溢出。
补码提供了一种既能表示负数也能表示正数的灵活方法,同时使用了与执行无符号算数相同的位级实现,这些运算包括加减乘除,无论是以无符号形式还是以补码形式表示的,都有完全一样或者非常类似的位级行为。
浮点数
浮点表示对形如V=x*的有理数进行编码。它对涉及非常大的数字(| V|>>0)、非常接近于0(|V|<<1)的数字,以及更普遍地作为实数运算的近似值的计算,是很有用的。
浮点数的运算及执行标准:IEEE标准754。
浮点数运算的不精确性和舍入
当一个数字不能精确地表示为IEEE标准754时,就必须向上或者向下调整,此时出现舍入。
IEEE浮点标准,float和double类型p70
单精度浮点格式(float)中,s、exp和frac字段分别为1位、k=8位和n=23位,得到一个32位的表示。
双精度浮点格式(double)中,s、exp和frac字段分别为1位、k=11位和n=52位,得到一个64位的表示。
整数与浮点数转换规则
当在int、float和double格式之间进行强制类型转换时,程序改变数值和位模式的原则如下(假设int是32位的):
-
从int转换成float,数字不会溢出,但是可能被舍入。
-
从int或float转换成double,因为double有更大的范围(也就是可表示值的范围),也有更高的精度(也就是有效位数),所以能够保留精确的数值。
-
从float或者double转换为int,值将会向零舍入。
练习:
p24进制转换代码
十进制转十六进制
源文件代码

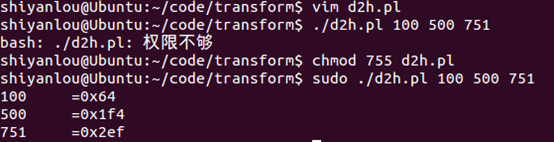
十六进制转十进制
源文件代码


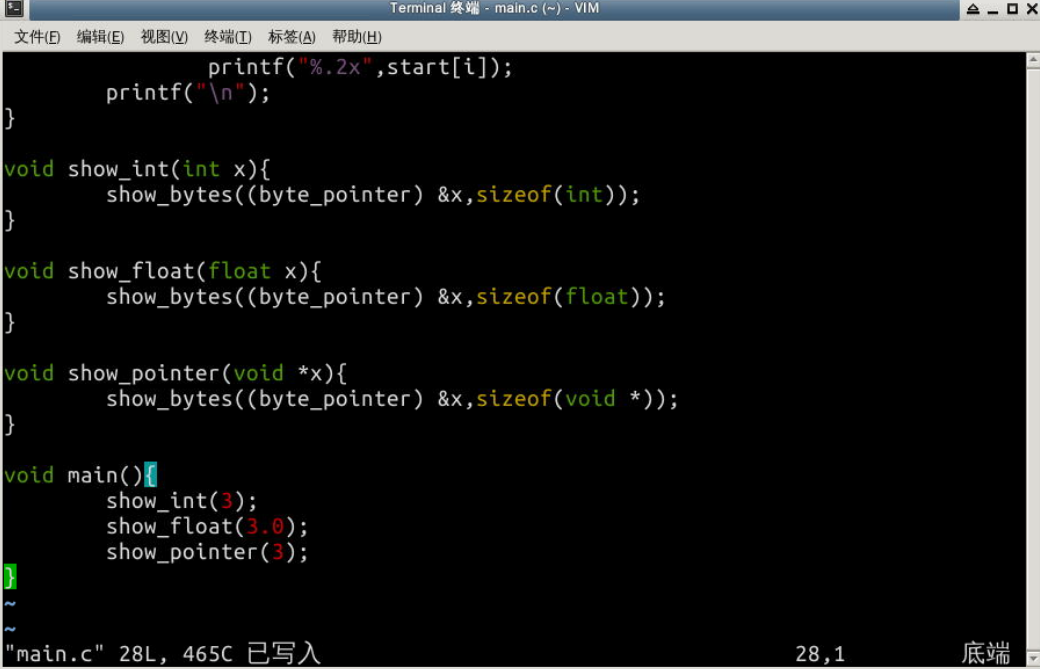
p44 代码放到一个main函数中
源文件代码


遇到的问题:
编译书上代码时出错了,但是照着书上检查了,一行一行的,没什么错误,试着把最后一行注释掉了,就行了,不太懂