爬虫 大网站获取部分网页信息
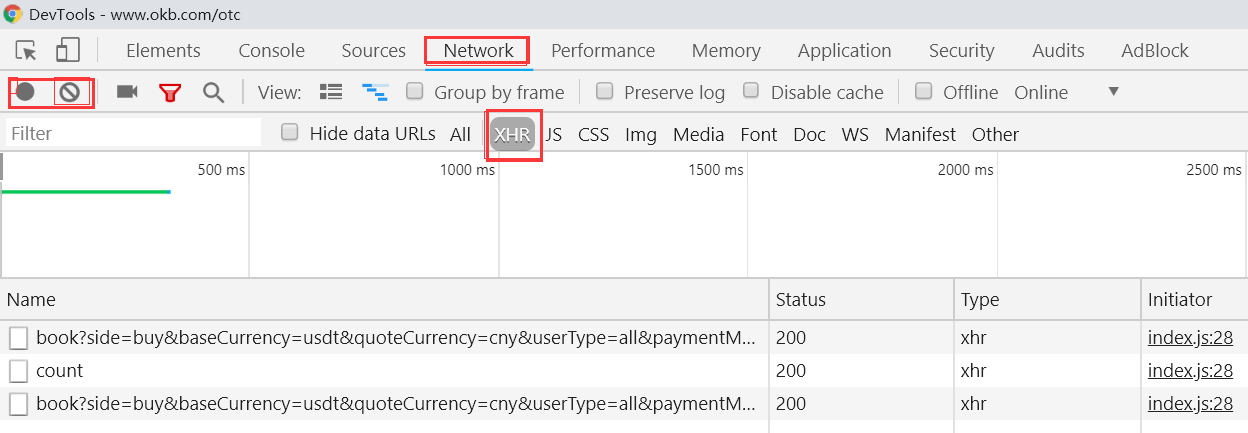
1、F12进入开发者模式 2、点击Network,再点击XHR 3、点击下图左上角两个红框中图标,一个暂停,一个清空 4、点击一个网址,查看Response,是否是需要的数据,如果是,查看Headers,General中的Request URL即为需要请求的网址。
1、两个比较好的学习视频
beautiful soup 库是解析、遍历、维护‘标签数'的功能库
HTTP, Hypertext Transfer Protocol,超文本传输协议
HTTP是一个基于‘请求与响应’模式的、无状态的应用层协议,http协议采用URL作为定位网络资源的标识,URL格式如下:
http://host[:port][path]
host:合法的internet主机域名或ip地址
port:端口号,缺省端口为80
path:请求资源路径
在浏览器中好像可以不用输入端口号,端口号是与ip地址一起使用的
例如:www.baidu.com
cmd 中 ping baidu.com 得到baidu.com ip 123.125.114.144
可以再浏览器中输入 123.125.114.144 或者 123.125.114.144:80 得到都是百度主页,后面80就是默认端口号,输不输入都可
TCP协议 面对面沟通、交流 比如QQ软件 A 与 B交流,A把信息发送到QQ服务器,QQ服务器把信息发送给B,反过来也一样。
UDP协议 广播 (一个人说,其他人听) 比如上计算机课的时候,老师控制我们的电脑屏幕
网络通信的工作原理