表的基础数据类型
数值类型
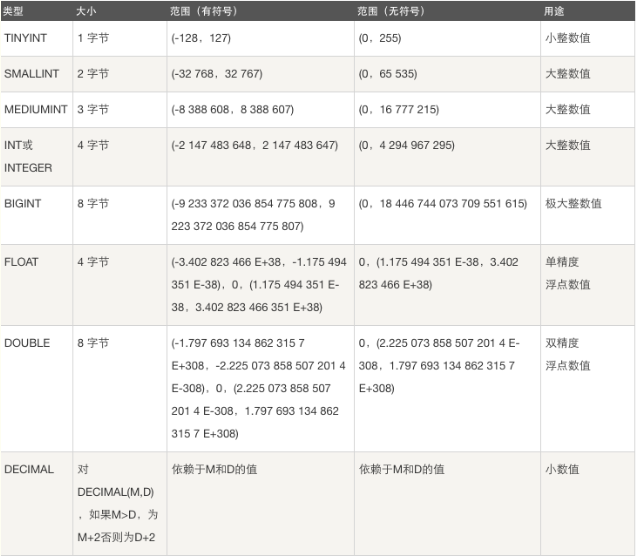
整数类型
类型: tinyint, smallint, mediumint, int, bigint
作用: 存储年龄, 等级, id, 各种号码数据等..
tinyint(m):
小整数值: 数据类型用于保存一些范围的整数数值范围
int(m):
大整数值: 数据类型用于保存一些范围的整数数值范围
bigint(m)
极大整数值: 数据类型用于保存一些范围的整数数值范围
设置无符号
# 数据类型默认都为有符号
# 以int为例
mysql> create table t(x int unsigned)
注意: 对于整型来说, 数据类型后面的宽度并不是存储长度限制, 而是显示限制, 假如: int(8), name显示时不够8位则用0来填充, 够8位则正常显示.
默认的显示宽度就是能够存储的最大的数据的长度, 比如: int无符号类型, 那么默认的显示宽度就是int(10) , 有符号就是int(11), 因为多了一个符号, 所有我们没有必要指定整数类型的数据
浮点型
类型: float, double
作用: 存储薪资, 身高, 温度, 体重, 体质参数等
float(m,d):
单精度浮点数(非准确小数值), m是整数部分 + 小数部分的总个数, d是小数点后个数. m最大值为255, d最大值为30, 例如: float(255,30)
精确度: 随着小数的增多, 精确变得不准确
double(m,d):
双精度浮点数(非准确小数值), m是整数部分 + 小数部分的总个数, d是小数点后个数. m最大值也为255, d最大值也为30
精确度: 随着小数的增多, 精度比float要高, 但也会变得不准确
decimal(m,d):
准确的小数值, m是整数部分 + 小数部分的总个数(负号不算), d是小数点后个数. m最大值为65, d最大值为30. 比float和double的整数个数少, 但是小数位数都是30位
精确度: 随着小数的增多, 精度始终准确. 对于精确数值计算时需要用此类型, decimal能够存储精确值的原因在于其内部按照字符串存储
精度从高到低: decimal, double, float. 前者精度高, 但是位数少. 后两者精度低, 但是整数位较多. float满足绝大多数的场景
日期类型
类型: date, time, datatime, imestamp, year
作用: 存储用户注册时间, 文章发布时间, 员工入职时间, 出生时间, 过期时间等..
year:
YYYY (范围: 1901/2155)
date:
YYYY-MM-DD (范围: 1000-01-01/9999-12-31)
time:
HH:MM:DD (范围: '-838: 59: 59' / '838: 59: 59')
datetime:
YYYY-MM-DD HH: MM: SS (范围: 1000-01-01 00:00:00/9999-12-31 23: 59: 59 )
timestamp:
YYYYMMDD HHMMSS (范围: 1970-01-01 00:00:00/2037)
在时间类型中, now()就相当于time模块中的time.time(), 并自动以格式填充
单独插入时间时, 需要以字符串的形式, 按照对应的格式插入
插入年份时, 尽量使用4位值
插入两位年份时, <=69, 以20开头, >=70, 以19开头
字符串类型
类型: char, varchar
作用: 名字, 信息等等
char:
定长, 简单粗暴, 浪费空间, 存取速度快
字符长度范围: 0~255 (一个中文是一个字符, 是utf8的三个字节)
存储:
指定长度为10, 存 >10个字符 则报错(严格模式下), 存<10 个字符则用空格填充直到凑够10个字符存储
检索:
在检索或者说查询时, 查出的结果会自动删除尾部的空格, 如果你想看到它补全空格之后的内容, 需要打开mode: pad_char_to_full_length
varchar:
变长, 精准, 节省空间, 存取速度慢
字符长度范围: 0~65535 (如果大于21845会提示用其他类型. mysql行最大限制为65535字节, 字符编码为utf-8)
存储:
varchar类型存储数据的真实内容, 不会用空格填充, 如果'ab ', 尾部的空格也会被存起来
强调: varchar类型会在真实数据前加1-2Bytes的前缀, 该前缀用来表示真实数据的bytes字节数(1-2bytes最大表示65535个数字, 正好符合mysql对row的最大字节限制, 已经够用)
如果真实数据 < 255bytes需要1bytes前缀 (1bytes = 8bit 2**8最大表示数字为255)
如果真实的数据>255bytes则需要2bytes的前缀(2bytes = 16bit 2**16最大表示的数字为65535)
检索: 尾部有空格会保存下来, 在检索或者说查询时, 也会正常显示包含空格在内的内容
性能对比
以char(5)和varchar(5)来比较, 加入我要存的三个人名: sb, ssb1, ssbb2
char:
优点: 简单粗暴, 不管你是多长的数据, 只按照规定的长度来存, 5个5个的存, 三个人名就会类似这种存储: sb ssb1 ssbb2, 中间是空格补全, 取数据的时候5个5个的取, 简单粗暴速度快
缺点: 貌似浪费空间, 并且我们将来存储的数据的长度可能会参差不齐
varchar:
varchar类型补丁唱存储数据, 更为精简和节省空间
例如存上面三个人名的时候类似于是这样的: sbssb1ssbb2, 连着的, 如果这样存, 不知道从哪开始从哪结束, 类似于socket解决粘包, 把数据长度作为消息头.
所以, varchar在存数据的时候, 会在每个数据前面加上一个头, 这个头是1-2个bytes的数据, 这个数据指的是后面跟着的这个数据的长度, 1bytes 能表示2**8 = 256, 两个bytes表示2**16 =65536, 能表示0-65535的数字 , 所以存储的时候是这样的: 1bytes + sb +1bytes + ssb1 + 1bytes + ssbb2, 所以存的时候会比较麻烦, 导致效率比char慢, 取的时候也慢, 先拿长度, 再取数据
优点: 节省了一些硬盘空间, 一个acsii码的字符用一个bytes长度就能表示, 但是如果你存储的数据等于你规定的字段长度时, 反而比char占用的空间多.
缺点: 存取速度都慢
枚举类型与集合类型
字段的值只能在给定范围中选择
enum 单选 只能在给定的范围内选一个值, 性别 sex 男male/女female
set 多选 在给定的范围内可以选择一个或一个以上的值
MySQL的mode设置
工作过程中, 一定要使用严格模式
严格模式的设置和修改
方式一:
先执行select @@sql_mode, 复制查询出来的值并将其中的NO_ZERO_IN_DATE, NO_ZERO_DATE删除, 然后执行set sql_mode='修改后的值' ; 例如: set session sql_mode='STRICT_TRANS_TABLES';改为严格模式,
session可以不用写.(此方法只在当前会话中生效, 关闭当前会话就不生效了)
方式二:
先执行select @@global.sql_mode, 复制查询出来的值并将其中的NO_ZERO_IN_DATE, NO_ZERO_DATE删除, 然后执行set global sql_mode = '修改后的值'(此方法在当前服务中生效, 重新mysql服务后失效)
方法三:
在mysql的安装目录下, 或my.cnf文件(windows系统是my.ini文件), 新增 sql_mode = STRICT_TRANS_TABLES 添加my.cnf
表的完整性约束
约束条件与数据类型的宽度一样, 都是可选参数
作用: 用于保证数据的完整性和一致性
not null 与 default
not null
是否可空, null表示空, 非字符串
not null -- 不可空
null -- 可空
default
默认值, 创建时可以指定默认值, 当插入数据时如果未主动设置, 则自动添加默认值
注意
当我们在插入数据时, 可以这么写insert into tb1(nid, num) values(1, 'chao'); 在插入输入的时候, 指定字段插入数据, 如果我在只给num插入值, 可以这样写insert into tb1(num) values('chao'); 还可以插入数据的时候, 指定插入数据字段的顺序: 把nid和num换个位置, 但是对应插入的值也要更换位置.
即使你只给一个字段传值了, 那么也是生成了一整条记录, 这条记录的其他字段的值如果可以为空, 那么他们就是null空值, 如果不能为空, 就会报错(报错的是没有默认值)
unique
独一无二, 唯一属性: id, 身份证号等
是一种key, 唯一键, 是在数据类型之外的附加属性, 其实还有加速查询的作用
方法一:
create table department(id int, name varchar(20) unique, comment varchar(100));
方法二:
create table department2(id int, name varchar(20), comment varchar(100), constraint uk_name unique(name));
联合唯一
create table service(id int primary key auto_increment, name varchar(20), name varchar(15) not null, port int not null, unique(host,port))
primary key
从约束角度看 primary key 字段的值不为空且唯一, 那我们为什不使用 not null + unique.
主键 primary key 是 innodb 存储引擎组织数据的依据, innodb 称之为索引组织表, 一张表中必须有且只有一个主键
一个表中可以:
单列做主键
多列做主键 (复合主键或者叫做联合主键)
unique key 和primary key 都是MySQL的特殊类型, 不仅仅是个字段约束条件, 还称为索引, 可以加快查询速度
强调:
一张表中必须有, 并且只能有一个主键字段: innodb引擎下存储表数据的时候, 会通过你的主键字段的数据来组织管理所有的数据, 将数据做成一种树形结构, 帮你较少IO次数, 提高获取定位数据, 获取数据的速度, 优化查询
如果一张表中没有设置主键, 那么在创建表的时候, 会按照从上到下遍历你设置的字段, 直到找到not null unique的字段,自动识别成主键pri,通过desc可以看到,这样是不是不好啊,所以我们在创建表的时候,要给他一个主键,让他优化的时候用,如果没有pri也没有not null unique字段,那么innodb引擎下的mysql被逼无奈,你没有设置主键字段,主键又有不为空且唯一的约束,又不能擅自给你的字段加上这些约束,那么没办法,它只能给你添加一个隐藏字段来帮你组织数据,如果是这样,你想想,主键是不是帮我们做优化查询用的啊,这个优化是我们可以通过主键来查询数据:例如:如果我们将id设置为主键,当我们查一个id为30的数据的时候,也就是select * from tb1 where id=30;这个查询语句的速度非常快,不需要遍历前面三十条数据,就好像我们使用的字典似的,找一个字,不需要一页一页的翻书,可以首先看目录,然后看在哪一节,然后看在哪一页,一步步的范围,然后很快就找到了,这就像我们说的mysql的索引(主键、唯一键)的工作方式,一步一步的缩小范围来查找,几步就搞定了,所以通过主键你能够快速的查询到你所需要的数据,所以,如果你的主键是mysql帮你加的隐藏的字段,你查询数据的时候,就不能将这个隐藏字段作为条件来查询数据了,就不能享受到优化后的查询速度了,对么
一张表里面,通常都应该有一个id字段,而且通常把这个id字段作为主键,当然你非要让其他的字段作为主键也是可以的,看你自己的设计,创建表的时候,一般都会写create table t1(id int primary key);id int primary key这个东西在建表的时候直接就写上
auto_increment
约束字段为自动增长,被约束的字段必须同时被key约束,也就是说只能给约束成key的字段加自增属性,默认起始位置为1,步长也为1.
foreign key
外键, 建立表和表之间的关系
一对多(多对一)

多的表里面添加一个字段,并给这个字段加foreign key,比如:
出版社对应书籍是多对一的关系
1.先创建出版社表 publish表
2.创建书籍表,外键写法:
create table book(
id int primary key,
name char(10),
pid int,
foreign key(pid) references publish(id)
);
3.先给出版社插入数据
一对一

一对一关系
学生表(student)和客户表(customer)
create table student(
id int primary key,
name char(10),
cid int unique,
foreign key(cid) references customer(id)
);
多对多
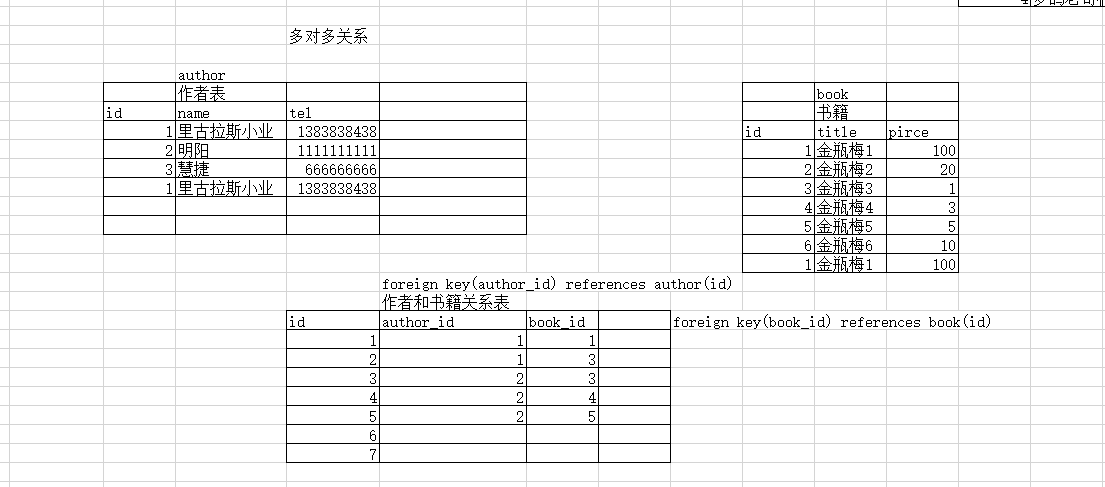
多对多关系
作者表和书籍表
需要借助第三张表来完整两者的关系记录
第三张表后创建
create table authortobook(
id int primary key,
author_id int,
book_id int,
foreign key(author_id) references author1(id),
foreign key(book_id) references book(id)
);