如果将 Hadoop 比做一头大象,那么 MapReduce 就是那头大象的电脑。MapReduce 是 Hadoop 核心编程模型。在 Hadoop 中,数据处理核心就是 MapReduce 程序设计模型
1. MapReduce 编程模型
Map 和 Reduce 的概念是从函数式变成语言中借来的,整个 MapReduce 计算过程分 为 Map 阶段和 Reduce 阶段,也称为映射和缩减阶段,这两个独立的阶段实际上是两个独 立的过程,即 Map 过程和 Reduce 过程,在 Map 中进行数据的读取和预处理,之后将预 处理的结果发送到 Reduce 中进行合并。 我们通过一个代码案例,让大家快速熟悉如何通过代码,快速实现一个我们自己的 MapReduce。 案例:分布式计算出一篇文章中的各个单词出现的次数,也就是 WordCount。
1) 准备一个英文单词的txt文章(这是我从saltstack官网复制下来的一段用来测试练习)


[root@master mr_word_count]# cat the_man_of_property.txt SaltStack is a revolutionary approach to infrastructure management that replaces complexity with speed. SaltStack is simple enough to get running in minutes, scalable enough to manage tens of thousands of servers, and fast enough to communicate with each system in seconds. SaltStack is a powerful remote execution tool and configuration management system. In this series, we will use Salt to configure reproducible development, staging, and production environments onto which we can deploy an application. This is primarily meant as a learning exercise to demonstrate some common Salt components and strategies that can be used to control your infrastructure. Now that you are familiar with the basic SaltStack terminology and have a high level understanding of what the tools you'll encounter are responsible for, you can begin setting up Salt to control your infrastructure. In the next guide, we will cover how to install and configure a Salt master server on an Ubuntu 14.04 server. We will also demonstrate how to configure new minion servers to bring them under your master's management. Introduction Salt, or SaltStack, is a remote execution tool and configuration management system. The remote execution capabilities allow administrators to run commands on various machines in parallel with a flexible targeting system. The configuration management functionality establishes a client-server model to quickly, easily, and securely bring infrastructure components in line with a given policy. In this guide, we will discuss some of the basic concepts and terminology needed to begin effectively learning to use Salt. Salt Machine Roles Salt's control structure is fairly simple as configuration management systems go. In a typical setup, there are only two distinct classes of machines. Master The Salt master is the machine that controls the infrastructure and dictates policies for the servers it manages. It operates both as a repository for configuration data and as the control center that initiates remote commands and ensures the state of your other machines. A daemon called salt-master is installed on the master to provide this functionality. While it is possible to control infrastructure using a masterless configuration, most setups benefit from the advanced features available in the Salt master. In fact, for larger infrastructure management, Salt has the ability to delegate certain components and tasks typically associated with the master to dedicated servers. It can also operate in a tiered master configuration where commands can be relayed through lower master machines. Minions The servers that Salt manages are called minions. A daemon called salt-minion is installed on each of the managed machines and configured to communicate with the master. The minion is responsible for executing the instructions sent by the master, reporting on the success of jobs, and providing data about the underlying host. How Salt Components Communicate Salt masters and minions, by default, communicate using the ZeroMQ messaging library. This provides extremely high performance network communication between parties, allowing Salt to send messages and data at rapid speeds. Because ZeroMQ is a library and not an independent service, this functionality is available in the salt-master and salt-minion daemons natively. When using ZeroMQ, Salt maintains a public key system for authenticating masters and minions. Upon first boot, a minion generates a key pair and sends its credentials to the master server it is configured to contact. The master can then accept this key after verifying the identity of the minion. The two parties can then communicate quickly and securely using ZeroMQ encrypted with the keys. If for some reason it is impossible to install the salt-minion daemon on a node, Salt can also issue commands over SSH. This transport option is provided for convenience, but it degrades performance quite considerably and can lead to complications with other Salt commands in some instances. It is highly recommended that you use the salt-minion daemon where possible for performance, security, and simplicity. Salt Terminology Before diving into Salt, it is a good idea to familiarize yourself with some of the terminology that will be used. Salt has many powerful features, but it can be difficult to match names with their functionality at first. Let's take a look at some of the more general terms you are likely to see. Remote Execution: Execution Modules and Functions Salt attempts to provide a distinction between its remote execution and configuration management functions. The remote execution capabilities are provided by execution modules. Execution modules are sets of related functions that perform work on minions. While Salt includes functions that allow you to run arbitrary shell commands on minions, the idea behind execution modules is to provide a concise mechanism for executing commands without having to "shell out" and provide detailed instructions about how to complete the process. The use of modules allows Salt to abstract the underlying differences between systems. You can get similar information from minions running Linux or BSD, even though the actual mechanisms to gather that data would be different. Salt comes with a decent selection of builtin execution modules to provide out-of-the-box functionality. Administrators can also write their own modules or include community-written modules to extend the library of commands that can be executed on minion machines. Configuration Management: States, Formulas, and Templates The configuration management functionality of Salt can be accessed by creating repositories of configuration files. The files contained within these repositories can be of a few different types. States and Formulas The configuration management portion of Salt is primarily implemented using the state system. The state system uses state modules, which are distinct from the execution modules described above. Fortunately, state and execution modules tend to mirror each other quite closely. The state system is aptly named, as it allows an administrator to describe the state that a system should be placed in. As with execution modules, most state modules represent functionality shortcuts and provide easy syntax for many common actions. This helps maintain readability and removes the necessity of including complex logic in the configuration management files themselves. Salt formulas are sets of state module calls, arranged with the aim of producing a certain result. These are the configuration management files that describe how a system should look once the formula has been applied. By default, these are written in the YAML data serialization format, which provides a very good middle ground between high-readability and machine-friendliness. The Salt administrator can apply formulas by mapping minions to specific sets of formulas. Formulas can also be applied in an ad hoc manner as needed. Minions will execute the state modules found within to bring its system in line with the provided policy. A good collection of Salt formulas created by the SaltStack organization and community can by found in this GitHub account. Templates Templating allows Salt formulas and other files to be written in a more flexible manner. Templates can use the information available about the minions to construct customized versions of formula or configuration files. By default, Salt uses the Jinja template format, which provides substitution functionality and simple logical constructs for decision making. Renderers are the components that runs the template to produce valid state or configuration files. Renderers are defined by the templating format that constitutes the input and the data serialization format that will be produced as an output. Considering the defaults described above, the default renderer processes Jinja templates in order to produce YAML files. Querying about and Assigning Information to Minions In order to manage vast numbers of systems, Salt requires some information about each of the host systems. The templates described above can use data associated with each system to tailor the behavior of each minion. There are a few different systems in place to query about or assign this information to hosts. Grains Salt grains are pieces of information, gathered by and maintained by a minion, primarily concerning its underlying host system. These are typically collected by the salt-minion daemon and passed back to the master upon request. This functionality can be leveraged for many different purposes. For instance, grain data can be used for targeting a specific subset of nodes from the pool of minions for remote execution or configuration management. If you want to see the uptime of your Ubuntu servers, grains allow you to target only these machines. Grains can also be used as arguments for configuration changes or commands. For example, you can use grains to get the IPv4 address associated with the eth0 interface for a change to a configuration file or as an argument to a command. Administrators can also assign grains to minions. For instance, it is fairly common to use grains to assign a "role" to a server. This can then be used to target a subset of nodes similar to the operating system example above. Pillars While it is possible to assign grains to minions, the vast majority of configuration variables will be assigned through the pillars system. In Salt, a pillar represents a key-value store that a minion can use to retrieve arbitrary assigned data. This functions as a dictionary data structure which can be nested or tiered for organizational purposes. Pillars offer a few important advantages over the grain system for assigning values. Most importantly, pillar data is only available to the minions assigned to it. Other minions will not have access to the values stored within. This makes it ideal for storing sensitive data specific to a node or a subset of nodes. For instance, secret keys or database connection strings are often provided in a pillar configuration. Pillar data is often leveraged in the configuration management context as a way to inject variable data into a configuration template. Salt offers a selection of template formats for replacing the variable portions of a configuration file with the items specific to the node that will be applying it. Grains are also often used in this way for referencing host data. Mine Salt mine is an area on the master server where the results from regularly executed commands on minions can be stored. The purpose of this system is to collect the results of arbitrary commands run on minion machines. This global store can then be queried by other components and minions throughout your infrastructure. The Salt mine only stores the most recent result for each command run, meaning that it will not help you if you need access to historic data. The main purpose of the mine is to provide up-to-date information from minion machines as a flexible supplement to the grain data that is already available. Minions can query data about their counterparts using the mine system. The interval in which the minion refreshes the data in the mine can be configured on a per-minion basis. Additional Functionality Salt provides a few other systems that do not fit nicely into the above categories. Reactors The Salt reactor system provides a mechanism for triggering actions in response to generated events. In Salt, changes occurring throughout your infrastructure will cause the salt-minion or salt-master daemons to generate events on a ZeroMQ message bus. The reactor system watches this bus and compares events against its configured reactors in order to respond appropriately. The main goal of the reactor system is to provide a flexible system for creating automated situational responses. For instance, if you have developed an auto-scaling strategy, your system will automatically create nodes to dynamically meet your resource demands. Each new node would trigger an event. A reactor could be set up to listen to these events and configure the new node, incorporating it into the existing infrastructure. Runners Salt runners are modules that execute on the master server instead of minions. Some runners are general purpose utilities used to check the status of various parts of the system or to do maintenance. Some are powerful applications that provide the ability to orchestrate your infrastructure on a broader scale. Returners Salt returners are used to specify alternative locations where the results of an action run on a minion will be sent. By default, minions return their data to the master. A returner allows the administrator to re-route the return data to a different destination. Typically, this means that the results are returned to the destination specified by the returner and to the process that initiated the minion command. Most often, returners will pass the results off to a database system or a metrics or logging service. This provides a flexible method for getting arbitrary data into these systems. Returners can also be used to collect Salt-specific data like job caches and event data. Salt Commands Salt provides a number of commands to take advantage of the components outlined above. There is some significant crossover in terms of functionality between these tools, but we've attempted to highlight their primary functions below. salt-master: This is the master daemon process. You can start the master service with this command directly, or more typically, through an init script or service file. salt-minion: Likewise, this is minion daemon process, used to communicate with the master and execute commands. Most users will also start this from init scripts or service files. salt-key: This tool is used to manage minion public keys. This tool is used to view current keys and to make decisions about public keys sent by prospective minions. It can also generate keys to place on minions out-of-band. salt: This command is used to target minions in order to run ad-hoc execution modules. This is the main tool used for remote execution. salt-ssh: This command allows you to use SSH as an alternative to ZeroMQ for the transport mechanism. salt-run: This command is used to run runner modules on the master server. salt-call: This command is used to run execution modules directly on a minion you are logged into. This is often used to debug problematic commands by bypassing the master. salt-cloud: This command is used to control and provision cloud resources from many different providers. New minions can easily be spun up and bootstrapped. There are some other commands as well, like salt-api, salt-cp, and salt-syndic, which aren't used quite so often. Conclusion Now that you are familiar with the basic SaltStack terminology and have a high level understanding of what the tools you'll encounter are responsible for, you can begin setting up Salt to control your infrastructure. In the next guide, we will cover how to install and configure a Salt master server on an Ubuntu 14.04 server. We will also demonstrate how to configure new minion servers to bring them under your master's management.
2) 创建 map.py 文件,写入以下代码:
[root@master mr_word_count]# cat map.py #!/usr/bin/env python import sys world_list=[] for line in sys.stdin: ss=line.strip().split(' ') for word in ss: print ' '.join([word.strip(),"1"])
该代码主要工作是从文章数据源逐行读取,文章中的单词之间以空格分割, word_list = line.strip().split(' ')这块代码是将当前读取的一整行数据按照空格分割,将 分割后的结果存入 word_list 数组中,然后通过 for word in word_list 遍历数组,取出每 个单词,后面追加“1”标识当前 word 出现 1 次。
# 如果设置白名单过滤机制,指定字符进行数据处理
修改map.py
[root@master mr_word_count]# cat map.py #!/usr/bin/python import sys def read_local_file_func(f): #读取含有所要过滤的字符串的文件 word_set=set() #声明一个集合 file_in=open(f,'r') #打开一文件读取 for line in file_in: #逐行读取,并将每一行的内容存进集合中,最后返回这个集合。 word= line.strip() word_set.add(word) return word_set def mapper_func(white_list_fd): #将上个函数的返回值(word_set集合)赋值给局部变量 word_set 并对标准输入的内容判断,如果不为空且 输入的内容的这行在这个集合(word_set)内就记录这个单词 一次。 word_set=read_local_file_func(white_list_fd) for line in sys.stdin: ss=line.strip().split(' ') for s in ss: word = s.strip() if word != "" and (word in word_set): print "%s %s" %(s,1) if __name__ == "__main__": module = sys.modules[__name__] func =getattr(module,sys.argv[1]) args=None if len(sys.argv) > 1: args = sys.argv[2:] func(*args)
白名单文件 white_list (过滤出三个单词 is SaltStack to)
[root@master mr_word_count]# cat white_list is SaltStack to
简单测试下脚本
[root@master mr_word_count]# head -1 the_man_of_property.txt >1.txt|cat 1.txt |python map.py SaltStack 1 is 1 a 1 revolutionary 1 approach 1 to 1 infrastructure 1 management 1
3) 创建 reduce.py,写入以下代码:
[root@master mr_word_count]# cat reduce.py import sys cur_word=None sum=0 for line in sys.stdin: ss=line.strip().split(' ') if len(ss) !=2: #如果每一行 不是两个字符(一个单词,一个是计数1)就跳出本次循环 continue word =ss[0].strip() cnt=ss[1].strip() if cur_word==None: cur_word=word if cur_word !=word: print ' '.join([cur_word,str(sum)]) cur_word=word sum=0 sum +=int(cnt) #对相同单词的 计数做累加。 print ' '.join([cur_word,str(sum)])
该代码针对 map 阶段的数组进行汇总处理,map 到 reduce 过程中默认存在 shuffle partition 分组机制,保证同一个 word 的记录,会连续传输到 reduce 中,所以在 reduce 阶段只需要对连续相同的 word 后面的技术进行累加求和即可。
4)编写执行脚本run.sh
[root@master mr_word_count]# cat run.sh #!/bin/bash #启动hadoop的命令 HADOOP_CMD="/home/hadoop/hadoop-1.2.1/bin/hadoop" #hadoop的streaming-jar包存放路径 STREAM_JAR_PATH="/home/hadoop/hadoop-1.2.1/contrib/streaming/hadoop-streaming-1.2.1.jar" #需要处理的文件在hdfs的存放路径 INPUT_FILE_PATH_1="/the_man_of_property.txt" #处理完文件存放在hdfs的位置 OUTPUT_PATH="/output" #如果已经存在这样的一个文件必须先在hdfs中删除 $HADOOP_CMD fs -rmr -skipTrash $OUTPUT_PATH # Step 1. $HADOOP_CMD jar $STREAM_JAR_PATH -input $INPUT_FILE_PATH_1 -output $OUTPUT_PATH -mapper "python map.py"
# -mapper "python map.py mapper_func white_list" 如果是启动白名单过滤就使用这样的方式执行map.py -reducer "python reduce.py"
# -jobconf "mapred.reduce.tasks=2" 设置tasktracker的数量 -file ./map.py -file ./reduce.py
# -file ./white_list 如果需要过滤白名单,就上传白名单文件到hdfs 根目录下
(大文件用cache-file)
如果文件(如字典文件)存放在HDFS中,希望计算时在每个计算节点上将文件当作文件本地文件处理,可以使用-cacheFile
hdfs://host:port/path/to/file#linkname 选项在计算节点缓存文件
Straming程序通过./linkname 访问文件。
(目录用cacheArchive)
#如果要分发的文件有目录结构,可以先将整个目录打包,然后上传到hdfs上,再用-cacheArchive hdfs://host:port/path/to/archivefile #linkname 分发压缩包。
5) 运行脚本效果如下
#执行脚本之前我们需要将文章上传到hdfs根目录下面
[root@master mr_word_count]# hdfs -put the_man_of_property.txt /
# 然后执行。
[root@master mr_word_count]# bash run.sh Deleted hdfs://10.0.0.10:9000/output packageJobJar: [./map.py, ./reduce.py, /home/hadoop/hadoop-1.2.1/tmp/hadoop-unjar5314990269258431388/] [] /tmp/streamjob684417866208315819.jar tmpDir=null 18/03/21 11:49:35 INFO util.NativeCodeLoader: Loaded the native-hadoop library 18/03/21 11:49:35 WARN snappy.LoadSnappy: Snappy native library not loaded 18/03/21 11:49:35 INFO mapred.FileInputFormat: Total input paths to process : 1 18/03/21 11:49:36 INFO streaming.StreamJob: getLocalDirs(): [/home/hadoop/hadoop-1.2.1/tmp/mapred/local] 18/03/21 11:49:36 INFO streaming.StreamJob: Running job: job_201803211104_0006 18/03/21 11:49:36 INFO streaming.StreamJob: To kill this job, run: 18/03/21 11:49:36 INFO streaming.StreamJob: /home/hadoop/hadoop-1.2.1/libexec/../bin/hadoop job -Dmapred.job.tracker=http://10.0.0.10:9001 -kill job_201803211104_0006 18/03/21 11:49:36 INFO streaming.StreamJob: Tracking URL: http://master:50030/jobdetails.jsp?jobid=job_201803211104_0006 18/03/21 11:49:37 INFO streaming.StreamJob: map 0% reduce 0% 18/03/21 11:49:41 INFO streaming.StreamJob: map 100% reduce 0% 18/03/21 11:49:49 INFO streaming.StreamJob: map 100% reduce 33% 18/03/21 11:49:51 INFO streaming.StreamJob: map 100% reduce 100% 18/03/21 11:49:53 INFO streaming.StreamJob: Job complete: job_201803211104_0006 18/03/21 11:49:53 INFO streaming.StreamJob: Output: /output
6)网页查看
想用master主机名访问别忘记linux终端和windows都要做dns解析
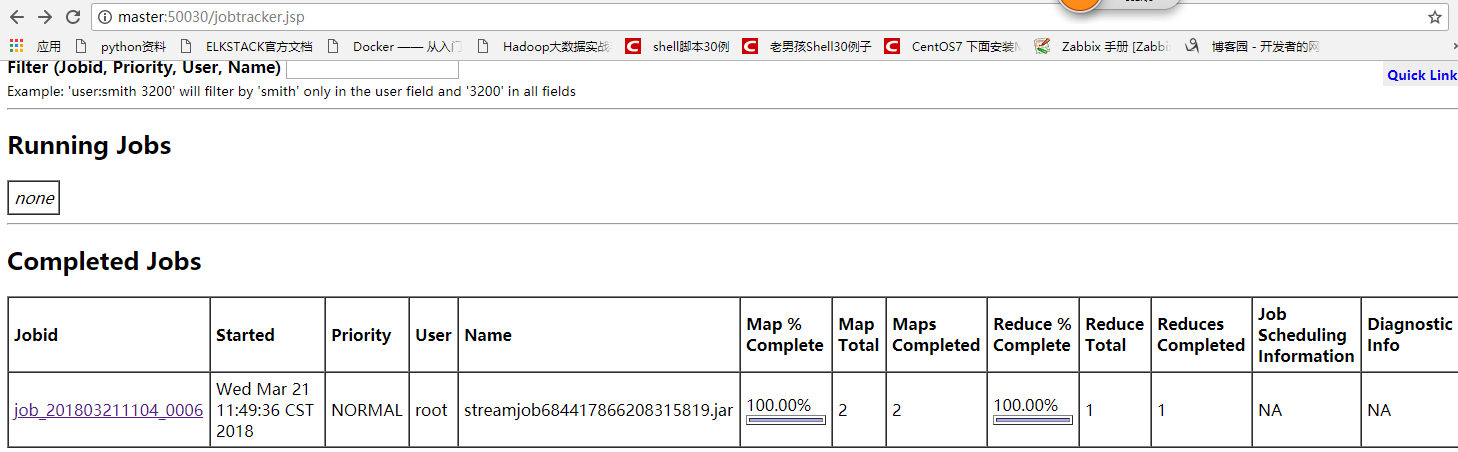
点击该complete 任务进去查看
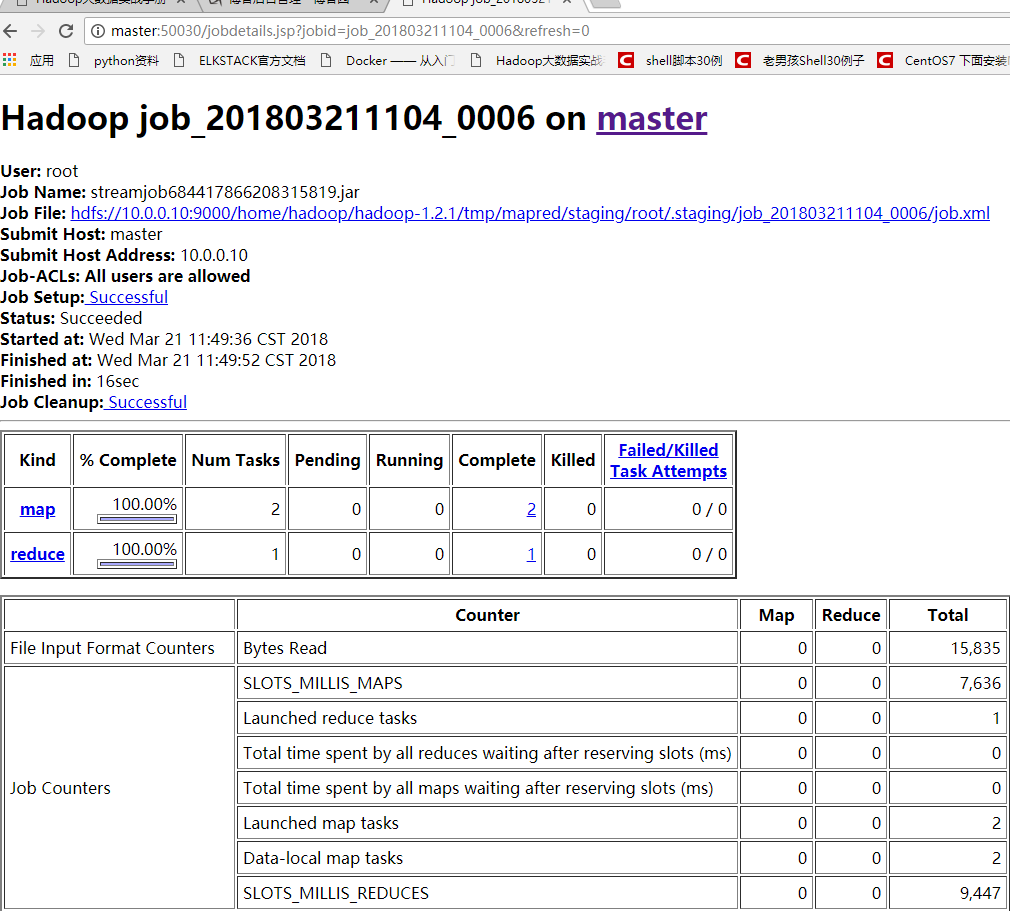
监控表分析

map的输入:map input records 110 代表我的文章行数
[root@master mr_word_count]# cat the_man_of_property.txt|wc -l 110
map的输出: Map output records 代表map.py 脚本处理的行数 作为reduce的输入,所以Reduce input records 也是2444
[root@master mr_word_count]# cat the_man_of_property.txt |python map.py |wc -l 2444
reduce的输出:Reduce output records
[root@master mr_word_count]# cat the_man_of_property.txt |python map.py |sort -k1 |python reduce.py |wc -l 805
将处理结果dump到本地
[root@master mr_word_count]# hdfs fs -get /output/part-00000 .
7) 脚本执行流程:
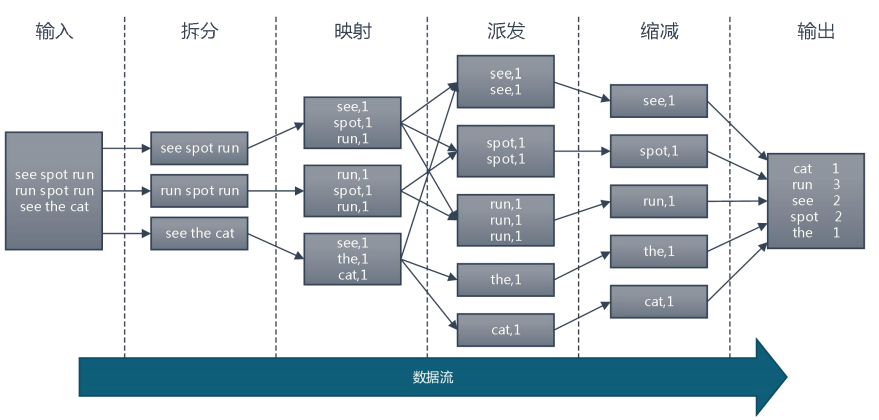
2. MapReduce 执行流程
上面的例子属于 MapReduce 计算框架的一般流程,经过整理总结:
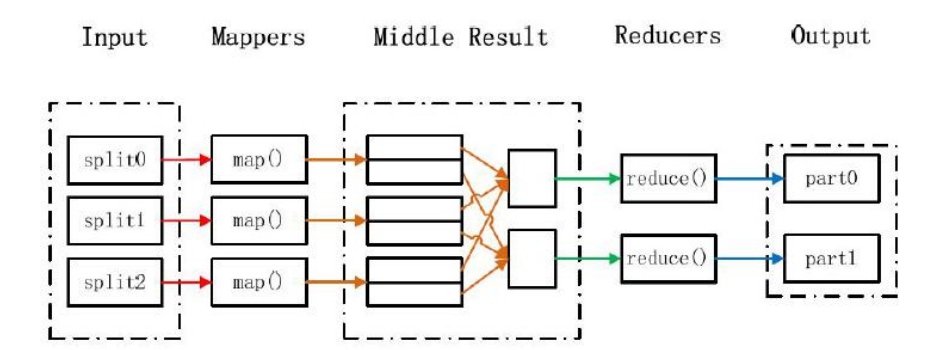
1) 输入和拆分:
不属于 map 和 reduce 的主要过程,但属于整个计算框架消耗时间的一部分,该部分 会为正式的 map 准备数据。
分片(split)操作:
split 只是将源文件的内容分片形成一系列的 InputSplit,每个 InputSpilt 中存储着对 应分片的数据信息(例如,文件块信息、起始位置、数据长度、所在节点列表…),并不是 将源文件分割成多个小文件,每个 InputSplit 都由一个 mapper 进行后续处理。
每个分片大小参数是很重要的,splitSize 是组成分片规则很重要的一个参数,该参数 由三个值来确定:
minSize:splitSize 的最小值,由 mapred-site.xml 配置文件中 mapred.min.split.size 参数确定。
maxSize:splitSize 的最大值,由 mapred-site.xml 配置文件中 mapreduce.jobtracker.split.metainfo.maxsize 参数确定。
blockSize:HDFS 中文件存储的快大小,由 hdfs-site.xml 配置文件中 dfs.block.size 参数确定。
splitSize 的确定规则:splitSize=max{minSize,min{maxSize,blockSize}}
数据格式化(Format)操作:
将划分好的 InputSplit 格式化成键值对形式的数据。其中 key 为偏移量,value 是每一 行的内容。
值得注意的是,在 map 任务执行过程中,会不停的执行数据格式化操作,每生成一个 键值对就会将其传入 map,进行处理。所以 map 和数据格式化操作并不存在前后时间差, 而是同时进行的。

2) Map 映射: 是 Hadoop 并行性质发挥的地方。根据用户指定的 map 过程,MapReduce 尝试在数 据所在机器上执行该 map 程序。在 HDFS 中,文件数据是被复制多份的,所以计算将会选 择拥有此数据的最空闲的节点。
在这一部分,map 内部具体实现过程,可以由用户自定义
3) Shuffle 派发:
Shuffle 过程是指 Mapper 产生的直接输出结果,经过一系列的处理,成为最终的 Reducer 直接输入数据为止的整个过程。这是 mapreduce 的核心过程。该过程可以分为两 个阶段:
Mapper 端的 Shuffle:由 Mapper 产生的结果并不会直接写入到磁盘中,而是先存 储在内存中,当内存中的数据量达到设定的阀值时,一次性写入到本地磁盘中。并同时进行 sort(排序)、combine(合并)、partition(分片)等操作。其中,sort 是把 Mapper 产 生的结果按照 key 值进行排序;combine 是把 key 值相同的记录进行合并;partition 是把 数据均衡的分配给 Reducer。
Reducer 端的 Shuffle:由于 Mapper 和 Reducer 往往不在同一个节点上运行,所以 Reducer 需要从多个节点上下载 Mapper 的结果数据,并对这些数据进行处理,然后才能 被 Reducer 处理。
4) Reduce 缩减:
Reducer 接收形式的数据流,形成形式的输出,具体的过程可以由用户自定义,最终 结果直接写入 hdfs。每个 reduce 进程会对应一个输出文件,名称以 part-开头。
3. MapReduce 数据本地化(Data-Local)
首先,HDFS 和 MapReduce 是 Hadoop 的核心设计。对于 HDFS,是存储基础,在 数据层面上提供了海量数据存储的支持。而 MapReduce,是在数据的上一层,通过编写 MapReduce 程序对海量数据进行计算处理。
在前面 HDFS 章节中,知道了 NameNode 是文件系统的名字节点进程,DataNode 是文件系统的数据节点进程。
MapReduce 计算框架中负责计算任务调度的 JobTracker 对应 HDFS 的 NameNode 的角色,只不过一个负责计算任务调度,一个负责存储任务调度。
MapReduce 计算框架中负责真正计算任务的 TaskTracker对应到HDFS 的DataNode 的角色,一个负责计算,一个负责管理存储数据。
考虑到“本地化原则”,一般地,将 NameNode 和 JobTracker 部署到同一台机器上, 各个 DataNode 和 TaskNode 也同样部署到同一台机器上。

这样做的目的是将 map 任务分配给含有该 map 处理的数据块的 TaskTracker 上,同 时将程序 JAR 包复制到该 TaskTracker 上来运行,这叫“运算移动,数据不移动”。而分配 reduce 任务时并不考虑数据本地化。
4. MapReduce 工作原理
我们通过 Client、JobTrask 和 TaskTracker 的角度来分析 MapReduce 的工作原理:
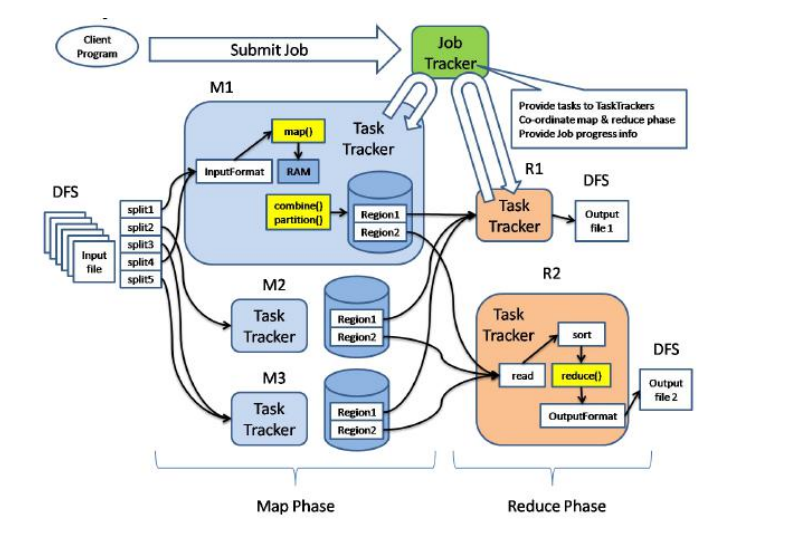
首先在客户端(Client)启动一个作业(Job),向 JobTracker 请求一个 Job ID。将运 行作业所需要的资源文件复制到 HDFS 上,包括 MapReduce 程序打包的 JAR 文件、配置 文件和客户端计算所得的输入划分信息。这些文件都存放在 JobTracker 专门为该作业创建 的 文 件 夹 中 , 文 件 夹 名 为 该 作 业 的 Job ID 。 JAR 文 件 默 认 会 有 10 个 副 本 (mapred.submit.replication 属性控制);输入划分信息告诉了 JobTracker 应该为这个作 业启动多少个 map 任务等信息。
JobTracker 接收到作业后,将其放在一个作业队列里,等待作业调度器对其进行调度 当作业调度器根据自己的调度算法调度到该作业时,会根据输入划分信息为每个划分创建一 个 map 任务,并将 map 任务分配给 TaskTracker 执行。对于 map 和 reduce 任务, TaskTracker 根据主机核的数量和内存的大小有固定数量的 map 槽和 reduce 槽。这里需要 强调的是:map 任务不是随随便便地分配给某个 TaskTracker 的,这里就涉及到上面提到 的数据本地化(Data-Local)。
TaskTracker 每隔一段时间会给 JobTracker 发送一个心跳,告诉 JobTracker 它依然在 运行,同时心跳中还携带着很多的信息,比如当前 map 任务完成的进度等信息。当 JobTracker 收到作业的最后一个任务完成信息时,便把该作业设置成“成功”。当 JobClient 查询状态时,它将得知任务已完成,便显示一条消息给用户。
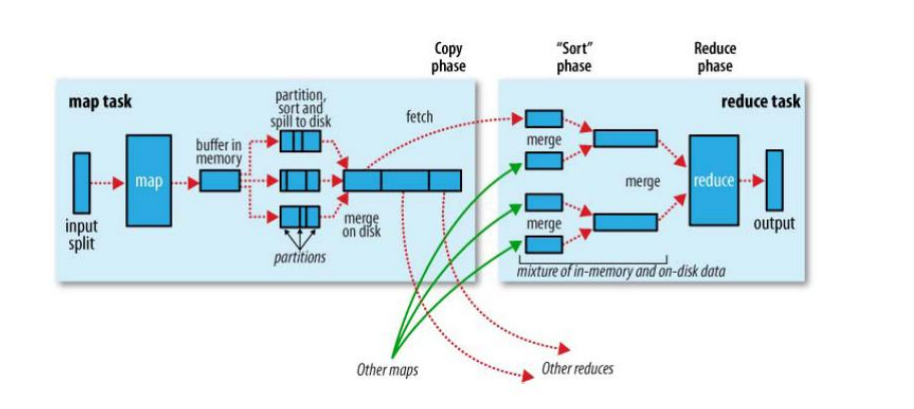
如果具体从 map 端和 reduce 端分析,可以参考上面的图片,具体如下:
Map 端流程:
1) 每个输入分片会让一个 map 任务来处理,map 输出的结果会暂且放在一个环形内 存缓冲区中(该缓冲区的大小默认为 100M,由 io.sort.mb 属性控制),当该缓冲 区快要溢出时(默认为缓冲区大小的 80%,由 io.sort.spill.percent 属性控制), 会在本地文件系统中创建一个溢出文件,将该缓冲区中的数据写入这个文件。
2) 在写入磁盘之前,线程首先根据reduce任务的数目将数据划分为相同数目的分区, 也就是一个 reduce 任务对应一个分区的数据。这样做是为了避免有些 reduce 任 务分配到大量数据,而有些 reduce 任务却分到很少数据,甚至没有分到数据的尴 尬局面。其实分区就是对数据进行 hash 的过程。然后对每个分区中的数据进行排 序,如果此时设置了 Combiner,将排序后的结果进行 Combine 操作,这样做的 目的是让尽可能少的数据写入到磁盘。
3) 当 map 任务输出最后一个记录时,可能会有很多的溢出文件,这时需要将这些文 件合并。合并的过程中会不断地进行排序和 Combine 操作,目的有两个:
尽量减少每次写入磁盘的数据量;
尽量减少下一复制阶段网络传输的数据量。
最后合并成了一个已分区且已排序的文件。为了减少网络传输的数据量,这里可以 将数据压缩,只要将 mapred.compress.map.out 设置为 true 就可以了。
4) 将分区中的数据拷贝给相对应的 reduce 任务。分区中的数据怎么知道它对应的 reduce 是 哪个 呢? 其 实 map 任 务一 直和 其 父 TaskTracker 保 持联 系, 而 TaskTracker 又一直和 JobTracker 保持心跳。所以 JobTracker 中保存了整个集群 中的宏观信息。只要 reduce 任务向 JobTracker 获取对应的 map 输出位置就可以 了。
Reduce 端流程:
1) Reduce 会接收到不同 map 任务传来的数据,并且每个 map 传来的数据都是有序 的。如果 reduce 端接受的数据量相当小,则直接存储在内存中(缓冲区大小由 mapred.job.shuffle.input.buffer.percent 属性控制,表示用作此用途的堆空间的 百 分 比 ), 如 果 数 据 量 超 过 了 该 缓 冲 区 大 小 的 一 定 比 例 ( 由 mapred.job.shuffle.merge.percent 决定),则对数据合并后溢写到磁盘中。
2) 随着溢写文件的增多,后台线程会将它们合并成一个更大的有序的文件,这样做是 为了给后面的合并节省时间。其实不管在 map 端还是 reduce 端,MapReduce 都是反复地执行排序,合并操作,所以排序是 hadoop 的灵魂。
3) 合并的过程中会产生许多的中间文件(写入磁盘了),但 MapReduce 会让写入磁 盘的数据尽可能地少,并且最后一次合并的结果并没有写入磁盘,而是直接输入到 reduce 函数。
在 Map 处理数据后,到 Reduce 得到数据之前,这个流程在 MapReduce 中可以看做 是一个 Shuffle 的过程。
在经过 mapper 的运行后,我们得知 mapper 的输出是这样一个 key/value 对。到底 当前的 key 应该交由哪个 reduce 去做呢,是需要现在决定的。 MapReduce 提供 Partitioner 接口,它的作用就是根据 key 或 value 及 reduce 的数量来决定当前的这对输 出数据最终应该交由哪个 reduce task 处理。默认对 key 做 hash 后再以 reduce task 数 量取模。默认的取模方式只是为了平均 reduce 的处理能力,如果用户自己对 Partitioner 有需求,可以订制并设置到 job 上。
5. MapReduce 错误处理机制
MapReduce 任务执行过程中出现的故障可以分为两大类:硬件故障和任务执行失败引 发的故障。
1) 硬件故障
在 Hadoop Cluster 中,只有一个 JobTracker,因此,JobTracker 本身是存在单点故 障的。如何解决 JobTracker 的单点问题呢?我们可以采用主备部署方式,启动 JobTracker 主节点的同时,启动一个或多个 JobTracker 备用节点。当 JobTracker 主节点出现问题时, 通过某种选举算法,从备用的 JobTracker 节点中重新选出一个主节点。
机器故障除了 JobTracker 错误就是 TaskTracker 错误。TaskTracker 故障相对较为常 见,MapReduce 通常是通过重新执行任务来解决该故障。
在 Hadoop 集群中,正常情况下,TaskTracker 会不断的与 JobTracker 通过心跳机制 进行通信。如果某 TaskTracker 出现故障或者运行缓慢,它会停止或者很少向 JobTracker 发送心跳。如果一个 TaskTracker 在一定时间内(默认是 1 分钟)没有与 JobTracker 通信, 那么 JobTracker 会将此 TaskTracker 从等待任务调度的 TaskTracker 集合中移除。同时 JobTracker 会要求此 TaskTracker 上的任务立刻返回。如果此 TaskTracker 任务仍然在 mapping 阶段的 Map 任务,那么 JobTracker 会要求其他的 TaskTracker 重新执行所有原 本由故障 TaskTracker 执行的 Map 任务。如果任务是在 Reduce 阶段的 Reduce 任务,那 么 JobTracker 会要求其他 TaskTracker 重新执行故障 TaskTracker 未完成的 Reduce 任务。 比如:一个 TaskTracker 已经完成被分配的三个 Reduce 任务中的两个,因为 Reduce 任务 一旦完成就会将数据写到 HDFS 上,所以只有第三个未完成的 Reduce 需要重新执行。但 是对于 Map 任务来说,即使 TaskTracker 完成了部分 Map,Reduce 仍可能无法获取此节 点上所有 Map 的所有输出。所以无论 Map 任务完成与否,故障 TaskTracker 上的 Map 任 务都必须重新执行。
2) 任务执行失败引发的故障
在实际任务中,MapReduce 作业还会遇到用户代码缺陷或进程崩溃引起的任务失败等 情况。用户代码缺陷会导致它在执行过程中抛出异常。此时,任务 JVM 进程会自动退出,并 向 TaskTracker 父进程发送错误消息,同时错误消息也会写入 log 文件,最后 TaskTracker 将此次任务尝试标记失败。对于进程崩溃引起的任务失败,TaskTracker 的监听程序会发现 进程退出,此时 TaskTracker 也会将此次任务尝试标记为失败。对于死循环程序或执行时间 太长的程序,由于 TaskTracker 没有接收到进度更新,它也会将此次任务尝试标记为失败, 并杀死程序对应的进程。
在以上情况中,TaskTracker 将任务尝试标记为失败之后会将 TaskTracker 自身的任务 计数器减 1,以便想 JobTracker 申请新的任务。TaskTracker 也会通过心跳机制告诉 JobTracker 本地的一个任务尝试失败。JobTracker 接到任务失败的通知后,通过重置任务 状态,将其加入到调度队列来重新分配该任务执行(JobTracker 会尝试避免将失败的任务 再次分配给运行失败的 TaskTracker)。如果此任务尝试了 4 次(次数可以进行设置)仍没 有完成,就不会再被重试,此时整个作业也就失败了。