最近本人负责对营销系统中出现的接口响应慢的情况进行优化,以下是根据我在营销系统的经验。本文旨在总结通用的经验,提供思路,而不涉及具体的技术实现。
优化的效果如下:
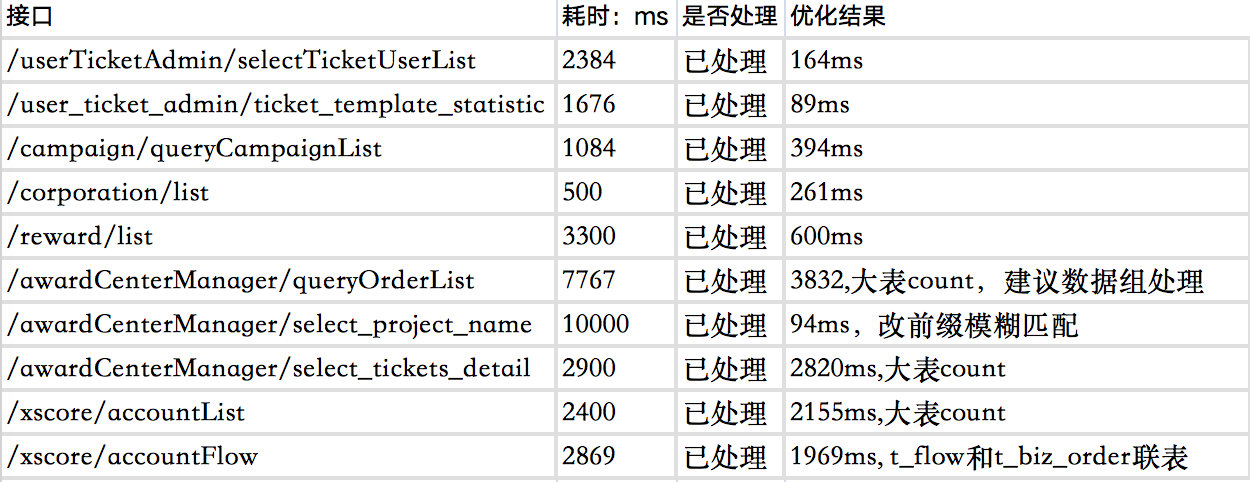
针对于本次集中优化的效果很明显,接口用时降低50%-90%,效果显著。
发现问题
系统在上线之前压测也没问题,刚上线的时候运行良好,这不代表以后就没问题了。尤其对于数据密集型系统随着数据量的增加,导致需要处理数据库的操作用时逐渐增加,增加接口耗时。系统接口可接入监控并对出现的问题进行告警(我们用的是promethus+grafana),主动发现问题,而不是靠反馈。我们的系统在运行一段时间后出现部分接口耗时增加的问题,根据业务方的反馈和我们自己监控的数据专门提了一个需求,有我负责解决,目标是业务接口 500ms 以内,管理端接口 1s 以内。
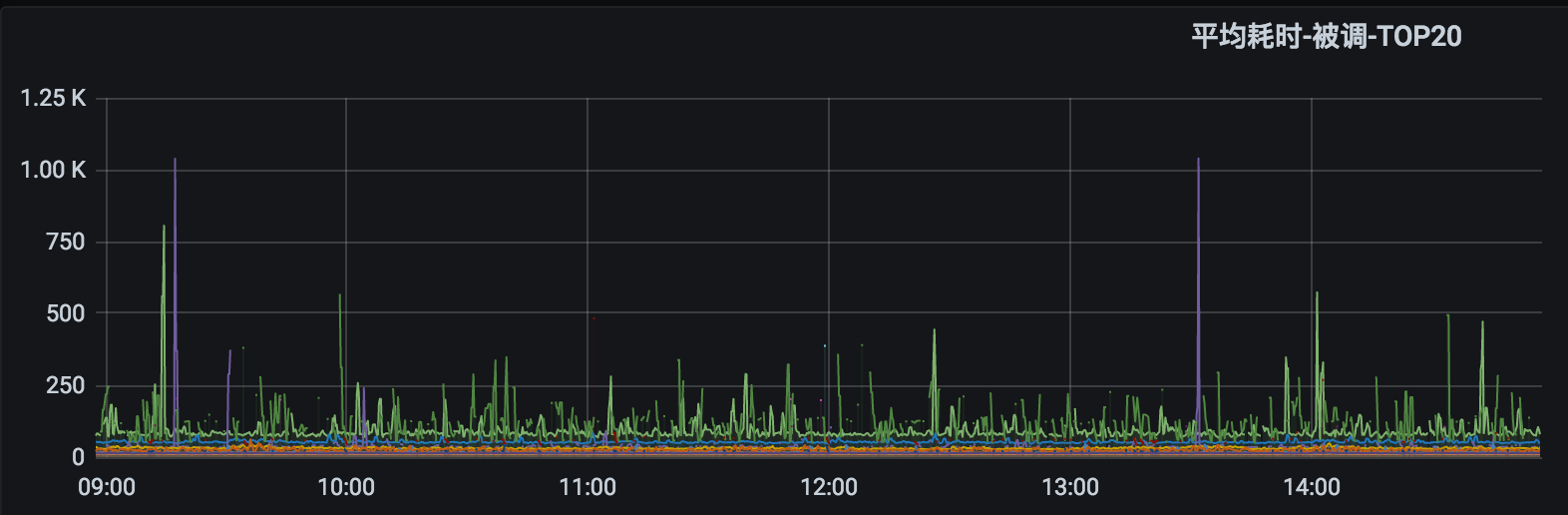
下图是被调最多的20个接口的耗时:
下图是接口调用超过1秒的:
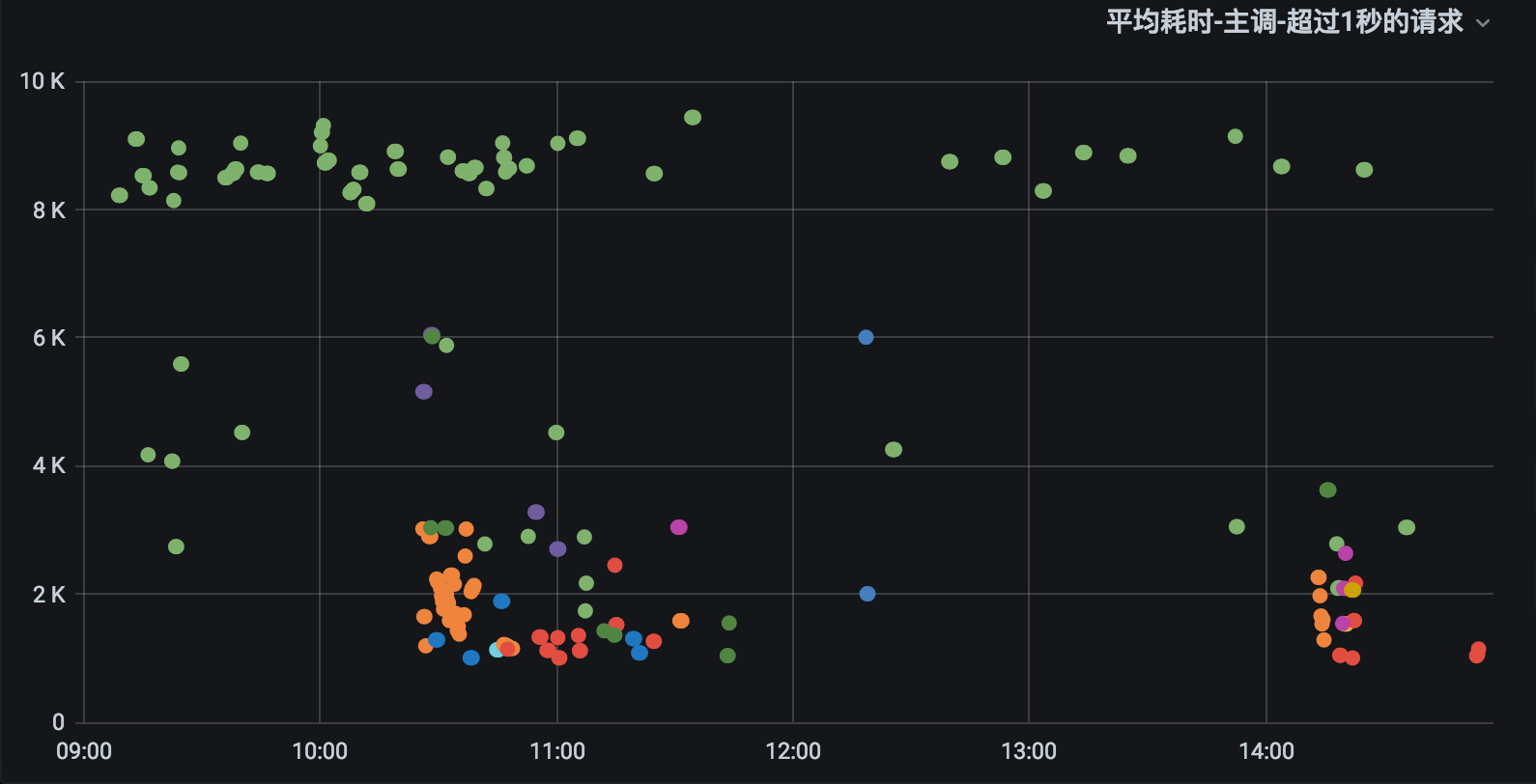
我们可以针对缓慢的接口抽出人力专门进行优化处理。
优化的方向我总结可分为下面3种:
代码优化
对于代码的逻辑的优化很重要,无效的逻辑会占用大量内存和时间,优化的效果也是最明显的。
比如有个管理端接口负责本地数据的导入,里面有一段代码如下:
List<String> ids = readFromFile(path);
List<String> idList = new ArrayList<>(new HashSet<>(ids));
for (String d : idList) {
// 业务代码
}
可以看到这段代码的目的是想把从文件里读取到的 id 进行去重,先存在 list,然后在 HashSet 里进行去重,然后再转到list。那么可以直接让 readFromFile(path) 返回 Set ,再进行遍历,避免几次复制数据导致的 OutOfMemoryError 错误。
我们对用户的身份信息进行加密,那么接口调用查询的时候需要进行调用解密服务获取真正的账号信息,然后再返回给前端查看。这个是基本流程,在管理端有个查询用户列表的接口同样是按照这个流程做的,但是仔细分析就会发现列表并不需要展示的用户身份信息,对于一页20条数据来说可以减少80%的响应时间。
代码层的优化尤其是设计到具体业务的优化是很困难的,需要在理解业务流程的基础上进行,但是效果是立竿见影的。当然对于一些小的改动可能并不会有多少效果。
如何避免代码层面的问题呢?一个有效的办法就是codeReview,leader和其他组员共同审核,可以避免大部分类似第一种出现的问题。
缓存优化
对于多年开发经验的老鸟来说可能代码层面的优化并不多,那么缓存的优化就很重要。如果需要缓存的数据比较少且不会再变动,那么内存级的缓存是合适的。若果数据量较大或者数据可能会发生变动,那么服务级的缓存是合适的。
本地缓存
本地缓存是指数据缓存在本地内存,只能进程自己使用,不能被其他进程或服务访问。对于具体的实现可以使用谷歌提供的guava库里的Cache,也可以自己的缓存(最好是基于 LRU 的固定大小的缓存,避免因为预估不准或者其他问题导致的缓存过大,影响服务的稳定性)。
这种缓存的应用场景是有限的,必须满足:
- 数据量不大。一般服务是要限制内存的占用大小,如果缓存的数据量过大导致服务内存不够用,频繁GC,影响服务本身的稳定性。
- 数据不会变化或者可以容忍数据没有实时更新。对于横向扩展的服务,内存级缓存是无法实时更新其他服务对于数据的修改的,因此缓存的数据最好不好再变化。假如可以容忍修改的数据30分钟后再生效,那么可以定时重新加载数据。
根据业务的实际应用场景选择合适的缓存。比如查询抽奖 / 返现的配置信息在管理端配置后可以容忍变更后有5分钟的时间差,非常适合这种缓存。比如营销里发放的卡券,配置信息在管理端配置后是不会再变更的,而且可以使用的卡券也不会很多,非常适合这种缓存。
服务级缓存
服务级缓存是指专门为处理缓存而设计的服务或集群,可以是 Redis / Memcache,针对于内存级缓存不适用的场景都可以用。用户在查询信息的先查询缓存的数据,查到了直接返回。没查到则通过数据库查询,然后更新到缓存。比如app首页需要查询用户所属渠道的配置信息,
数据库优化
对于数据的优化网上的文章很多,我只写我认为最重要的两点。
一、MySQL 不应该把它看作一个整体。
MySQL 分为是 Server 层 和 引擎层,就像两个微服务一样。这样看的话就很好理解一些问题,比如 count(*), count(primary_key), count(field_id), count(1) 操作的响应速度比较。操作是server层
二、索引优化
添加索引是数据库优化中常用的一种操作, 但是在添加索引时应该认真思考是否可以使用联合索引,索引本身也是数据,也会占用空间,而且更新数据的时候也需要同步更新,增加数据库的负担。
联合索引:比如在业务中需要查询订单号和订单状态,但是不会单独查订单状态,这时就可以使用订单id加订单状态的联合索引。
回表的问题:在查询时如果需要返回的字段不在索引中会出现回表的问题,少量的数据没问题,应避免查询大量的数据中产生的回表问题,会降低优化的效果。
其他优化
如果上面的策略都无法解决问题,可以看下面的两种方式:
业务调整
既然解决不了问题,那就看能不能把造成这个问题的需求调整下。比如上面的 /awardCenterManager/select_project_name 接口需要对活动名称进行模糊查询,然后统计订单。因为需要对活动名称字段进行模糊匹配 '%name%',这种前后都模糊的查询是无法使用索引的,跟产品讨论后改成 'name%' 这种前缀固定的查询,直接由原来的 10 秒减少到 94ms,当然还有其他方面的优化。效果很明显。
换数据库
对于像订单表这中亿级数据量的大表在统计数据时是无法通过优化解决的。比如上表中的 /awardCenterManager/queryOrderList 接口需要统计 count(),随着表数据的增加接口肯定会越来越慢,这是无法在 mysql 中解决的,那么可以把数据迁移到 ElasticSearch 中,查询由 ES 提供,才能从根本上解决这个问题。
以上是我优化服务的一些经验总结,希望对你有所帮助。