Python内存管理
内存是宝贵的,Python编程中一般无须关心变量的存亡,一般也不关心内存的管理,Python引用计数记录所有对象的引用数,当对象引用数为0时,它就被垃圾回收GC。
Python查看引用计数
1 import sys 2 print(sys.getrefcount([])) 3 x = [] 4 print(sys.getrefcount(x)) 5 y = x 6 print(sys.getrefcount(x)) 7 z = y 8 print(sys.getrefcount(x))
随机数
random模块
1 import random 2 print([random.randint(1, 5) for i in range(20)]) # randint随机在[1,5]区间内获取一个整数。 3 print([random.randrange(1, 5, 2) for i in range(20)]) # randrange随机在[1,5)区间内步频2里获取一个整数。 4 ls = list(range(1, 10, 2)) 5 print([random.choice(ls) for i in range(20)]) # choice随机在一个可迭代对象里获取一个随机元素。 6 print(random.choices(ls, k=20, weights=(1, 1, 1, 1, 10))) # choices随机在一个可迭代对象重复获取k个元素,可设置权重weights。 7 random.shuffle(ls) # shuffle就地打乱列表元素 8 print(ls) 9 print(random.sample(ls, 3)) # sample随机获取可迭代对象内不重复的若干个元素。
列表list()
Python中list()用顺序表实现
list()中各个个体称作元素
元素可以是任意类型对象
列表内元素有序,可以使用索引
线性的结构
使用'[ ]'表示
列表是可变的
初始化:
1 ls1 = []
2 ls2 = list()
3 ls3 = [1, '2', [3, 'a'], (4, 5)]
4 ls4 = list(range(5))
索引
索引也叫下标,正索引从左到右从0开始数起,负索引从右到左从-1开始数起。索引不可超界,否则报错。
增
1 ls = [1]
2 print(ls)
3 ls = [1] + [2] # 列表拼接
4 print(ls)
5 ls.append(3) # 在尾部增加一个元素
6 print(ls)
7 ls.extend([4, 5]) # 在尾部增加多个元素
8 print(ls)
9 ls.insert(3, 6) # 在索引3前插入元素6,如果超过索引范围则在头或尾插入元素(不推荐使用)
10 print(ls)
11 ls = ls * 2 # 列表重复n次拼接
12 print(ls)
删
1 ls = list(range(2, 11, 2)) # 定义2-10偶数列表
2 print(ls) # [2, 4, 6, 8, 10]
3 ls.remove(4) # 删除从左到右第一个指定value的元素
4 print(ls) # [2, 6, 8, 10]
5 ls.pop(1) # 删除指定index的元素
6 print(ls) # [2, 8, 10]
7 ls.pop() # 没有指定index,删除最后一个元素(推荐使用)
8 print(ls) # [2, 8]
9 ls.clear() # 清空列表元素
10 print(ls) # []
改
1 a = [1, 2, 3]
2 a[2] = 5 # 把索引2的元素改为5
查
1 ls = [1, 2, 3]
2 print(ls[1]) # 通过索引查找元素
3 print(ls.index(2)) # 通过元素查找索引
4 print(ls.count(3)) # 通过元素查找出现次数
5 print(len(ls)) # 返回列表长度
注意
浅拷贝和深拷贝的区别
1 import copy
2 ls = [1, 2, [3, 4]]
3 ls1 = copy.copy(ls)
4 ls2 = copy.deepcopy(ls)
5 ls3 = ls.copy()
6 print(ls, ls1, ls2, ls3)
7 ls[2][1] = 100
8 print(ls, ls1, ls2, ls3)
Python在普通的拷贝中使用浅拷贝,仅仅拷贝一个引用地址,如果修改原始列表里面元素是列表的里面的内容,普通的拷贝会导致后面赋值的新列表会跟着改动,如需进行深拷贝,可使用copy.deepcopy()方法。
线性数据结构
是一组有序的元素的抽象,它由0个或有限个组成。
常见的线性结构有:
顺序表:用一块连续的存储空间有序分布,比如一条排队购票的队伍,可以插队,离队,可以被索引。
链接表:在存储空间分散分布,但是相邻元素有关联地链接起来,比如操场上手拉手随意站着的小朋友,也可以插队,离队,可以被索引。
栈Stack:后进先出,好像从下往上叠放的碟子,最后放上去的最先被拿起。
队列Queue:先进先出,好像一条站在闸道排队购票的队伍,不能插队离队,先排队的先购票。
元组tuple
一个有序的元素组成的集合,使用小括号()表示,不可变对象。
初始化
1 t1 = () 2 t2 = (1,) 3 t3 = (1,)*2 4 t4 = (1, 2) 5 t5 = 1, 2 6 t6 = tuple() 7 t7 = tuple(range(5)) 8 t8 = tuple([1, 2])
索引与增删改查
索引与查跟列表list一样。
因元组是不可变对象,无法实现增删改。
冒泡排序
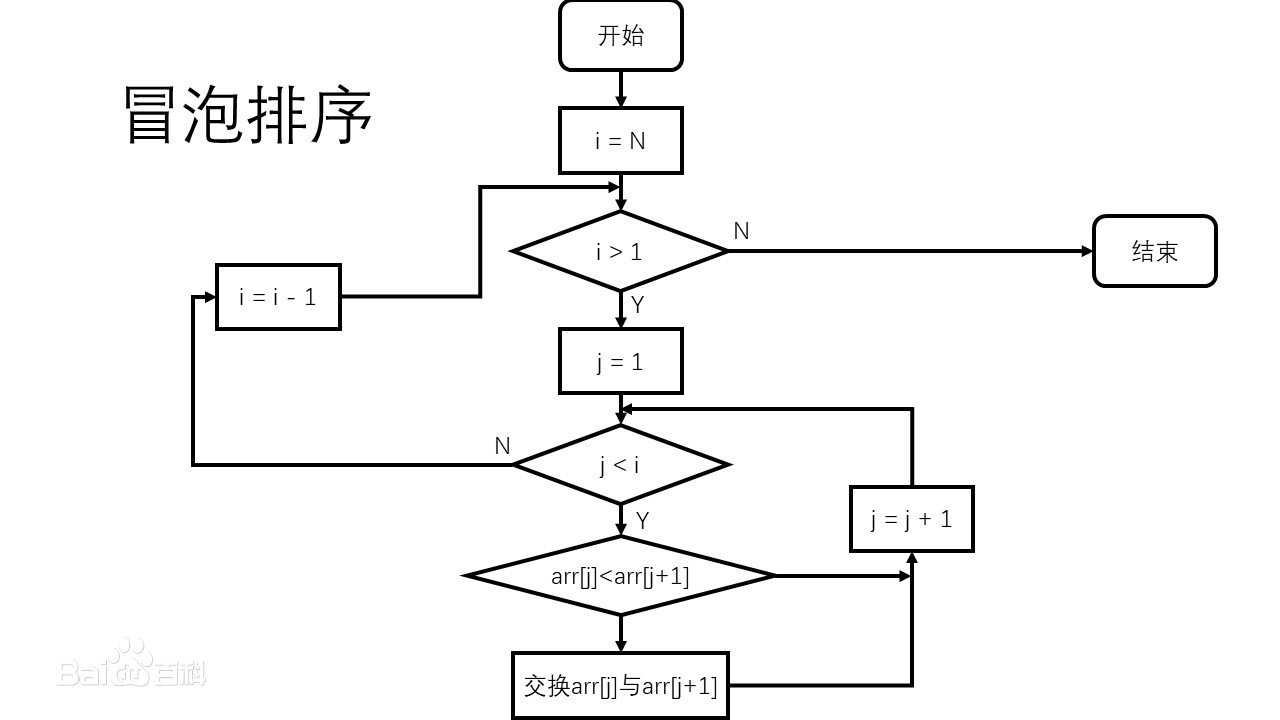
1 import random 2 arr = random.choices(range(1, 101), k=20) 3 print(arr) 4 for i in range(len(arr)-1, 0, -1): 5 flag = False 6 for j in range(0, i): 7 if arr[j] > arr[j+1]: 8 arr[j], arr[j+1] = arr[j+1], arr[j] 9 flag = True 10 if not flag: 11 break 12 print(arr)
总结
时间复杂度O(n²),不是最优的排序算法。
字符串
一个个字符组成的有序的序列,是字符的集合。
使用单引号,双引号,三引号引住的字符序列。
字符串是不可变对象,是字面常量。
Python3起字符串都是Unicode类型。
初始化
1 s1 = '"' 2 s2 = "'" 3 s3 = '''a 4 b''' 5 s4 = """c 6 d""" 7 s5 = r' ' 8 s6 = R' ' 9 s7 = f'{s1}and{s2}'
增删改查与索引
和元组一样可索引可查找,不可修改。
拼接
1 s1, s2 = 'abc', 'def' 2 s3 = s1+s2 # s1与s2拼接起来生成一个全新的字符串 3 s4 = '!'.join(map(str, range(5))) # join用'!'(可替换)作为分隔符拼接起来重新生成一个全新的字符串
字符查找
1 s1 = 'abcdef' 2 print(s1.find('cd', 1, 4)) # 从左向右查找返回查找字符的正索引,没有找到返回-1,可设置启示结尾的索引,可超界。 3 print(s1.rfind('g', -100, 200)) # 从右向左查找返回查找字符的正索引,没有找到返回-1,可设置启示结尾的索引,可超界。
分割
s1 = ' ab cd ef ' print(s1.split('c')) # 从左向右按指定字符切割,可指定切割次数在,返回列表。 print(s1.rsplit(' ', 1)) # 从右向左按指定字符切割,可指定切割次数,返回列表。 print(s1.splitlines()) # 按换行符切割,返回列表。 print(s1.partition(' ')) # 从左向右按指定字符切割,返回3个元素列表,没有指定的切割字符会返回空字符串。 print(s1.rpartition('g')) # 从右向左按指定字符切割,返回3个元素列表,没有指定的切割字符会返回空字符串。
替换
1 s1 = 'https://www.baidu.com/' 2 print(s1.replace('w', 'm', 2)) # 把从左到右2个'w'改成'm'
移除
1 s1 = ' abcd ' 2 print(s1.strip()) # 不填参数移除两头空白字符,可指定移除字符 3 print(s1.lstrip()) # 不填参数移除左边空白字符,可指定移除字符 4 print(s1.rstrip('d c')) # 不填参数移除右边空白字符,可指定移除字符
首尾判断
1 s1 = 'abcdefg' 2 print(s1.startswith('bc', 1)) # 判断字符开头是否为参数字符,可设置区间,返回True或False,高效率。 3 print(s1.endswith('ef', 1, -1)) # 判断字符结尾是否为参数字符,可设置区间,返回True或False,高效率。
其它函数
1 s1 = 'aBcDeFg' 2 print(s1.upper()) # 切换大写。 3 print(s1.lower()) # 切换小写。 4 print(s1.swapcase()) # 大小写相互切换。 5 print('aB1'.isalnum()) # 判断是否为字母数字,返回True或False。 6 print(s1.isalpha()) # 判断是否为字母,返回True或False。 7 print('123'.isdecimal()) # 判断是否为十进制,返回True或False。 8 print('123'.isdigit()) # 判断是否为数字0-9,返回True或False。 9 print('_asd_123'.isidentifier()) # 判断是否为有效标识符(下划线数字字母,非数字开头),返回True或False。 10 print('asd'.islower()) # 判断是否为小写字母,返回True或False。 11 print('三'.isnumeric()) # 判断是否为数字(包括阿拉伯数字,罗马数字,中文数字),返回True或False。 12 print('123!@#asd/t/n/r'.isprintable()) # 判断是否可打印,返回True或False。 13 print(' '.isspace()) # 判断是否空白字符,返回True或False。 14 print('Abc Ef'.istitle()) # 判断字符串单词是否首字母大写后面小写,返回True或False。 15 print('ABC'.isupper()) # 判断是否为大写字母,返回True或False。
格式化
已一定格式拼接字符串,'+'和‘join'也算简单的格式化。
C风格
内建文档Built-in Types中printf-style String Formatting有详细定义
占位符:%和格式字符,如%s、%d。
| Conversion | Meaning | Notes |
|---|---|---|
'd' |
Signed integer decimal. | |
'i' |
Signed integer decimal. | |
'o' |
Signed octal value. | (1) |
'u' |
Obsolete type – it is identical to 'd'. |
(6) |
'x' |
Signed hexadecimal (lowercase). | (2) |
'X' |
Signed hexadecimal (uppercase). | (2) |
'e' |
Floating point exponential format (lowercase). | (3) |
'E' |
Floating point exponential format (uppercase). | (3) |
'f' |
Floating point decimal format. | (3) |
'F' |
Floating point decimal format. | (3) |
'g' |
Floating point format. Uses lowercase exponential format if exponent is less than -4 or not less than precision, decimal format otherwise. | (4) |
'G' |
Floating point format. Uses uppercase exponential format if exponent is less than -4 or not less than precision, decimal format otherwise. | (4) |
'c' |
Single character (accepts integer or single character string). | |
'r' |
String (converts any Python object using repr()). |
(5) |
's' |
String (converts any Python object using str()). |
(5) |
'a' |
String (converts any Python object using ascii()). |
(5) |
'%' |
No argument is converted, results in a '%' character in the result. |
修饰符:在占位符中插入修饰符,如%03d.
| Flag | Meaning |
|---|---|
'#' |
The value conversion will use the “alternate form” (where defined below). |
'0' |
The conversion will be zero padded for numeric values. |
'-' |
The converted value is left adjusted (overrides the '0' conversion if both are given). |
' ' |
(a space) A blank should be left before a positive number (or empty string) produced by a signed conversion. |
'+' |
A sign character ('+' or '-') will precede the conversion (overrides a “space” flag). |
1 print('%s @@@ %03d @@ %0.2f' % ('asd', 3, 0.125)) # asd @@@ 003 @@ 0.12 2 print('%(a)s @@@ %(b)s' % {'b': 'asd', 'a': '123'}) # 123 @@@ asd
format函数
推荐使用的格式化函数
str.format(*args, **kwargs)-
Perform a string formatting operation. The string on which this method is called can contain literal text or replacement fields delimited by braces
{}. Each replacement field contains either the numeric index of a positional argument, or the name of a keyword argument. Returns a copy of the string where each replacement field is replaced with the string value of the corresponding argument.>>> "The sum of 1 + 2 is {0}".format(1+2) 'The sum of 1 + 2 is 3'See Format String Syntax for a description of the various formatting options that can be specified in format strings.
Note
When formatting a number (
int,float,complex,decimal.Decimaland subclasses) with thentype (ex:'{:n}'.format(1234)), the function temporarily sets theLC_CTYPElocale to theLC_NUMERIClocale to decodedecimal_pointandthousands_sepfields oflocaleconv()if they are non-ASCII or longer than 1 byte, and theLC_NUMERIClocale is different than theLC_CTYPElocale. This temporary change affects other threads.Changed in version 3.6.5: When formatting a number with the
ntype, the function sets temporarily theLC_CTYPElocale to theLC_NUMERIClocale in some cases.
1 import math 2 p = math.pi 3 # 对应位置 4 print('{}n{}'.format('a', 'd')) # and 5 print('{a}{1}{0}'.format('d', 'n', a='a')) # and 6 print('{0[0]}{0[1]}'.format(('o', 'r'))) # or 7 print('{0:d},{0:b},{0:o},{0:x},{0:#X}'.format(31)) # 31,11111,37,1f,0X1F(进制) 8 # 浮点数 9 print('{}'.format(p)) # 3.141592653589793 10 print('{:f}'.format(p)) # 3.141593 (精度默认6) 11 print('{:10f}'.format(p)) # 3.141593(设置右对齐宽度10) 12 print('{:2f}'.format(p)) # 3.141593(设置宽度太少会溢出) 13 print('{:.2f}'.format(p)) # 3.14(精确度2位小数) 14 print('{:5.2f}'.format(p)) # 3.14(精确度2位小数,右对齐宽度5) 15 print('{:10.2%}'.format(p)) # 314.16% 16 # 对齐 17 print('{}*{}={}'.format(5, 8, 40)) # 5*8=40 18 print('{}*{}={:#>5}'.format(5, 8, 40)) # 5*8=###40(右对齐宽度5补'#') 19 print('{}*{}={:$<5}'.format(5, 8, 40)) # 5*8=40$$$(左对齐宽度5补'$') 20 print('{}*{}={:^5}'.format(5, 8, 40)) # 5*8=@40@@(居中对齐宽度5补' ')
字节序列
编码与解码
编码:str转bytes,使用encode指定字符集转为bytes。
解码:bytes转str,使用decode指定字符集转为字符串。
1 print('B啊'.encode()) # b'Bxe5x95x8a',缺省utf8 2 print(b'xb0xa1'.decode('gbk')) # 啊,缺省utf8
ASCII
美国信息交换标准代码,是基于拉丁字母的一套电脑编码系统。
|
Bin
(二进制)
|
Oct
(八进制)
|
Dec
(十进制)
|
Hex
(十六进制)
|
缩写/字符
|
解释
|
|
0000 0000
|
00
|
0
|
0x00
|
NUL(null)
|
空字符
|
|
0000 0001
|
01
|
1
|
0x01
|
SOH(start of headline)
|
标题开始
|
|
0000 0010
|
02
|
2
|
0x02
|
STX (start of text)
|
正文开始
|
|
0000 0011
|
03
|
3
|
0x03
|
ETX (end of text)
|
正文结束
|
|
0000 0100
|
04
|
4
|
0x04
|
EOT (end of transmission)
|
传输结束
|
|
0000 0101
|
05
|
5
|
0x05
|
ENQ (enquiry)
|
请求
|
|
0000 0110
|
06
|
6
|
0x06
|
ACK (acknowledge)
|
收到通知
|
|
0000 0111
|
07
|
7
|
0x07
|
BEL (bell)
|
响铃
|
|
0000 1000
|
010
|
8
|
0x08
|
BS (backspace)
|
退格
|
|
0000 1001
|
011
|
9
|
0x09
|
HT (horizontal tab)
|
水平制表符
|
|
0000 1010
|
012
|
10
|
0x0A
|
LF (NL line feed, new line)
|
换行键
|
|
0000 1011
|
013
|
11
|
0x0B
|
VT (vertical tab)
|
垂直制表符
|
|
0000 1100
|
014
|
12
|
0x0C
|
FF (NP form feed, new page)
|
换页键
|
|
0000 1101
|
015
|
13
|
0x0D
|
CR (carriage return)
|
回车键
|
|
0000 1110
|
016
|
14
|
0x0E
|
SO (shift out)
|
不用切换
|
|
0000 1111
|
017
|
15
|
0x0F
|
SI (shift in)
|
启用切换
|
|
0001 0000
|
020
|
16
|
0x10
|
DLE (data link escape)
|
数据链路转义
|
|
0001 0001
|
021
|
17
|
0x11
|
DC1 (device control 1)
|
设备控制1
|
|
0001 0010
|
022
|
18
|
0x12
|
DC2 (device control 2)
|
设备控制2
|
|
0001 0011
|
023
|
19
|
0x13
|
DC3 (device control 3)
|
设备控制3
|
|
0001 0100
|
024
|
20
|
0x14
|
DC4 (device control 4)
|
设备控制4
|
|
0001 0101
|
025
|
21
|
0x15
|
NAK (negative acknowledge)
|
拒绝接收
|
|
0001 0110
|
026
|
22
|
0x16
|
SYN (synchronous idle)
|
同步空闲
|
|
0001 0111
|
027
|
23
|
0x17
|
ETB (end of trans. block)
|
结束传输块
|
|
0001 1000
|
030
|
24
|
0x18
|
CAN (cancel)
|
取消
|
|
0001 1001
|
031
|
25
|
0x19
|
EM (end of medium)
|
媒介结束
|
|
0001 1010
|
032
|
26
|
0x1A
|
SUB (substitute)
|
代替
|
|
0001 1011
|
033
|
27
|
0x1B
|
ESC (escape)
|
换码(溢出)
|
|
0001 1100
|
034
|
28
|
0x1C
|
FS (file separator)
|
文件分隔符
|
|
0001 1101
|
035
|
29
|
0x1D
|
GS (group separator)
|
分组符
|
|
0001 1110
|
036
|
30
|
0x1E
|
RS (record separator)
|
记录分隔符
|
|
0001 1111
|
037
|
31
|
0x1F
|
US (unit separator)
|
单元分隔符
|
|
0010 0000
|
040
|
32
|
0x20
|
(space)
|
空格
|
|
0010 0001
|
041
|
33
|
0x21
|
!
|
叹号 |
|
0010 0010
|
042
|
34
|
0x22
|
"
|
双引号 |
|
0010 0011
|
043
|
35
|
0x23
|
#
|
井号 |
|
0010 0100
|
044
|
36
|
0x24
|
$
|
美元符 |
|
0010 0101
|
045
|
37
|
0x25
|
%
|
百分号 |
|
0010 0110
|
046
|
38
|
0x26
|
&
|
和号 |
|
0010 0111
|
047
|
39
|
0x27
|
'
|
闭单引号 |
|
0010 1000
|
050
|
40
|
0x28
|
(
|
开括号
|
|
0010 1001
|
051
|
41
|
0x29
|
)
|
闭括号
|
|
0010 1010
|
052
|
42
|
0x2A
|
*
|
星号 |
|
0010 1011
|
053
|
43
|
0x2B
|
+
|
加号 |
|
0010 1100
|
054
|
44
|
0x2C
|
,
|
逗号 |
|
0010 1101
|
055
|
45
|
0x2D
|
-
|
减号/破折号 |
|
0010 1110
|
056
|
46
|
0x2E
|
.
|
句号 |
|
0010 1111
|
057
|
47
|
0x2F
|
/
|
斜杠 |
|
0011 0000
|
060
|
48
|
0x30
|
0
|
字符0 |
|
0011 0001
|
061
|
49
|
0x31
|
1
|
字符1 |
|
0011 0010
|
062
|
50
|
0x32
|
2
|
字符2 |
|
0011 0011
|
063
|
51
|
0x33
|
3
|
字符3 |
|
0011 0100
|
064
|
52
|
0x34
|
4
|
字符4 |
|
0011 0101
|
065
|
53
|
0x35
|
5
|
字符5 |
|
0011 0110
|
066
|
54
|
0x36
|
6
|
字符6 |
|
0011 0111
|
067
|
55
|
0x37
|
7
|
字符7 |
|
0011 1000
|
070
|
56
|
0x38
|
8
|
字符8 |
|
0011 1001
|
071
|
57
|
0x39
|
9
|
字符9 |
|
0011 1010
|
072
|
58
|
0x3A
|
:
|
冒号 |
|
0011 1011
|
073
|
59
|
0x3B
|
;
|
分号 |
|
0011 1100
|
074
|
60
|
0x3C
|
<
|
小于 |
|
0011 1101
|
075
|
61
|
0x3D
|
=
|
等号 |
|
0011 1110
|
076
|
62
|
0x3E
|
>
|
大于 |
|
0011 1111
|
077
|
63
|
0x3F
|
?
|
问号 |
|
0100 0000
|
0100
|
64
|
0x40
|
@
|
电子邮件符号 |
|
0100 0001
|
0101
|
65
|
0x41
|
A
|
大写字母A |
|
0100 0010
|
0102
|
66
|
0x42
|
B
|
大写字母B |
|
0100 0011
|
0103
|
67
|
0x43
|
C
|
大写字母C |
|
0100 0100
|
0104
|
68
|
0x44
|
D
|
大写字母D |
|
0100 0101
|
0105
|
69
|
0x45
|
E
|
大写字母E |
|
0100 0110
|
0106
|
70
|
0x46
|
F
|
大写字母F |
|
0100 0111
|
0107
|
71
|
0x47
|
G
|
大写字母G |
|
0100 1000
|
0110
|
72
|
0x48
|
H
|
大写字母H |
|
0100 1001
|
0111
|
73
|
0x49
|
I
|
大写字母I |
|
01001010
|
0112
|
74
|
0x4A
|
J
|
大写字母J |
|
0100 1011
|
0113
|
75
|
0x4B
|
K
|
大写字母K |
|
0100 1100
|
0114
|
76
|
0x4C
|
L
|
大写字母L |
|
0100 1101
|
0115
|
77
|
0x4D
|
M
|
大写字母M |
|
0100 1110
|
0116
|
78
|
0x4E
|
N
|
大写字母N |
|
0100 1111
|
0117
|
79
|
0x4F
|
O
|
大写字母O |
|
0101 0000
|
0120
|
80
|
0x50
|
P
|
大写字母P |
|
0101 0001
|
0121
|
81
|
0x51
|
Q
|
大写字母Q |
|
0101 0010
|
0122
|
82
|
0x52
|
R
|
大写字母R |
|
0101 0011
|
0123
|
83
|
0x53
|
S
|
大写字母S |
|
0101 0100
|
0124
|
84
|
0x54
|
T
|
大写字母T |
|
0101 0101
|
0125
|
85
|
0x55
|
U
|
大写字母U |
|
0101 0110
|
0126
|
86
|
0x56
|
V
|
大写字母V |
|
0101 0111
|
0127
|
87
|
0x57
|
W
|
大写字母W |
|
0101 1000
|
0130
|
88
|
0x58
|
X
|
大写字母X |
|
0101 1001
|
0131
|
89
|
0x59
|
Y
|
大写字母Y |
|
0101 1010
|
0132
|
90
|
0x5A
|
Z
|
大写字母Z |
|
0101 1011
|
0133
|
91
|
0x5B
|
[
|
开方括号 |
|
0101 1100
|
0134
|
92
|
0x5C
|
反斜杠 | |
|
0101 1101
|
0135
|
93
|
0x5D
|
]
|
闭方括号 |
|
0101 1110
|
0136
|
94
|
0x5E
|
^
|
脱字符 |
|
0101 1111
|
0137
|
95
|
0x5F
|
_
|
下划线 |
|
0110 0000
|
0140
|
96
|
0x60
|
`
|
开单引号 |
|
0110 0001
|
0141
|
97
|
0x61
|
a
|
小写字母a |
|
0110 0010
|
0142
|
98
|
0x62
|
b
|
小写字母b |
|
0110 0011
|
0143
|
99
|
0x63
|
c
|
小写字母c |
|
0110 0100
|
0144
|
100
|
0x64
|
d
|
小写字母d |
|
0110 0101
|
0145
|
101
|
0x65
|
e
|
小写字母e |
|
0110 0110
|
0146
|
102
|
0x66
|
f
|
小写字母f |
|
0110 0111
|
0147
|
103
|
0x67
|
g
|
小写字母g |
|
0110 1000
|
0150
|
104
|
0x68
|
h
|
小写字母h |
|
0110 1001
|
0151
|
105
|
0x69
|
i
|
小写字母i |
|
0110 1010
|
0152
|
106
|
0x6A
|
j
|
小写字母j |
|
0110 1011
|
0153
|
107
|
0x6B
|
k
|
小写字母k |
|
0110 1100
|
0154
|
108
|
0x6C
|
l
|
小写字母l |
|
0110 1101
|
0155
|
109
|
0x6D
|
m
|
小写字母m |
|
0110 1110
|
0156
|
110
|
0x6E
|
n
|
小写字母n |
|
0110 1111
|
0157
|
111
|
0x6F
|
o
|
小写字母o |
|
0111 0000
|
0160
|
112
|
0x70
|
p
|
小写字母p |
|
0111 0001
|
0161
|
113
|
0x71
|
q
|
小写字母q |
|
0111 0010
|
0162
|
114
|
0x72
|
r
|
小写字母r |
|
0111 0011
|
0163
|
115
|
0x73
|
s
|
小写字母s |
|
0111 0100
|
0164
|
116
|
0x74
|
t
|
小写字母t |
|
0111 0101
|
0165
|
117
|
0x75
|
u
|
小写字母u |
|
0111 0110
|
0166
|
118
|
0x76
|
v
|
小写字母v |
|
0111 0111
|
0167
|
119
|
0x77
|
w
|
小写字母w |
|
0111 1000
|
0170
|
120
|
0x78
|
x
|
小写字母x |
|
0111 1001
|
0171
|
121
|
0x79
|
y
|
小写字母y |
|
0111 1010
|
0172
|
122
|
0x7A
|
z
|
小写字母z |
|
0111 1011
|
0173
|
123
|
0x7B
|
{
|
开花括号 |
|
0111 1100
|
0174
|
124
|
0x7C
|
|
|
垂线 |
|
0111 1101
|
0175
|
125
|
0x7D
|
}
|
闭花括号 |
|
0111 1110
|
0176
|
126
|
0x7E
|
~
|
波浪号 |
|
0111 1111
|
0177
|
127
|
0x7F
|
DEL (delete)
|
删除
|
重点记:0x00:NULL
0x09:制表符
0x0a: (换行符)
0x0d: (回车换行)
0x30:0(48)
0x31:1(49)
0x41:A(65)
0x61:a(97)
字节序列
Python3引入两个新的类型bytes、bytearray。
bytes为不可变字节序列,bytearray是可变字节数组。
bytes初始化
1 b = bytes() # 定义一个空字节序 2 print(b) # b'' 3 b = bytes(3) # 初始化若干个空的字节序 4 print(b) # b'x00x00x00' 5 b = bytes(range(48, 58)) # 放入迭代器可生成一组字节序 6 print(b) # b'0123456789' 7 b = bytes(b'0123456789') # 生成一组新的bytes 8 print(b) # b'0123456789'
bytes索引与增删改查
bytes是不可变字节序列,不可改,不可增加,可以生成新的序列,可被索引、查找,删除,操作方法类似str字符类型。
还没有bytes对象的时候,用bytes.fromhex()构造字节序列。可用bytes.hex()转为十六进制表示。
bytearray初始化
跟bytes初始化类似,生成的是bytearray可变字节数组。
bytearray索引与增删改查
bytearray是可变字节数组,可索引,可增删改查,操作方法类似lits列表类型。
字节序
内存中对于一个超过1字节的数据的分布方式。
Big-endian大端模式,尾巴往后放的。
Little-endian小端模式,尾巴放在低地址端,靠前倒序的。
Intel X86 CPU、Window、Linux使用小端模式,网络传输、Mac OS、Java虚拟机使用大端模式。
int和bytes转换
1 a = int.from_bytes(b'abc', 'big') 2 print(a, hex(a)) # 6382179 0x616263 3 a = int.from_bytes(b'abc', 'little') 4 print(a, hex(a)) # 6513249 0x636261 5 print(a.to_bytes(4, 'big')) # b'x00cba'(设置字节长度为4) 6 print(a.to_bytes(4, 'little')) # b'abcx00'(设置字节长度为4)
切片
可迭代,能被索引的均可切片。
sequence[start:stop:step],均可缺省。
本质相当于copy,可切片赋值。
1 ls = list(range(10)) 2 print(ls[:]) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] 3 print(ls[2:]) # [2, 3, 4, 5, 6, 7, 8, 9] 4 print(ls[-2:]) # [8, 9] 5 print(ls[:2]) # [0, 1] 6 print(ls[:-2]) # [0, 1, 2, 3, 4, 5, 6, 7] 7 print(ls[2:7]) # [2, 3, 4, 5, 6] 8 print(ls[-7:-2]) # [3, 4, 5, 6, 7] 9 print(ls[::2]) # [0, 2, 4, 6, 8] 10 print(ls[::-1]) # [9, 8, 7, 6, 5, 4, 3, 2, 1, 0] 11 ls[-1:-3:-1] = (100, 200) 12 print(ls) # [0, 1, 2, 3, 4, 5, 6, 7, 200, 100]