本次作业的要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339
前言
本次作业是在《爬虫大作业》的基础上进行的,在《爬虫大作业》中,我主要对拉勾网python岗位的招聘信息进行的数据爬取,最终得到了2641条数据存在一个名为lagoupy.xls中。本次作业的任务主要有以下三点:
1.对CSV文件进行预处理生成无标题文本文件,将爬虫大作业产生的csv文件上传到HDFS
2.把hdfs中的文本文件最终导入到数据仓库Hive中,在Hive中查看并分析数据
3.用Hive对爬虫大作业产生的进行数据分析(10条以上的查询分析)
数据预处理
由于我们爬取下来的数据并不是全部都是我们所要的,或者是有一些数据需要进行加工才可以用到,这时候数据的预处理就必不可少了,原始的数据如下图所示。

1.删除重复值
如果数据中存在重复记录, 而且重复数量较多时, 势必会对结果造成影响, 因此我们应当首先处理重复值。打开lagoupy.xls文件,选中岗位id这一列数据,选择数据——>删除重复值,对重复值进行删除,删除重复值后,我们可以发现,数据从原来的2641条变成2545条。
2.过滤无效数据
由于某些数据对我们的数据分析并无用处,所以对于这一部分数据我们可以不要,在这里发布时间是无效数据,所以我们可以直接删除这一列。
3.添加序号
由于我们的数据是要存进数据库的,所以在这里我添加了序号这一列,给我们的数据进行编号,以便于后期我们对数据的分析。此外,为了方便后续的工作,我在这里将文件另存为csv格式,需要注意的是:在保存类型中我们选择CSV UTF-8(逗号分隔)。
经过上述几个步骤后,我们最终可以得到一个经过数据预处理的csv文件,如下图所示。

大数据分析
1.对CSV文件进行预处理生成无标题文本文件,将爬虫大作业产生的csv文件上传到HDFS
首先,我们需要在本地中创建一个/usr/local/bigdatacase/dataset文件夹,具体的步骤为:
① cd /usr/local
② sudo mkdir bigdatacase
③ cd bigdatacase/
④ sudo mkdir dataset
⑤ cd dataset/
如下图所示:

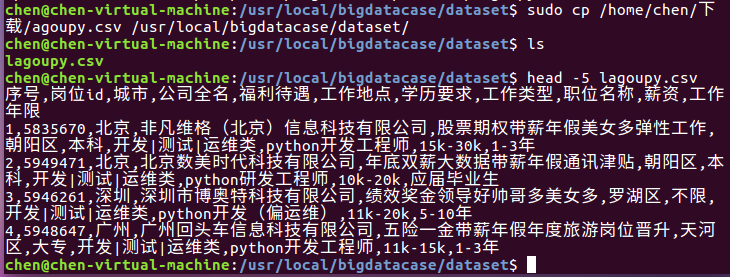
其次,我们把lagoupy.csv文件放到下载这个文件夹中,并使用命令把lagoupy.csv文件拷贝到我们刚刚所创建的文件夹中,具体步骤如下:
① sudo cp /home/chen/下载/lagoupy.csv /usr/local/bigdatacase/dataset/ #把lagoupy.csv文件拷到刚刚所创建的文件夹中
② head -5 lagoupy.csv #查看这个文件的前五行
如下图所示:
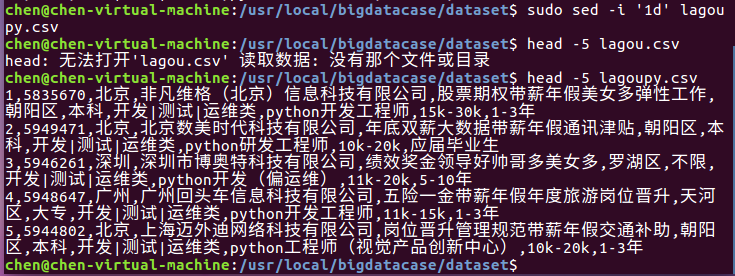
对CSV文件进行预处理生成无标题文本文件,步骤如下:
① sudo sed -i '1d' lagoupy.csv #删除第一行记录
② head -5 lagoupy.csv #查看前五行记录
如下图所示:
接着,启动hadoop,步骤如下:
① start-all.sh #启动hadoop
② jps #查看hadoop是否启动成功
如下图所示:

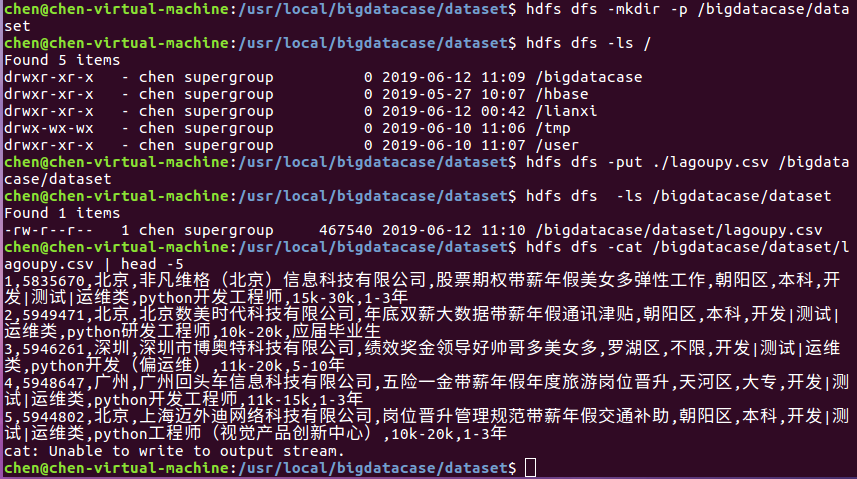
最后,我们把本地的文件上传至HDFS中,步骤如下:
① hdfs dfs -mkdir -p /bigdatacase/dataset #在hdfs上新建/bigdatacase/dataset
② hdfs dfs -ls /
③ hdfs dfs -put ./lagoupy.csv /bigdatacase/dataset #把本地文件lagoupy.csv上传至hdfs中
④ hdfs dfs -ls /bigdatacase/dataset #查看
⑤ hdfs dfs -cat /bigdatacase/dataset/lagoupy.csv | head -5 #查看hdfs中lagoupy.csv的前五行
如下图所示:
2.把hdfs中的文本文件最终导入到数据仓库Hive中
首先,启动hive,步骤如下:
① service mysql start #启动mysql数据库
② cd /usr/local/hive
③ ./bin/hive #启动hive
如下图所示:

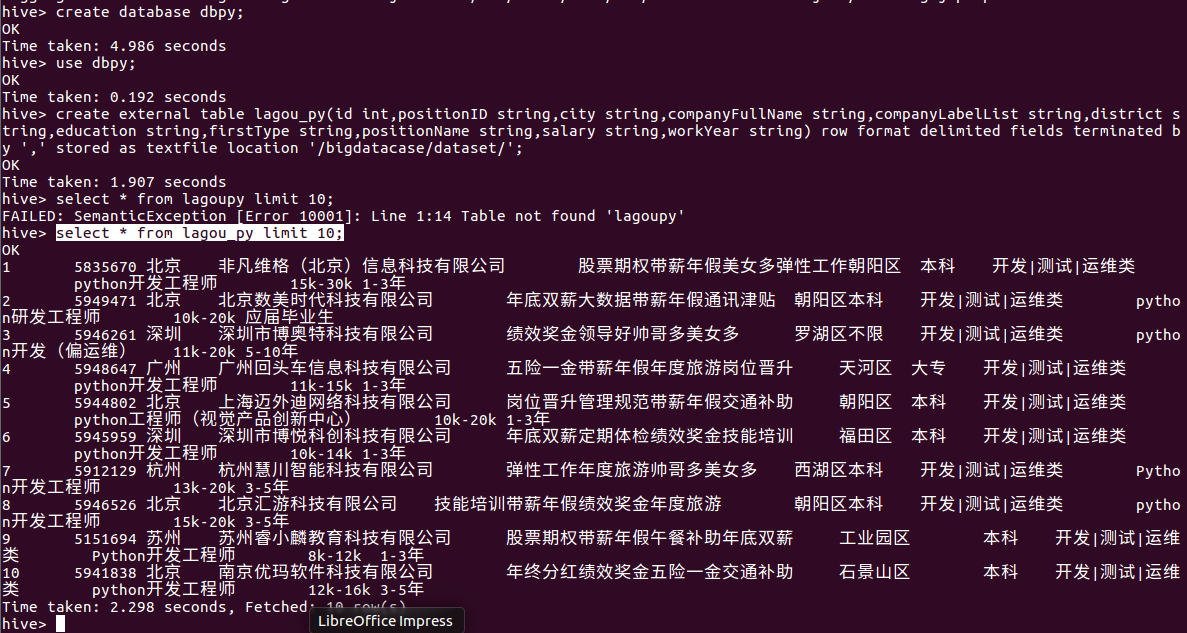
其次,把hdfs中的文本文件最终导入到数据仓库Hive中,并在Hive中查看并分析数据,具体步骤如下:
① create database dbpy; -- 创建数据库dbpy
② use dbpy;
③ create external table lagou_py(id int,positionID string,city string,companyFullName string,companyLabelList string,district string,education string,firstType string,positionName string,salary string,workYear string) row format delimited fields terminated by ',' stored as textfile location '/bigdatacase/dataset/'; -- 创建表lagou_py并把hdfs中/bigdatacase/dataset/目录下的数据加载到表中
④ select * from lagou_py limit 10; -- 查看lagou_py中前10行的数据
如下图所示:
3.用Hive对爬虫大作业产生的进行数据分析(10条以上的查询分析)
① 查找城市分布情况
Select city,count(distinct positionID) as dis_pi from lagou_py group by city;
查询结果如下图所示,从图中我们可以发现北京、上海、深圳、杭州、广州这五个城市对python相关岗位招聘数居前五,说明这五个城市对python岗位的需求较多。

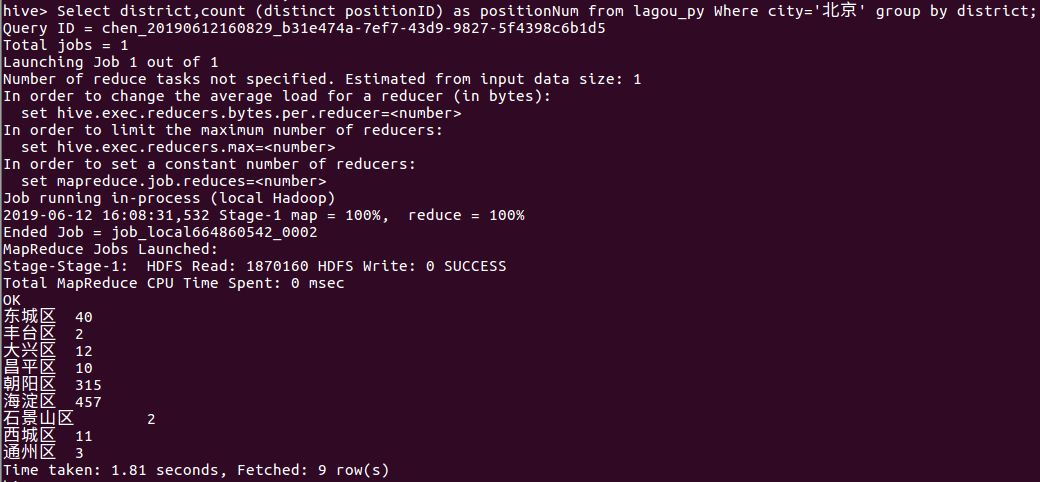
② 找出北京各个区的职位分布情况
Select district,count (distinct positionID) as positionNum from lagou_py Where city='北京' group by district;
由下图我们可以看出北京市海淀区和朝阳区对python相关岗位的需求较多,分别为457和315。
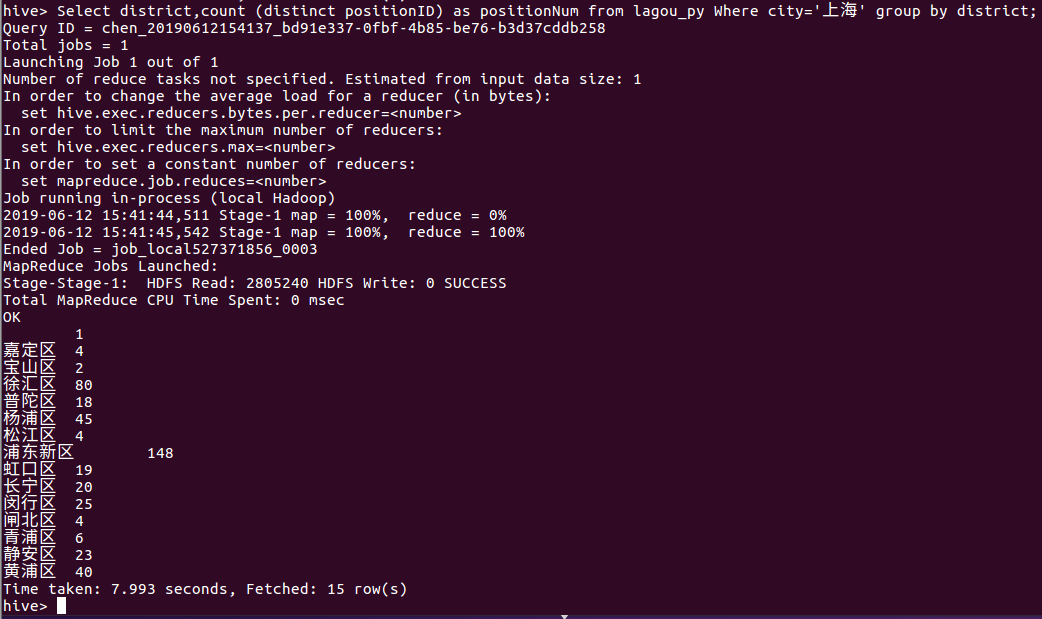
③ 找出上海各个区的职位分布情况
Select district,count (distinct positionID) as positionNum from lagou_py Where city='上海' group by district;
由下图我们可以看出上海的浦东新区、徐汇区、杨浦区、黄浦区这四个区对python相关岗位的需求较多。
④ 找出深圳各个区的职位分布情况
Select district,count (distinct positionID) as positionNum from lagou_py Where city='深圳' group by district;
由下图我们可以看出深圳的南山区、福田区这两个区对python相关岗位的需求较多,其中南山区以308个居首位。

⑤ 找出杭州各个区的职位分布情况
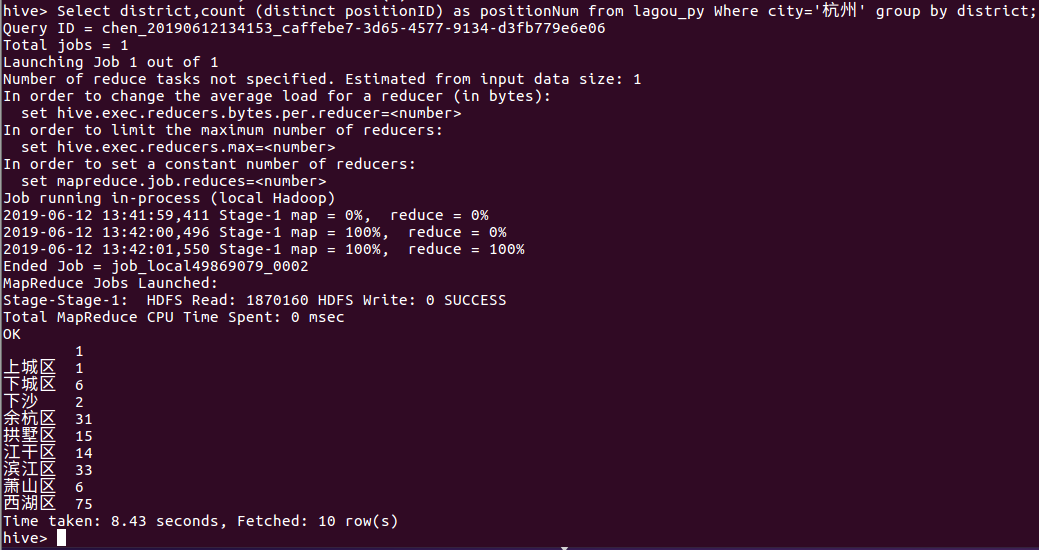
Select district,count (distinct positionID) as positionNum from lagou_py Where city='杭州' group by district;
由下图我们可以看出杭州的西湖区、滨江区、余杭区这三个区对python相关岗位的需求较多。
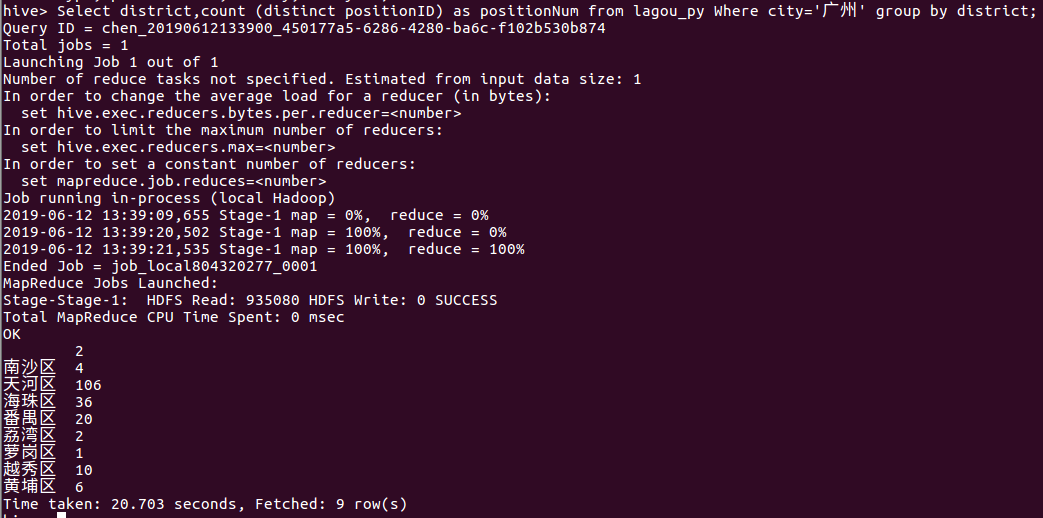
⑥ 找出广州各个区的职位分布情况
Select district,count (distinct positionID) as positionNum from lagou_py Where city='广州' group by district;
由下图我们可以看出广州的天河区、海珠区和番禺区这三个区对python相关岗位的需求较多,其余区对python相关岗位需求较少,其中天河区以106个居首位。
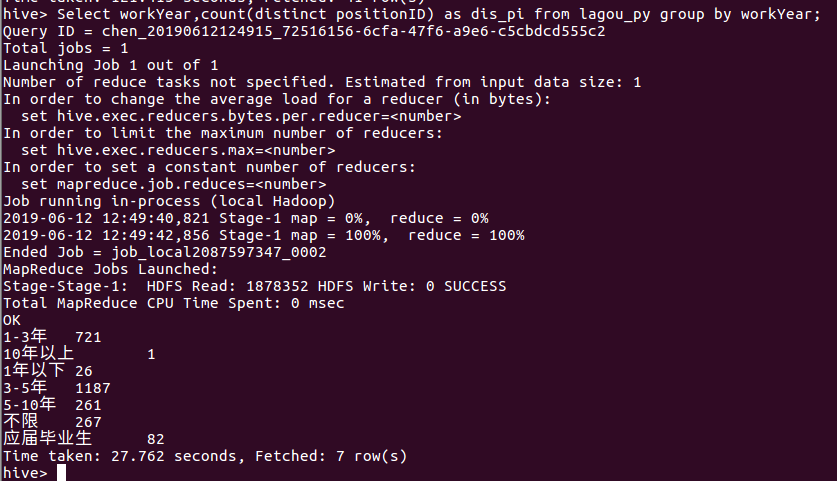
⑦ 查询python相关岗位对工作年限的要求
Select workYear,count(distinct positionID) as dis_pi from lagou_py group by workYear;
由下图我们可以看出,python相关岗位对工作年限的需求以3-5年和1-3年居多,分别为1187、721个。
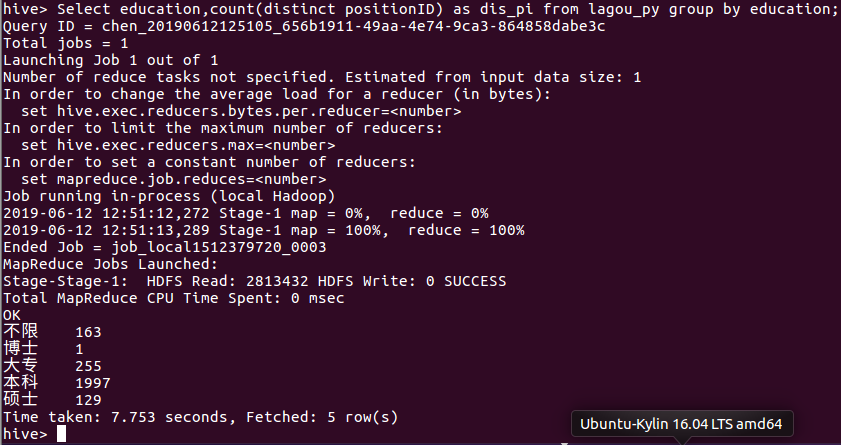
⑧ 查询python相关岗位对学历的要求
Select education,count(distinct positionID) as dis_pi from lagou_py group by education;
由下图我们看出,python相关岗位对学历的需求以本科和大专为主。
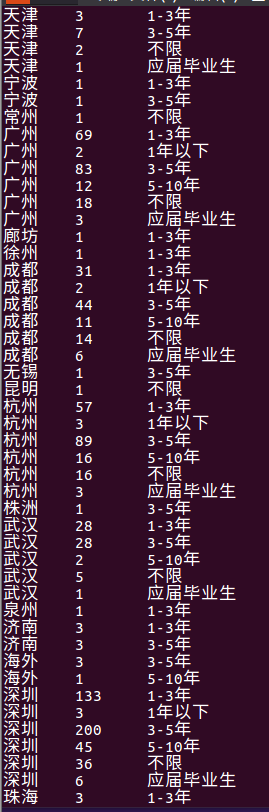
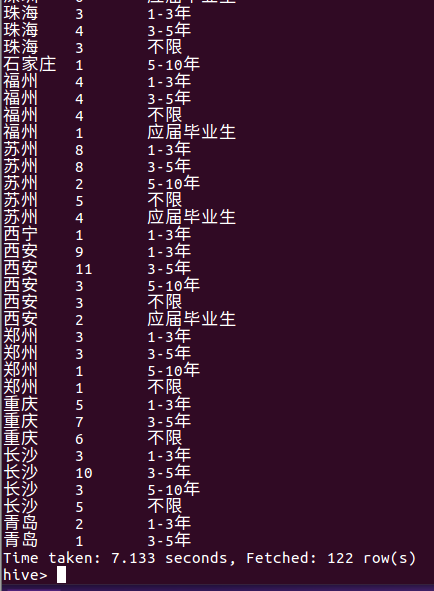
⑨ 统计每个城市不同工作年限的职位数量
Select city,count(distinct positionID) as dis_pi,workYear from lagou_py group by city,workYear;
这里我是按照城市和工作年限进行分组,统计结果如下三图所示,由下图可以看出各个城市对不同工作年限的职位数量。

⑩ 统计每个城市的职位数量和公司数量
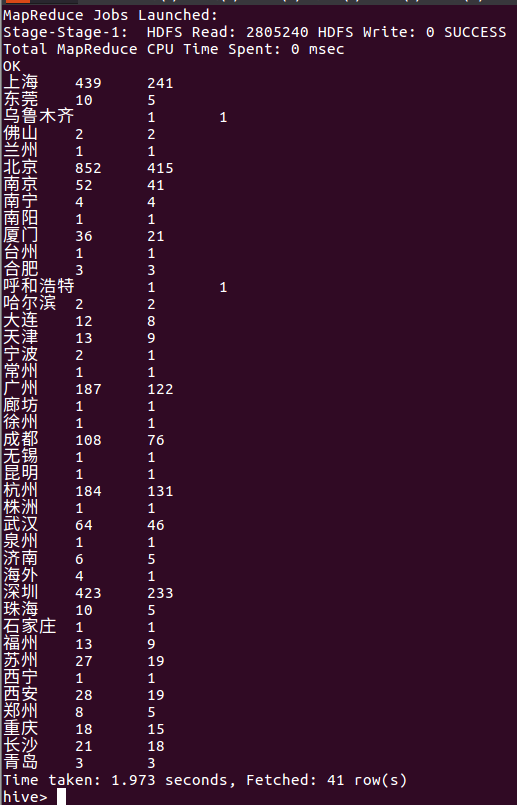
select city,count(positionID) as positionNum,count(distinct companyFullName) as compNum from lagou_py group by city;
下图是统计各个城市的职位数量和公司数量,其中第二列为职位数量,第三列为公司数量,由下图所示我们可以看出上海、深圳、北京这三个城市基本上是职位数量为公司数量的2倍。
⑪ 统计每个城市不同学历水平的职位数量
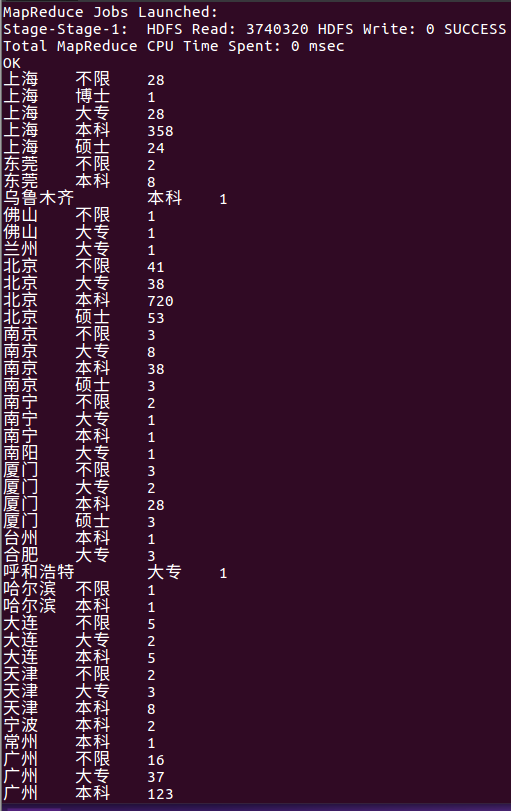
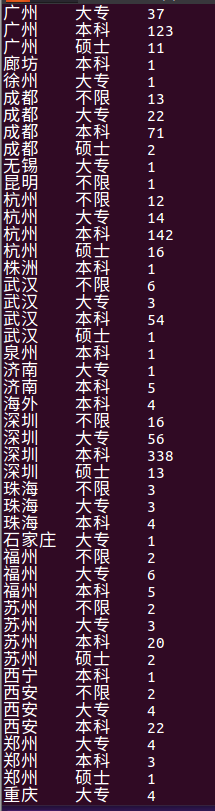
select city, education, count(positionID) as positionNum from lagou_py group by city, education;
由下图所示为每个城市不同学历水平的职位数量的统计结果,从统计结果中我们不难发现每个城市基本上对python相关岗位对学历基本上以本科为主。
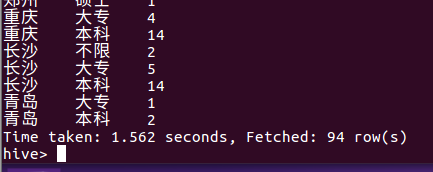
⑫ 只显示职位数量超过100个的城市的数量
select city, count(positionID) as positionNum from lagou_py group by city having positionNum > 100;
这里我们统计的是职位数量超过100的城市的数量,从统计结果我们可以看出职位数超百的城市只有上海、北京、成都、杭州、深圳这五个城市,其中以北京居多,由852个岗位。
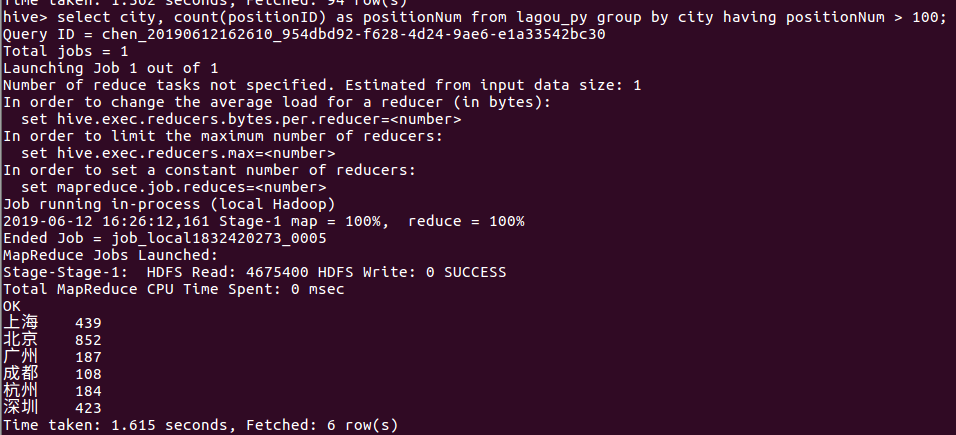
⑬ 找出与开发相关的职位数量大于50的城市
select city, count(positionID) as eComPositionNum from lagou_py where firstType like "%开发%" group by city having eComPositionNum > 50;
这里我们统计的是开发类型职位数大于50的城市的总职位数,从统计结果中我们可以发现上海、北京、南京、广州、成都、杭州、武汉、深圳这几个城市都是符合条件的,并且我们可以把统计结果与⑫的结果做对比,发现两者的统计结果相差很小,说明基本上python相关岗位需要的都是开发类型的人才。
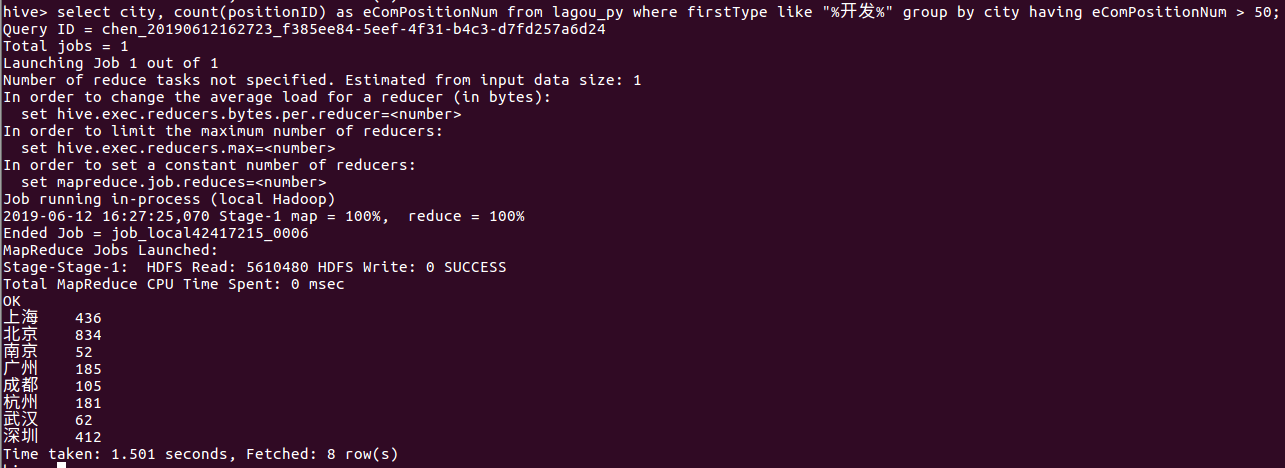
⑭ 筛选出开发职位数大于50的城市的总职位数
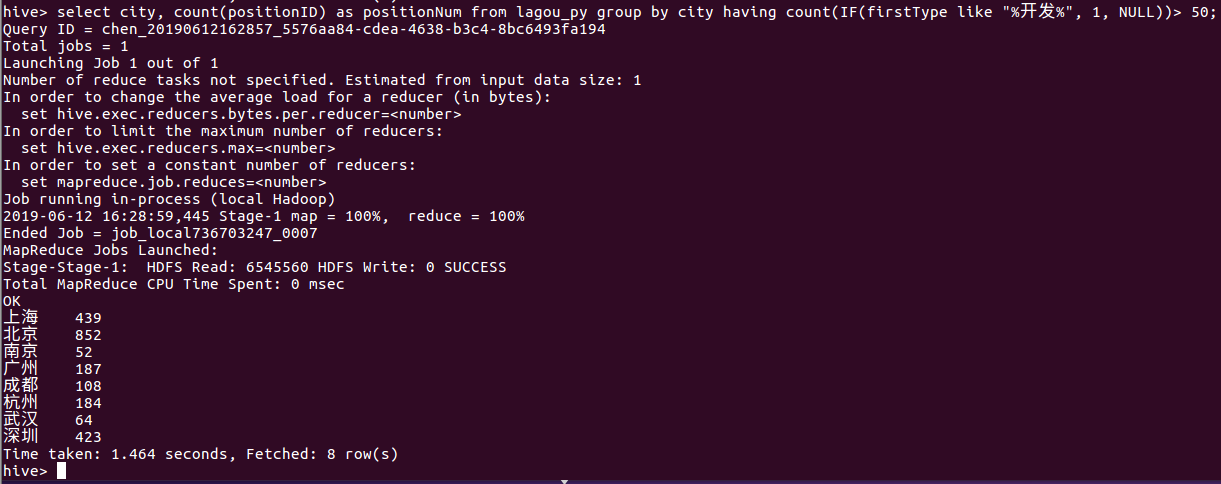
select city, count(positionID) as positionNum from lagou_py group by city having count(if(firstType like "%开发%", 1, NULL))> 50;
由统计结果我们可以发现北上广深这几个城市的职位数量占比最多。
⑮ 每个城市开发职位占总职位数的比例
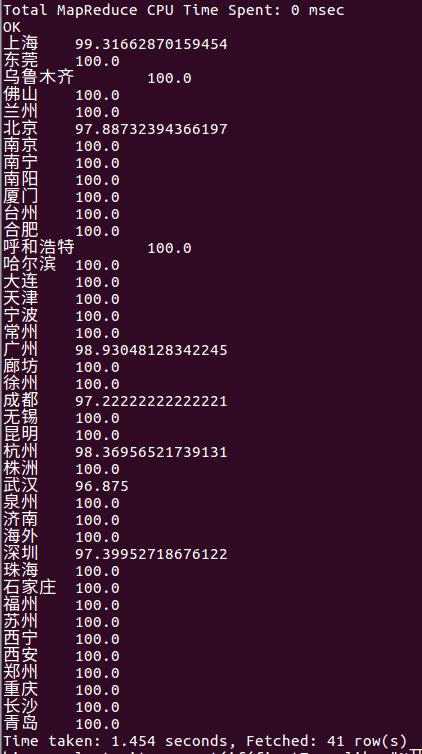
select city, count(if(firstType like "%开发%", 1,NULL))/count(1)*100 as eComPositionPercent from lagou_py group by city;
从统计结果我们可以发现基本上每个城市对python相关岗位的人才需求基本上都是开发类型,其他类型只占了其城市中很小的比例,可以忽略不计。
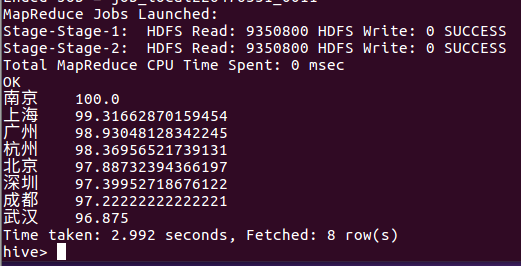
⑯ 每个城市开发职位占总职位数的比例,同时开发职位数大于50,排序
select city, count(if(firstType like "%开发%", 1,NULL))/count(1)*100 as eComPositionPercent from lagou_py group by city having count(if(firstType like "%开发%", 1, NULL)) > 50 order by eComPositionPercent desc;
下图所示可以看出开发职位数大于50的各个城市都是比较发达的几个城市——南京、上海、广州、杭州、北京、深圳、成都、武汉。
⑰ 列出开发职位数大于50的城市所包含的所有职位信息
select * from lagou_py where city in ( Select city from lagou_py group by city having count(if(firstType like "%开发%",1,NULL)) > 50);
下图所示是类型为开发的职位数大于50的城市所包含的所有职位的信息,由于统计结果较多,所以在这里只给出了前33条的职位信息。

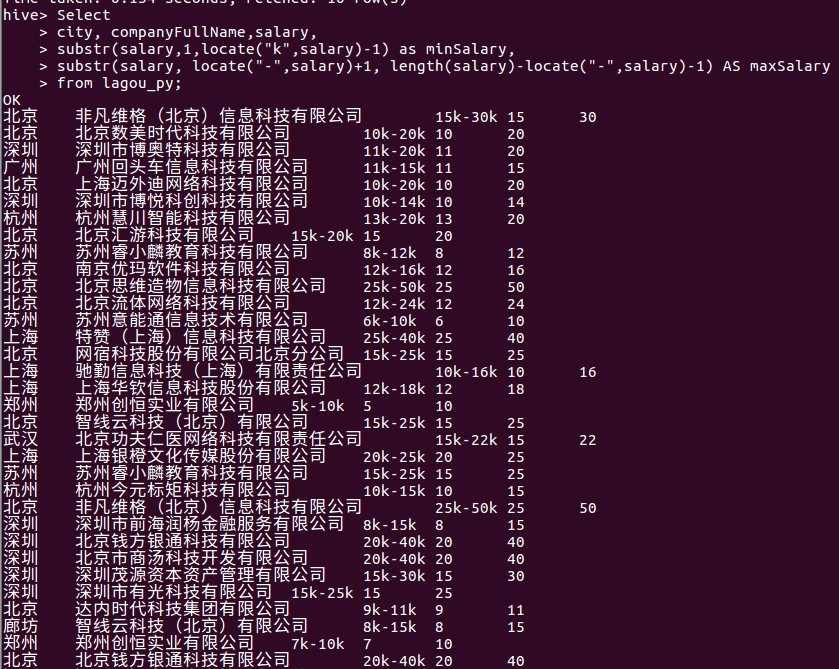
⑱ 拆分salary列,得到职位薪资的上、下限
Select city, companyFullName,salary, substr(salary,1,locate("k",salary)-1) as minSalary, substr(salary, locate("-",salary)+1, length(salary)-locate("-",salary)-1) AS maxSalary from lagou_py;
由于我们的工资这一列的数据基本上都是例如15k-30k这种类型的,所以在这里我们对工资这一列进行拆分,可以得到各个公司python相关岗位的工资的上下限,统计的部分结果如下图所示,由于统计结果较多,所以这里只给出统计的部分结果。