前言
我们都知道,在大数据领域,Hive的出现帮我降低了许多使用Hadoop书写方式的学习成本.使用用户可以使用类似Sql的语法规则写明查询语句,从hive表数据中查询目标数据.最为重要的是这些sql语句会最终转化为map reduce作业进行处理.这也是Hive最强大的地方.可以简单的理解为Hive就是依托在Hadoop上的1个壳.但是这里有一点点小小的不同,不是每段hive查询sql语句与最后生成的job一一对应,如果你的这段sql是一个大sql,他在转化掉之后,会衍生出许多小job,这些小job是独立存在运行的,以不同的job名称进行区别,但是也会保留公共的job名称.所以一个问题来了,对于超级长的hive sql语句,我想查看到底是哪段子sql花费了我大量的执行时间,在JobHistory上只有每个子Job的运行时间,没有子Job对应的sql语句,一旦这个功能有了之后,就会帮助我们迅速的定位到问题所在.
Hive子Job中的Sql
OK,带着上述的目标,我们要想分析出到底哪段子sql所衍生的job运行时间更长,就要先知道这些sql到底在存在与哪里.在前面的描述中,已经提到了,Hive是依托于Hadoop,自然Hive提交的job信息也是保存在Hadoop的HDFS上的.在联想一下JobHistory中的各个文件类型.你应该会发现带有下面后缀的文件存在.
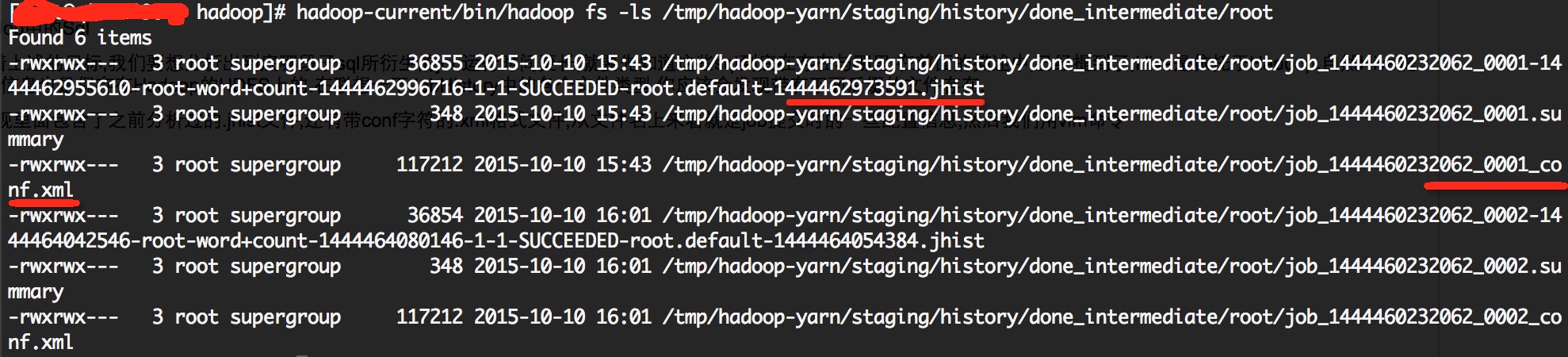
我们发现里面包含了之前分析过的.jhist文件,还有带conf字符的.xml格式文件,从文件名上来看就是job提交时的一些配置信息,然后我们用vim命令查阅conf.xml后缀的文件,看看里面是不是有我们想要的hive qury string 这样的属性
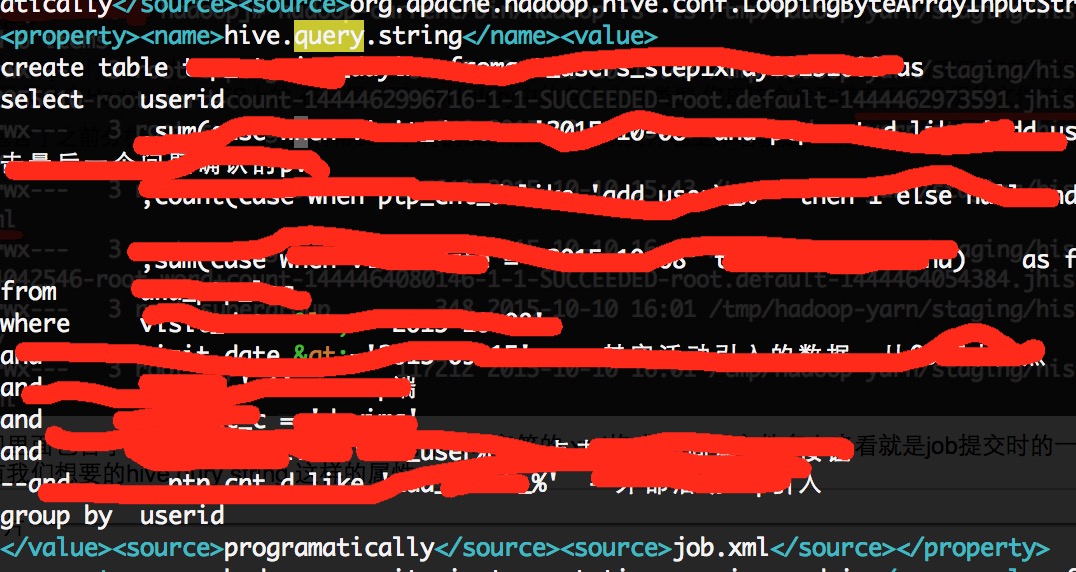
OK,目标算是找到了,这的确就是我们想要的属性.说明这样的信息的确是存在的,后面的操作就是怎么去解析这段有用的信息了.
程序工具分析Hive Sql Job
知道了目标数据源,我们能想到的最简单快速的方法就是逐行解析文件,做做文本匹配,筛选关键信息.这些代码谁都会写,首先要传入一个HDFS目录地址,这个是在JobHistory的存储目录上加上一个具体日期目录,这段解析程序在文章的末尾会加上.下面列举在调试分析程序时遇到的一些问题,这个还是比较有用的.
1.hive sql中的中文导致解析出现乱码
这个又是非常讨厌的java解析出现乱码的原因,因为考虑到sql中存在中文注释,而Hadoop在存中文的时候都是用utf8的编码方式,所以读出文件数据后进行一次转utf-8编码方式的处理,就是下面所示代码.
...
fileSystem = path.getFileSystem(new Configuration());
in = fileSystem.open(path);
InputStreamReader isr;
BufferedReader br;
isr = new InputStreamReader(in, "UTF-8");
br = new BufferedReader(isr);
while ((str = br.readLine()) != null) {
...2.单线程解析文件速度过慢
之前在测试环境中做文件解析看不出真实效果,文件一下解析就OK了,但是到真实环境中,多达几万个job文件,程序马上就吃不消了,算上解析文件,再把结果写入mysql,耗时达到60多分钟,后面改成了多线程的方式,后来开到10个线程去跑,速度才快了许多.
3.结果数据写入MySql过慢
后来处理速度是上去了,但是写入sql速度过慢,比如说,我有一次测试,开10个线程区解析,花了8分钟就解析好了几万个文件数据,但是插入数据库花了20分钟左右,而且量也就几万条语句.后来改成了批处理的方式,效果并没有什么大的改变,这个慢的问题具体并没有被解决掉,怀疑可能是因有些语句中存在超长的hive sql语句导致的.
下面是程序的主要分析代码,分为工具类代码,和解析线程类,代码全部链接再此处:https://github.com/linyiqun/yarn-jobhistory-crawler/tree/master/jobHiveSqlAnalyse
主工具代码
package org.apache.hadoop.mapreduce.v2.hs.tool.sqlanalyse;
import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.PrintStream;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.LinkedList;
import java.util.List;
import java.util.Map.Entry;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileContext;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.RemoteIterator;
import org.apache.hadoop.fs.UnsupportedFileSystemException;
import org.apache.hadoop.io.IOUtils;
public class HiveSqlAnalyseTool {
private int threadNum;
private String dirType;
private String jobHistoryPath;
private FileContext doneDirFc;
private Path doneDirPrefixPath;
private LinkedList<FileStatus> fileStatusList;
private HashMap<String, String[]> dataInfos;
private DbClient dbClient;
public HiveSqlAnalyseTool(String dirType, String jobHistoryPath,
int threadNum) {
this.threadNum = threadNum;
this.dirType = dirType;
this.jobHistoryPath = jobHistoryPath;
this.dataInfos = new HashMap<String, String[]>();
this.fileStatusList = new LinkedList<FileStatus>();
this.dbClient = new DbClient(BaseValues.DB_URL,
BaseValues.DB_USER_NAME, BaseValues.DB_PASSWORD,
BaseValues.DB_HIVE_SQL_STAT_TABLE_NAME);
try {
doneDirPrefixPath = FileContext.getFileContext(new Configuration())
.makeQualified(new Path(this.jobHistoryPath));
doneDirFc = FileContext.getFileContext(doneDirPrefixPath.toUri());
} catch (UnsupportedFileSystemException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IllegalArgumentException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
public void readJobInfoFiles() {
List<FileStatus> files;
files = new ArrayList<FileStatus>();
try {
files = scanDirectory(doneDirPrefixPath, doneDirFc, files);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
if (files != null) {
for (FileStatus fs : files) {
// parseFileInfo(fs);
}
System.out.println("files num is " + files.size());
System.out
.println("fileStatusList size is" + fileStatusList.size());
ParseThread[] threads;
threads = new ParseThread[threadNum];
for (int i = 0; i < threadNum; i++) {
System.out.println("thread " + i + "start run");
threads[i] = new ParseThread(this, fileStatusList, dataInfos);
threads[i].start();
}
for (int i = 0; i < threadNum; i++) {
System.out.println("thread " + i + "join run");
try {
if (threads[i] != null) {
threads[i].join();
}
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
} else {
System.out.println("files is null");
}
printStatDatas();
}
protected List<FileStatus> scanDirectory(Path path, FileContext fc,
List<FileStatus> jhStatusList) throws IOException {
path = fc.makeQualified(path);
System.out.println("dir path is " + path.getName());
try {
RemoteIterator<FileStatus> fileStatusIter = fc.listStatus(path);
while (fileStatusIter.hasNext()) {
FileStatus fileStatus = fileStatusIter.next();
Path filePath = fileStatus.getPath();
if (fileStatus.isFile()) {
jhStatusList.add(fileStatus);
fileStatusList.add(fileStatus);
} else if (fileStatus.isDirectory()) {
scanDirectory(filePath, fc, jhStatusList);
}
}
} catch (FileNotFoundException fe) {
System.out.println("Error while scanning directory " + path);
}
return jhStatusList;
}
private void parseFileInfo(FileStatus fs) {
String resultStr;
String str;
String username;
String fileType;
String jobId;
String jobName;
String hiveSql;
int startPos;
int endPos;
int hiveSqlFlag;
long launchTime;
long finishTime;
int mapTaskNum;
int reduceTaskNum;
String xmlNameFlag;
String launchTimeFlag;
String finishTimeFlag;
String launchMapFlag;
String launchReduceFlag;
Path path;
FileSystem fileSystem;
InputStream in;
resultStr = "";
fileType = "";
hiveSql = "";
jobId = "";
jobName = "";
username = "";
hiveSqlFlag = 0;
launchTime = 0;
finishTime = 0;
mapTaskNum = 0;
reduceTaskNum = 0;
xmlNameFlag = "<value>";
launchTimeFlag = ""launchTime":";
finishTimeFlag = ""finishTime":";
launchMapFlag = ""Launched map tasks"";
launchReduceFlag = ""Launched reduce tasks"";
path = fs.getPath();
str = path.getName();
if (str.endsWith(".xml")) {
fileType = "config";
endPos = str.lastIndexOf("_");
jobId = str.substring(0, endPos);
} else if (str.endsWith(".jhist")) {
fileType = "info";
endPos = str.indexOf("-");
jobId = str.substring(0, endPos);
} else {
return;
}
try {
fileSystem = path.getFileSystem(new Configuration());
in = fileSystem.open(path);
InputStreamReader isr;
BufferedReader br;
isr = new InputStreamReader(in, "UTF-8");
br = new BufferedReader(isr);
while ((str = br.readLine()) != null) {
if (str.contains("mapreduce.job.user.name")) {
startPos = str.indexOf(xmlNameFlag);
endPos = str.indexOf("</value>");
username = str.substring(startPos + xmlNameFlag.length(),
endPos);
} else if (str.contains("mapreduce.job.name")) {
startPos = str.indexOf(xmlNameFlag);
endPos = str.indexOf("</value>");
jobName = str.substring(startPos + xmlNameFlag.length(),
endPos);
} else if (str.contains("hive.query.string")) {
hiveSqlFlag = 1;
hiveSql = str;
} else if (hiveSqlFlag == 1) {
hiveSql += str;
if (str.contains("</value>")) {
startPos = hiveSql.indexOf(xmlNameFlag);
endPos = hiveSql.indexOf("</value>");
hiveSql = hiveSql.substring(
startPos + xmlNameFlag.length(), endPos);
hiveSqlFlag = 0;
}
} else if (str.startsWith("{"type":"JOB_INITED"")) {
startPos = str.indexOf(launchTimeFlag);
str = str.substring(startPos + launchTimeFlag.length());
endPos = str.indexOf(",");
launchTime = Long.parseLong(str.substring(0, endPos));
} else if (str.startsWith("{"type":"JOB_FINISHED"")) {
mapTaskNum = parseTaskNum(launchMapFlag, str);
reduceTaskNum = parseTaskNum(launchReduceFlag, str);
startPos = str.indexOf(finishTimeFlag);
str = str.substring(startPos + finishTimeFlag.length());
endPos = str.indexOf(",");
finishTime = Long.parseLong(str.substring(0, endPos));
}
}
System.out.println("jobId is " + jobId);
System.out.println("jobName is " + jobName);
System.out.println("username is " + username);
System.out.println("map task num is " + mapTaskNum);
System.out.println("reduce task num is " + reduceTaskNum);
System.out.println("launchTime is " + launchTime);
System.out.println("finishTime is " + finishTime);
System.out.println("hive query sql is " + hiveSql);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
if (fileType.equals("config")) {
insertConfParseData(jobId, jobName, username, hiveSql);
} else if (fileType.equals("info")) {
insertJobInfoParseData(jobId, launchTime, finishTime, mapTaskNum,
reduceTaskNum);
}
}
private void insertConfParseData(String jobId, String jobName,
String username, String sql) {
String[] array;
if (dataInfos.containsKey(jobId)) {
array = dataInfos.get(jobId);
} else {
array = new String[BaseValues.DB_COLUMN_HIVE_SQL_LEN];
}
array[BaseValues.DB_COLUMN_HIVE_SQL_JOBID] = jobId;
array[BaseValues.DB_COLUMN_HIVE_SQL_JOBNAME] = jobName;
array[BaseValues.DB_COLUMN_HIVE_SQL_USERNAME] = username;
array[BaseValues.DB_COLUMN_HIVE_SQL_HIVE_SQL] = sql;
dataInfos.put(jobId, array);
}
private void insertJobInfoParseData(String jobId, long launchTime,
long finishedTime, int mapTaskNum, int reduceTaskNum) {
String[] array;
if (dataInfos.containsKey(jobId)) {
array = dataInfos.get(jobId);
} else {
array = new String[BaseValues.DB_COLUMN_HIVE_SQL_LEN];
}
array[BaseValues.DB_COLUMN_HIVE_SQL_JOBID] = jobId;
array[BaseValues.DB_COLUMN_HIVE_SQL_START_TIME] = String
.valueOf(launchTime);
array[BaseValues.DB_COLUMN_HIVE_SQL_FINISH_TIME] = String
.valueOf(finishedTime);
array[BaseValues.DB_COLUMN_HIVE_SQL_MAP_TASK_NUM] = String
.valueOf(mapTaskNum);
array[BaseValues.DB_COLUMN_HIVE_SQL_REDUCE_TASK_NUM] = String
.valueOf(reduceTaskNum);
dataInfos.put(jobId, array);
}
private int parseTaskNum(String flag, String jobStr) {
int taskNum;
int startPos;
int endPos;
String tmpStr;
taskNum = 0;
tmpStr = jobStr;
startPos = tmpStr.indexOf(flag);
if (startPos == -1) {
return 0;
}
tmpStr = tmpStr.substring(startPos + flag.length());
endPos = tmpStr.indexOf("}");
tmpStr = tmpStr.substring(0, endPos);
taskNum = Integer.parseInt(tmpStr.split(":")[1]);
return taskNum;
}
private void printStatDatas() {
String jobId;
String jobInfo;
String[] infos;
if (dbClient != null) {
dbClient.createConnection();
}
if (dataInfos != null) {
System.out.println("map data size is" + dataInfos.size());
if (dbClient != null && dirType.equals("dateTimeDir")) {
dbClient.insertDataBatch(dataInfos);
}
}
/*for (Entry<String, String[]> entry : this.dataInfos.entrySet()) {
jobId = entry.getKey();
infos = entry.getValue();
jobInfo = String
.format("jobId is %s, jobName:%s, usrname:%s, launchTime:%s, finishTime:%s, mapTaskNum:%s, reduceTaskNum:%s, querySql:%s",
jobId, infos[1], infos[2], infos[3], infos[4],
infos[5], infos[6], infos[7]);
// System.out.println("job detail info " + jobInfo);
if (dbClient != null && dirType.equals("dateTimeDir")) {
dbClient.insertHiveSqlStatData(infos);
}
}*/
if (dbClient != null) {
dbClient.closeConnection();
}
}
public synchronized FileStatus getOneFile() {
FileStatus fs;
fs = null;
if (fileStatusList != null & fileStatusList.size() > 0) {
fs = fileStatusList.poll();
}
return fs;
}
public synchronized void addDataToMap(String jobId, String[] values) {
if (dataInfos != null) {
dataInfos.put(jobId, values);
}
}
}
解析线程代码ParseThread.java:
package org.apache.hadoop.mapreduce.v2.hs.tool.sqlanalyse;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.util.HashMap;
import java.util.LinkedList;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class ParseThread extends Thread{
private HiveSqlAnalyseTool tool;
private LinkedList<FileStatus> fileStatus;
private HashMap<String, String[]> dataInfos;
public ParseThread(HiveSqlAnalyseTool tool, LinkedList<FileStatus> fileStatus, HashMap<String, String[]> dataInfos){
this.tool = tool;
this.fileStatus = fileStatus;
this.dataInfos = dataInfos;
}
@Override
public void run() {
FileStatus fs;
while(fileStatus != null && !fileStatus.isEmpty()){
fs = tool.getOneFile();
parseFileInfo(fs);
}
super.run();
}
private void parseFileInfo(FileStatus fs) {
String str;
String username;
String fileType;
String jobId;
String jobName;
String hiveSql;
int startPos;
int endPos;
int hiveSqlFlag;
long launchTime;
long finishTime;
int mapTaskNum;
int reduceTaskNum;
String xmlNameFlag;
String launchTimeFlag;
String finishTimeFlag;
String launchMapFlag;
String launchReduceFlag;
Path path;
FileSystem fileSystem;
InputStream in;
fileType = "";
hiveSql = "";
jobId = "";
jobName = "";
username = "";
hiveSqlFlag = 0;
launchTime = 0;
finishTime = 0;
mapTaskNum = 0;
reduceTaskNum = 0;
xmlNameFlag = "<value>";
launchTimeFlag = ""launchTime":";
finishTimeFlag = ""finishTime":";
launchMapFlag = ""Launched map tasks"";
launchReduceFlag = ""Launched reduce tasks"";
path = fs.getPath();
str = path.getName();
if (str.endsWith(".xml")) {
fileType = "config";
endPos = str.lastIndexOf("_");
jobId = str.substring(0, endPos);
} else if (str.endsWith(".jhist")) {
fileType = "info";
endPos = str.indexOf("-");
jobId = str.substring(0, endPos);
}else{
return;
}
try {
fileSystem = path.getFileSystem(new Configuration());
in = fileSystem.open(path);
InputStreamReader isr;
BufferedReader br;
isr = new InputStreamReader(in, "UTF-8");
br = new BufferedReader(isr);
while ((str = br.readLine()) != null) {
if (str.contains("mapreduce.job.user.name")) {
startPos = str.indexOf(xmlNameFlag);
endPos = str.indexOf("</value>");
username = str.substring(startPos + xmlNameFlag.length(),
endPos);
} else if (str.contains("mapreduce.job.name")) {
startPos = str.indexOf(xmlNameFlag);
endPos = str.indexOf("</value>");
jobName = str.substring(startPos + xmlNameFlag.length(),
endPos);
} else if (str.contains("hive.query.string")) {
hiveSqlFlag = 1;
hiveSql = str;
} else if (hiveSqlFlag == 1) {
hiveSql += str;
if (str.contains("</value>")) {
startPos = hiveSql.indexOf(xmlNameFlag);
endPos = hiveSql.indexOf("</value>");
hiveSql = hiveSql.substring(
startPos + xmlNameFlag.length(), endPos);
hiveSqlFlag = 0;
}
} else if (str.startsWith("{"type":"JOB_INITED"")) {
startPos = str.indexOf(launchTimeFlag);
str = str.substring(startPos + launchTimeFlag.length());
endPos = str.indexOf(",");
launchTime = Long.parseLong(str.substring(0, endPos));
} else if (str.startsWith("{"type":"JOB_FINISHED"")) {
mapTaskNum = parseTaskNum(launchMapFlag, str);
reduceTaskNum = parseTaskNum(launchReduceFlag, str);
startPos = str.indexOf(finishTimeFlag);
str = str.substring(startPos + finishTimeFlag.length());
endPos = str.indexOf(",");
finishTime = Long.parseLong(str.substring(0, endPos));
}
}
/*System.out.println("jobId is " + jobId);
System.out.println("jobName is " + jobName);
System.out.println("username is " + username);
System.out.println("map task num is " + mapTaskNum);
System.out.println("reduce task num is " + reduceTaskNum);
System.out.println("launchTime is " + launchTime);
System.out.println("finishTime is " + finishTime);
System.out.println("hive query sql is " + hiveSql);*/
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
if (fileType.equals("config")) {
insertConfParseData(jobId, jobName, username, hiveSql);
} else if (fileType.equals("info")) {
insertJobInfoParseData(jobId, launchTime, finishTime, mapTaskNum,
reduceTaskNum);
}
}
private void insertConfParseData(String jobId, String jobName,
String username, String sql) {
String[] array;
if (dataInfos.containsKey(jobId)) {
array = dataInfos.get(jobId);
} else {
array = new String[BaseValues.DB_COLUMN_HIVE_SQL_LEN];
}
array[BaseValues.DB_COLUMN_HIVE_SQL_JOBID] = jobId;
array[BaseValues.DB_COLUMN_HIVE_SQL_JOBNAME] = jobName;
array[BaseValues.DB_COLUMN_HIVE_SQL_USERNAME] = username;
array[BaseValues.DB_COLUMN_HIVE_SQL_HIVE_SQL] = sql;
tool.addDataToMap(jobId, array);
}
private void insertJobInfoParseData(String jobId, long launchTime,
long finishedTime, int mapTaskNum, int reduceTaskNum) {
String[] array;
if (dataInfos.containsKey(jobId)) {
array = dataInfos.get(jobId);
} else {
array = new String[BaseValues.DB_COLUMN_HIVE_SQL_LEN];
}
array[BaseValues.DB_COLUMN_HIVE_SQL_JOBID] = jobId;
array[BaseValues.DB_COLUMN_HIVE_SQL_START_TIME] = String
.valueOf(launchTime);
array[BaseValues.DB_COLUMN_HIVE_SQL_FINISH_TIME] = String
.valueOf(finishedTime);
array[BaseValues.DB_COLUMN_HIVE_SQL_MAP_TASK_NUM] = String
.valueOf(mapTaskNum);
array[BaseValues.DB_COLUMN_HIVE_SQL_REDUCE_TASK_NUM] = String
.valueOf(reduceTaskNum);
tool.addDataToMap(jobId, array);
}
private int parseTaskNum(String flag, String jobStr) {
int taskNum;
int startPos;
int endPos;
String tmpStr;
taskNum = 0;
tmpStr = jobStr;
startPos = tmpStr.indexOf(flag);
if(startPos == -1){
return 0;
}
tmpStr = tmpStr.substring(startPos + flag.length());
endPos = tmpStr.indexOf("}");
tmpStr = tmpStr.substring(0, endPos);
taskNum = Integer.parseInt(tmpStr.split(":")[1]);
return taskNum;
}
}