昨天经过几个小时的学习,把MapReduce的第一个阶段的过程学习了一下,也就是最最开始的时候从文件中的Data到key-value的映射,也就是InputFormat的过程。虽说过程不是很难,但是也存在很多细节的。也很少会有人对此做比较细腻的研究,学习。今天,就让我来为大家剖析一下这段代码的原理。我还为此花了一点时间做了几张结构图,便于大家理解。在这里先声明一下,我研究的MapReduce主要研究的是旧版的API,也就是mapred包下的。
InputFormat最最原始的形式就是一个接口。后面出现的各种Format都是他的衍生类。结构如下,只包含最重要的2个方法:
public interface InputFormat<K, V> {
/**
* Logically split the set of input files for the job.
*
* <p>Each {@link InputSplit} is then assigned to an individual {@link Mapper}
* for processing.</p>
*
* <p><i>Note</i>: The split is a <i>logical</i> split of the inputs and the
* input files are not physically split into chunks. For e.g. a split could
* be <i><input-file-path, start, offset></i> tuple.
*
* @param job job configuration.
* @param numSplits the desired number of splits, a hint.
* @return an array of {@link InputSplit}s for the job.
*/
InputSplit[] getSplits(JobConf job, int numSplits) throws IOException;
/**
* Get the {@link RecordReader} for the given {@link InputSplit}.
*
* <p>It is the responsibility of the <code>RecordReader</code> to respect
* record boundaries while processing the logical split to present a
* record-oriented view to the individual task.</p>
*
* @param split the {@link InputSplit}
* @param job the job that this split belongs to
* @return a {@link RecordReader}
*/
RecordReader<K, V> getRecordReader(InputSplit split,
JobConf job,
Reporter reporter) throws IOException;
}public abstract class FileInputFormat<K, V> implements InputFormat<K, V>public InputSplit[] getSplits(JobConf job, int numSplits)public interface InputSplit extends Writable {
/**
* Get the total number of bytes in the data of the <code>InputSplit</code>.
*
* @return the number of bytes in the input split.
* @throws IOException
*/
long getLength() throws IOException;
/**
* Get the list of hostnames where the input split is located.
*
* @return list of hostnames where data of the <code>InputSplit</code> is
* located as an array of <code>String</code>s.
* @throws IOException
*/
String[] getLocations() throws IOException;
}public class FileStatus implements Writable, Comparable {
private Path path;
private long length;
private boolean isdir;
private short block_replication;
private long blocksize;
private long modification_time;
private long access_time;
private FsPermission permission;
private String owner;
private String group;看到这里你估计会有点晕了,下面是我做的一张小小类图关系:
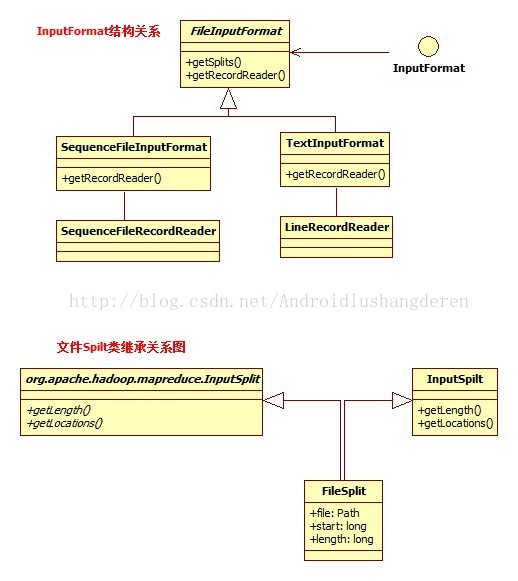
可以看到,FileSpilt为了兼容新老版本,继承了新的抽象类InputSpilt,同时附上旧的接口形式的InputSpilt。下面我们看看里面的getspilt核心过程:
/** Splits files returned by {@link #listStatus(JobConf)} when
* they're too big.*/
@SuppressWarnings("deprecation")
public InputSplit[] getSplits(JobConf job, int numSplits)
throws IOException {
//获取所有的状态文件
FileStatus[] files = listStatus(job);
// Save the number of input files in the job-conf
//在job-cof中保存文件的数量
job.setLong(NUM_INPUT_FILES, files.length);
long totalSize = 0;
// compute total size,计算文件总的大小
for (FileStatus file: files) { // check we have valid files
if (file.isDir()) {
//如果是目录不是纯文件的直接抛异常
throw new IOException("Not a file: "+ file.getPath());
}
totalSize += file.getLen();
}
//用户期待的划分大小,总大小除以spilt划分数目
long goalSize = totalSize / (numSplits == 0 ? 1 : numSplits);
//获取系统的划分最小值
long minSize = Math.max(job.getLong("mapred.min.split.size", 1),
minSplitSize);
// generate splits
//创建numSplits个FileSpilt文件划分量
ArrayList<FileSplit> splits = new ArrayList<FileSplit>(numSplits);
NetworkTopology clusterMap = new NetworkTopology();
for (FileStatus file: files) {
Path path = file.getPath();
FileSystem fs = path.getFileSystem(job);
long length = file.getLen();
//获取此文件的block的位置列表
BlockLocation[] blkLocations = fs.getFileBlockLocations(file, 0, length);
//如果文件系统可划分
if ((length != 0) && isSplitable(fs, path)) {
//计算此文件的总的block块的大小
long blockSize = file.getBlockSize();
//根据期待大小,最小大小,得出最终的split分片大小
long splitSize = computeSplitSize(goalSize, minSize, blockSize);
long bytesRemaining = length;
//如果剩余待划分字节倍数为划分大小超过1.1的划分比例,则进行拆分
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
//获取提供数据的splitHost位置
String[] splitHosts = getSplitHosts(blkLocations,
length-bytesRemaining, splitSize, clusterMap);
//添加FileSplit
splits.add(new FileSplit(path, length-bytesRemaining, splitSize,
splitHosts));
//数量减少splitSize大小
bytesRemaining -= splitSize;
}
if (bytesRemaining != 0) {
//添加刚刚剩下的没划分完的部分,此时bytesRemaining已经小于splitSize的1.1倍了
splits.add(new FileSplit(path, length-bytesRemaining, bytesRemaining,
blkLocations[blkLocations.length-1].getHosts()));
}
} else if (length != 0) {
//不划分,直接添加Spilt
String[] splitHosts = getSplitHosts(blkLocations,0,length,clusterMap);
splits.add(new FileSplit(path, 0, length, splitHosts));
} else {
//Create empty hosts array for zero length files
splits.add(new FileSplit(path, 0, length, new String[0]));
}
}
//最后返回FileSplit数组
LOG.debug("Total # of splits: " + splits.size());
return splits.toArray(new FileSplit[splits.size()]);
}
protected long computeSplitSize(long goalSize, long minSize,
long blockSize) {
return Math.max(minSize, Math.min(goalSize, blockSize));
}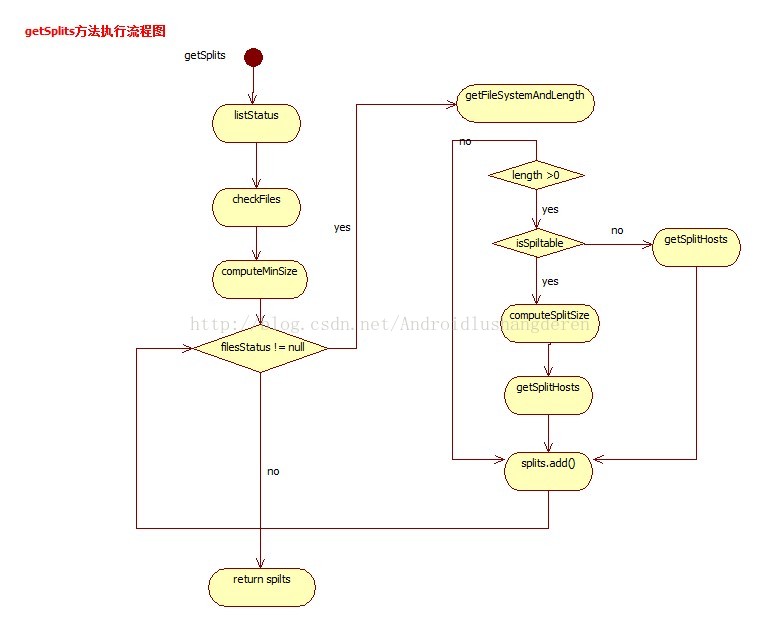
3种情况3中年执行流程。
处理完getSpilt方法然后,也就是说已经把数据从文件中转划到InputSpilt中了,接下来就是给RecordRead去取出里面的一条条的记录了。当然这在FileInputFormat是抽象方法,必须由子类实现的,我在这里挑出了2个典型的子类SequenceFileInputFormat,和TextInputFormat。他们的实现RecordRead方法如下:
public RecordReader<K, V> getRecordReader(InputSplit split,
JobConf job, Reporter reporter)
throws IOException {
reporter.setStatus(split.toString());
return new SequenceFileRecordReader<K, V>(job, (FileSplit) split);
}public RecordReader<LongWritable, Text> getRecordReader(
InputSplit genericSplit, JobConf job,
Reporter reporter)
throws IOException {
reporter.setStatus(genericSplit.toString());
return new LineRecordReader(job, (FileSplit) genericSplit);
}可以看到里面的区别就在于LineRecordReader和SequenceFileRecordReader的不同了,这也就表明2种方式对应于数据的读取方式可能会不一样,继续往里深入看:
/** An {@link RecordReader} for {@link SequenceFile}s. */
public class SequenceFileRecordReader<K, V> implements RecordReader<K, V> {
private SequenceFile.Reader in;
private long start;
private long end;
private boolean more = true;
protected Configuration conf;
public SequenceFileRecordReader(Configuration conf, FileSplit split)
throws IOException {
Path path = split.getPath();
FileSystem fs = path.getFileSystem(conf);
//从文件系统中读取数据输入流
this.in = new SequenceFile.Reader(fs, path, conf);
this.end = split.getStart() + split.getLength();
this.conf = conf;
if (split.getStart() > in.getPosition())
in.sync(split.getStart()); // sync to start
this.start = in.getPosition();
more = start < end;
}
......
/**
* 获取下一个键值对
*/
public synchronized boolean next(K key, V value) throws IOException {
//判断还有无下一条记录
if (!more) return false;
long pos = in.getPosition();
boolean remaining = (in.next(key) != null);
if (remaining) {
getCurrentValue(value);
}
if (pos >= end && in.syncSeen()) {
more = false;
} else {
more = remaining;
}
return more;
}/**
* Treats keys as offset in file and value as line.
*/
public class LineRecordReader implements RecordReader<LongWritable, Text> {
private static final Log LOG
= LogFactory.getLog(LineRecordReader.class.getName());
private CompressionCodecFactory compressionCodecs = null;
private long start;
private long pos;
private long end;
private LineReader in;
int maxLineLength;
....
/** Read a line. */
public synchronized boolean next(LongWritable key, Text value)
throws IOException {
while (pos < end) {
//设置key
key.set(pos);
//根据位置一行一行读取,设置value
int newSize = in.readLine(value, maxLineLength,
Math.max((int)Math.min(Integer.MAX_VALUE, end-pos),
maxLineLength));
if (newSize == 0) {
return false;
}
pos += newSize;
if (newSize < maxLineLength) {
return true;
}
// line too long. try again
LOG.info("Skipped line of size " + newSize + " at pos " + (pos - newSize));
}
return false;
}
InputFormat的整个流程其实我忽略了很多细节。大体流程如上述所说。